
導讀:本文內容從文字(資料)挖掘的角度去“探索”全唐詩,挑戰一些不同場景下(現代漢語和古漢語)文字處理和分析的異同點,錘煉分析技能;但更想做的是,結合資料之美和詩歌之雅,用跨界思維去發現一些有趣的東西。
近些年來,弘揚中華傳統文化的現象級綜藝節目不斷湧現,如《中國漢字聽寫大會》、《中國成語大會》、《中國謎語大會》、《中國詩詞大會》等,其背後的社會成因,在於人們對中國文化中最精緻文字的膜拜心理,雖然浸淫於層出不窮的網路語彙,時時面臨“語言荒漠”的窘境,仍心嚮往之。
上述節目中,筆者最感興趣的還是《中國詩詞大會》——透過對詩詞知識的比拼及賞析,帶動全民重溫那些曾經學過的古詩詞,分享詩詞之美,感受詩詞之趣,從古人的智慧和情懷中汲取營養,涵養心靈。
由於在新浪微輿情從事的是語意分析產品方面的工作,平時用到很多文字挖掘的方法。所以,筆者想從文字(資料)挖掘的角度去“探索”全唐詩,挑戰一些不同場景下(現代漢語和古漢語)文字處理和分析的異同點,錘煉自己的分析技能;但更想做的是,結合資料之美和詩歌之雅,用跨界思維去發現一些有趣的東西。
在這裡,筆者分析的語料是《全唐詩》,它編校於清康熙四十四年(1705年),得詩四萬八千九百餘首。
接下來,筆者將使用多種文字挖掘方法,來分析《全唐詩》。以下是本文的行文脈絡:

對於現代漢語的分詞,開源/免費的解決方案或工具很多,開源的解決方案如Jieba、HanLp、StanfordNLP和IKAnalyzer等,“傻瓜式”的免費操作工具的也有新浪微輿情的文字挖掘工具,如果直接採用這些現代漢語分詞工具對古詩詞進行分詞,結果會是這樣的:
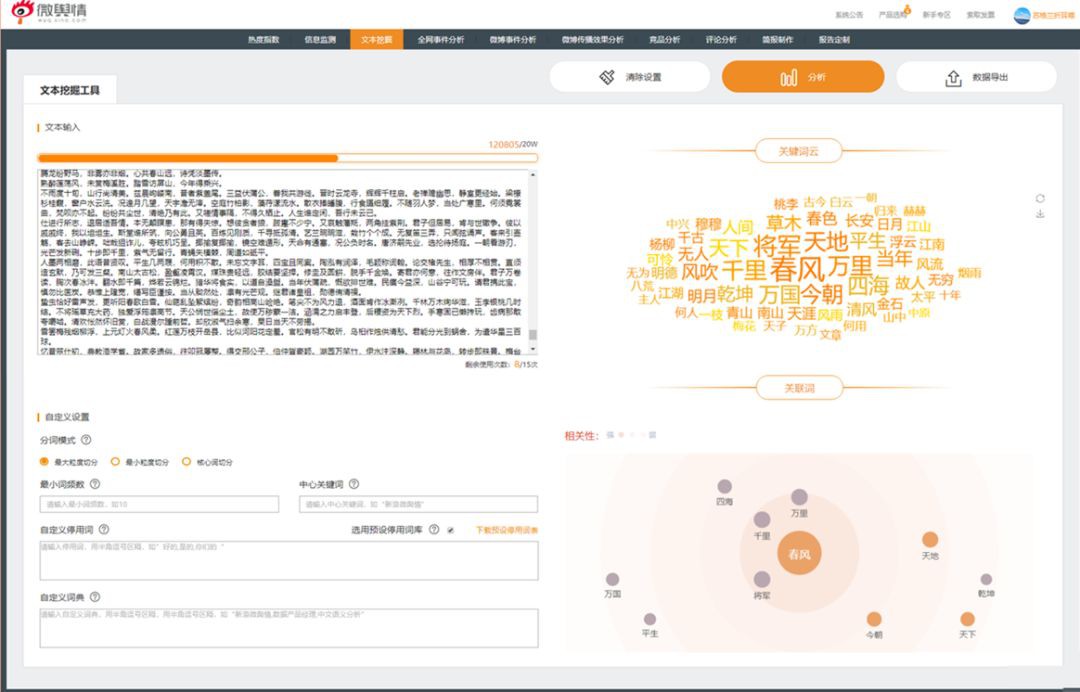
然而,對於古漢語(文言文),尤其是詩詞的分詞處理可沒有這麼簡單,因為單字詞佔古漢語詞彙統計資訊的80%以上,再加上古漢語微言大義,字字千鈞,所以針對現代漢語的分詞技術往往不適用於它。鑒於此種情況,筆者採取的是逐字切分的處理方式,同時去掉一些常見的虛詞,如“之”、“乎”、“者”、“也”。分詞和去停用詞處理如下所示:


經過文字預處理後,就可以進行文字挖掘中最常規的分析—字頻統計,看看《全唐詩》中出現最多的字有哪些。
01 字頻分析:唐詩常用高頻字分析
1. 全域性高頻字
首先,讓我們來看看去掉這些虛詞之後的全域性高頻字有哪些,筆者這裡展示的是TOP148。“人”字排行第一,這體現了《說文解字》裡所講的“人,天地之性最貴者也”,說明唐詩很好的秉承了“以人為本”的中華文化。而後續的“山”、“風”、“月”、“日”、“天”、“雲”、“春”等都是在寫景的詩句裡經常出現的意象。


2. 典型意象分析
所謂“意象”,就是客觀物象經過創作主體獨特的情感活動而創造出來的一種藝術形象。簡單地說,意象就是寓“意”之“象”,就是用來寄託主觀情思的客觀物象。在比較文學中,意象的名詞解釋是—所謂“意象”簡單說來,可以說就是主觀的“意”和客觀的“象”的結合,也就是融入詩人思想感情的“物象”,是賦有某種特殊含義和文學意味的具體形象。簡單地說就是借物抒情。
比如,“月”這個古詩詞裡常見的意象,就有如下內涵:
-
表達思鄉、思親念友之情,暗寓羈旅情懷,寂寞孤獨之感;
-
歷史的見證今昔滄桑感;
-
冷寂、悽清的感覺;
-
清新感 。
筆者在這裡挑選的意象是關於季節和顏色的。
2.1 物轉星移幾度秋——《全唐詩》中的季節
統計“春”、“夏/暑”、“秋”、“冬”這4個字在《全唐詩》中出現的頻次,“春”字排行榜首,“秋”字列第2位,“夏”和“冬”出現的頻次則要少1個量級,在唐詩裡,傷春、惜春是常見的春詩題材,代表性的作品有朱淑真《賞春》、杜甫《麗春》、韓愈《春雪》、張若虛《春江花月夜》等。也難怪,在商代和西周前期,一年只分為春秋二時,後世也常以春秋作為一年的代稱,約定俗成,由來已久,這兩個字的使用頻率很高也就不足為奇了。

2.2 萬紫千紅一片綠——《全唐詩》中的色彩
筆者在這裡找了51個古語中常用的顏色的單字(註意是古漢語語境中的顏色稱謂),其中以紅色系(紅、丹、朱、赤、絳等)、黑色系(暗、玄、烏、冥、墨等)、綠色系(綠、碧、翠、蒼等)及白色系(白、素、皎、皓等)為主,這些顏色及其對應的字頻如下表所示:

這裡面“白”字的字頻最高,本意是“日出與日落之間的天色”,筆者常見的有“白髮”、“白雲”、“白雪”,常渲染出一種韶華易逝、悲涼的氣氛,名句如“白頭搔更短,渾欲不勝簪”、“白雪卻嫌春色晚,故穿庭樹作飛花”、“君不見,高堂明鏡悲白髮,朝如青絲暮成雪”、 “白雲一片去悠悠,青楓浦上不勝愁”。
將上述主要的色系綜合統計一下,得到下麵的環形佔比圖:
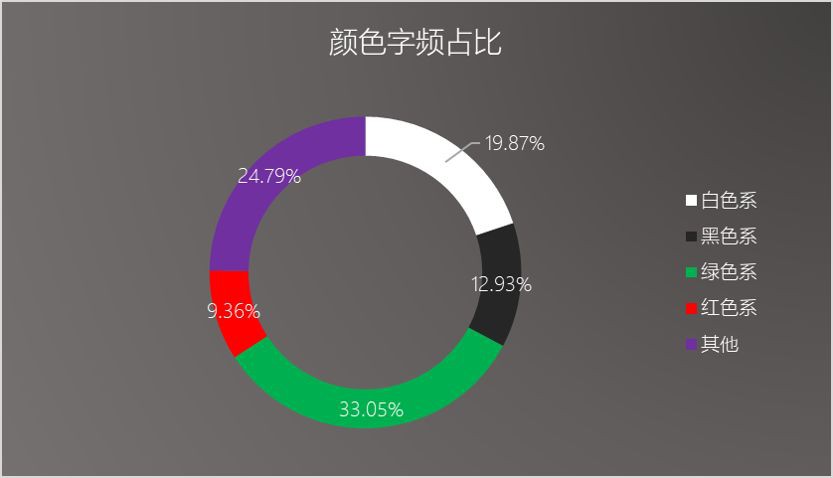
其中,綠色系的佔比居多,“綠”“碧”“蒼”“翠”等大都用於寫景,“綠樹”、“碧水”、“蒼松”、“翠柳”等,這些高頻字從側面反映出全唐詩中描寫景物、寄情山水的詩句佔比很大,透露出平靜、清新和閑適之感。
剛才筆者分析的是單字,而漢語的語素大都是由單音節(字)表示,即所謂的“一音一義”。當這些單音節語素,能夠獨立應用的話,就是詞。古漢語中存在著許多單音節詞,這也就是文言文翻譯中要經常把一個字翻譯成現代漢語中的雙音節詞的原因。
然而,有些單音節語素,不能夠獨立使用,就不是詞,只能夠是語素,如“第-“、”躊-“、”- 們“。
鑒於此,筆者想發現一些唐詩中的常用雙字詞,看看其中的成詞規律是怎樣的。筆者在這裡選取共現次數超過10次的詞彙,併列出TOP200的共現雙字詞。關鍵操作步驟如下所示:

以下是TOP200的共現雙字詞:

從上面的雙詞探測結果中,筆者可以發現如下6類成詞規律:
-
複合式(A+B等於C):由兩個字組成,這兩個字分別代表意義,組成雙音節的詞,這類詞出現的頻次最多。比如,弟兄、砧杵、紀綱、捐軀、巡狩、犬吠。
-
重疊式(AA等於A):琅琅、肅肅、忻忻、灼灼。
-
疊音(AA不等於A):琅琅(單獨拆開不能組其他詞)、的的(拆開後的單字的詞義不同)等。
-
雙聲(聲母相同):躊躇(聲母都是c,分開各自無法組詞)、參差(聲母都是c)、緬邈(聲母都是m)。
-
疊韻(韻母相同):噫嘻(韻母是i)、繚繞(韻母是ao)、妖嬈(韻母是ao)等。
-
雙音節擬聲詞:歔欷、咿啞等。
03 語意網路分析:發現唐詩中的常用“字眼”
在這一部分,筆者抽取的是上述高頻字TOP148中的字的共現關係,詳細的原理介紹請參考筆者之前所寫的博文《以虎嗅網4W+文章的文字挖掘為例,展現資料分析的一整套流程》、《以為例,來談大資料輿情分析和文字挖掘》。

可以看到,上述的語意網路可以分為3個簇群,即橙系、紫系和綠系,TOP148高頻字中,字型清晰可見字的近40個。圓圈的大小表示該字在語意網路中的影響力大小,也就是“Betweenness Centrality(中介核心性),”學術的說法是“兩個非鄰接的成員間的相互作用依賴於網路中的其他成員,特別是位於兩成員之間路徑上的那些成員,他們對這兩個非鄰接成員的相互作用具有某種控制和制約作用”。在詩句中,這些字常以“字眼”的形式呈現,也就是詩文中精要的字。3類中:
-
橙系:北、流、馬、草、閑、孤、逢、雲等;
-
紫系:遊、樹、雨、回、笑、言、幽、清、白、野、行等
-
綠系:知、金、柳、難、愁、舊、仙、望、客。
其中,根據字的構成來看,綠系簇群中的字大多跟送別(好友)有關。
04 字向量分析:基於的Word2vec的關聯字分析
因為之前的文字預處理是按字來切分的,所以這裡進行的是基於Word2vec的字向量分析。
基於Word2vec的字向量能從大量未標註的普通文字資料中無監督地學習到字向量,而且這些字向量包含了字與字之間的語意關係,正如現實世界中的“物以類聚,類以群分”一樣,字可以由它們身邊的字來定義。
從原理上講,基於字嵌入的Word2vec是指把一個維數為所有字的數量的高維空間嵌入到一個維數低得多的連續向量空間中,每個單字被對映為實數域上的向量。把每個單字變成一個向量,目的還是為了方便計算,比如“求單字A的同義字”,就可以透過“求與單字A在cos距離下最相似的向量”來做到。相關案例可參看《作為一個合格的“增長駭客”,你還得重視外部資料的分析!》。下麵是基於Word2vec的字向量模型原理示意圖。
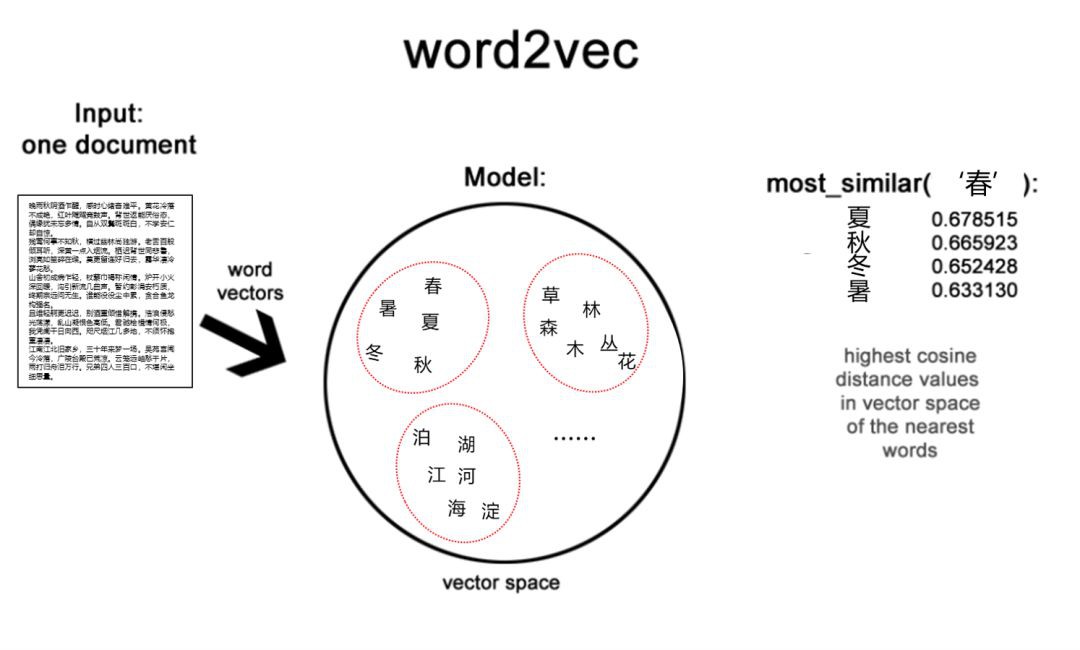
下麵,筆者選取一些單字進行字向量關聯分析,展示如下:
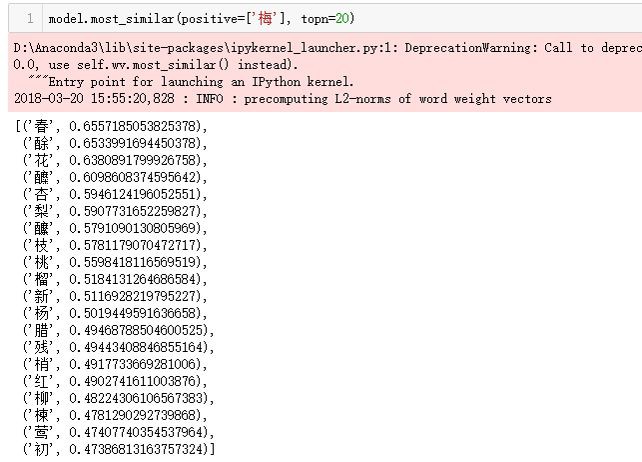
與“梅”相關的字,大致分為兩類:同屬植物,如醾、杏、梨、桃、榴、楊、柳、楝等;和“梅”相關的意象,如春(梅)、酴(酒)、(梅)花、(梅)枝、殘(梅)、(梅)梢等。最相關的是“春”,吟詠春梅,在唐詩中極為常見,賢相宋璟在東川官舍見梅花怒放於榛莽中,歸而有感,作《梅花賦》,其中,”獨步早春,自全其天”,贊賞梅花在早春中一枝獨秀,自己安於凌寒而開的天命。

“靜”字則跟它的同音字“凈(連帶繁體,一共出現三次,即“凈”、“淨”和“凈”)”的相關度最大,結合“坐”、“院”、“梵”等字,可聯想到“凈院”(佛寺,亦稱“凈宇”)、凈覺(謂心無妄念,對境不迷),這也說明,在唐詩裡最能體現靜的,還是在寺廟裡參禪,感悟佛法。
筆者還想看看唐詩裡經常出現的情緒,即“悲”、“憂”、“愁”、“怒”、“懼”,看看它們的相關字有哪些。這裡就請讀者自行分析,筆者不做贅述。
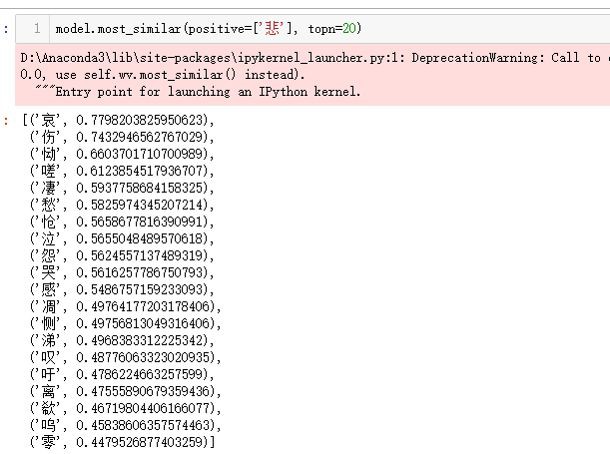




註意,在這裡得到的情緒相關字,筆者將收集整理它們,製成情緒詞典,用於後面的詩詞情緒分類。
05 多維情緒分析:發現唐詩中的“七情”
王國維在《人間詞話》裡曾提到:“境非獨謂景物也,喜怒哀樂,亦人心中之一境界。故能寫真景物、真感情者,謂之有境界…”,講的是”境”與”境界”通用—寫景亦可成境界,言情亦可成境界,因為景物是外在的世界,情感是內在的世界。所以,在這裡,筆者想分析一下全唐詩中詩詞所表達出來的內在境界,也就是內在情感,為了豐富分析維度,不採用簡單的二元分析,即“積極”和“消極”2種情緒,而是7種細顆粒的情緒分類,即悲、懼、樂、怒、思、喜、憂。
根據上面獲取到的字向量,經過人工遴選後,得到可以用於訓練的“情緒字典”,根據詩歌中常見的主題類別,情緒類別分為:
-
悲:愁、慟、痛、寡、哀、傷、嗟…
-
懼:讒、謗、患、罪、詐、懼、誣…
-
樂:悅、欣、樂、怡、洽、暢、愉…
-
怒:怒、雷、吼、霆、霹、猛、轟…
-
思:思、憶、懷、恨、吟、逢、期…
-
喜:喜、健、倩、賀、好、良、善…
-
憂:恤、憂、痾、慮、艱、遑、厄…
筆者在這裡採用的是基於LSTM(LongShort-Term Memory,長短期記憶網路)的情緒分析模型。
在這裡,我們會將文字傳遞給嵌入層(Embedding Layer),因為有數以萬計的字詞,所以我們需要比單編碼向量(One-Hot Encoded Vectors)更有效的表示來輸入資料。這裡,筆者將使用上面訓練得到的Word2vec字向量模型,用預先訓練的詞嵌入(Word Embedding)來引入的外部語意資訊,做遷移學習(Transfer Learning)。
以下是簡要原理展示圖:
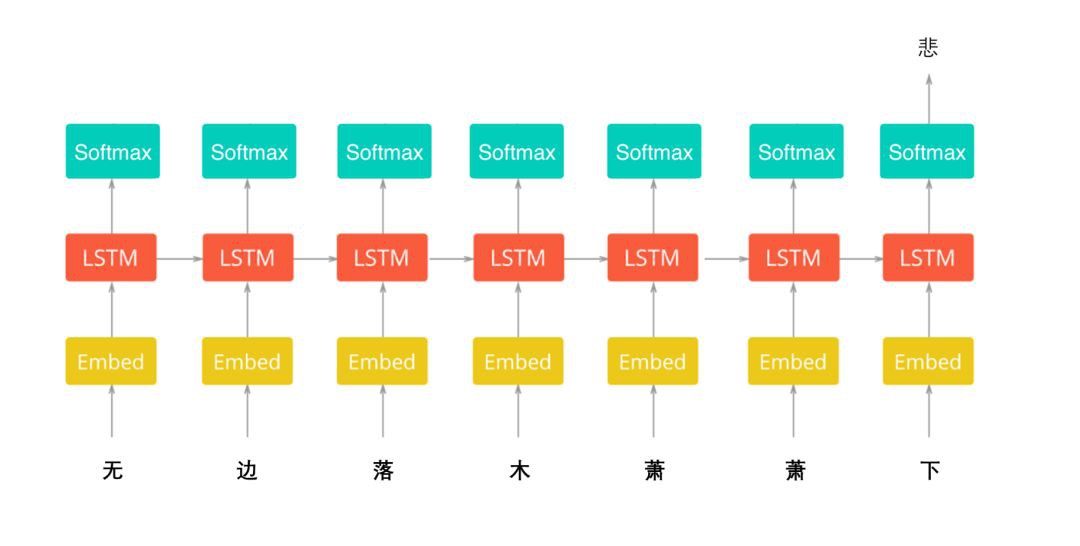
為了取得更好的效果,筆者採用最新的NestedLSTM+Conv1D的深度學習模型來做情緒判斷,它能較好的提煉文本里的特徵和語序資訊,記住更長的語意依賴關係,做出較為精確的情緒判斷。其網路結構如下所示:

接著,來試試實際的效果:

筆者隨機測試了100句,判斷準確的有86條,粗略的準確率估計是86%。當然,這隻是一次不太嚴謹的小嘗試,在真實的業務場景裡,這得花很多時間來做最佳化,提高模型的準確率。
下麵是對《全唐詩》近5萬首詩的情緒分析結果,展示如下:
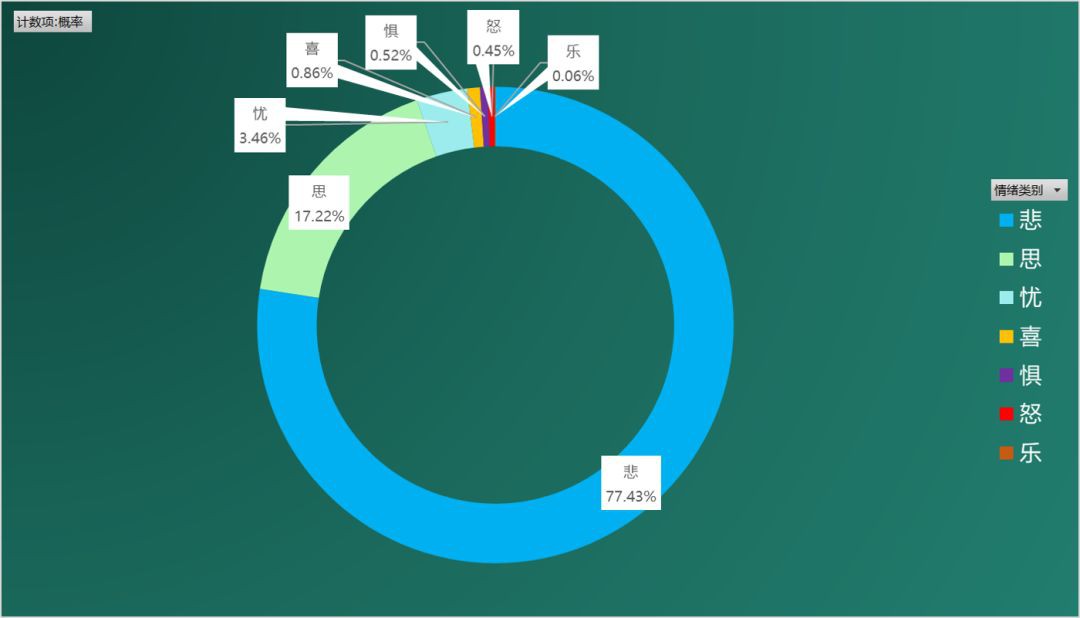
可能出乎很多人的意料,代表大唐氣象的唐詩應該以積極昂揚的情緒為主,怎麼會是“悲”、“思”、“憂”這樣的情緒佔據主流呢?而 “喜”、“樂”這樣的情緒卻佔據末流呢?
接下來,筆者著重來分析下“悲”這個情緒佔據主流的原因。
從常見的唐詩寫作題材上說,帶有“悲”字基調的唐詩較多,也多出名詩佳句,比如唐詩中常見的幾種情結,如“悲秋情結”、“別離情結”、“薄暮情結”和“悲怨情結”,都體現出濃重的“悲情”色彩。
古人雲:“悲憤出詩人”,它點破了人的成就與所處的環境、心境有某種關係。就像司馬遷所說:“夫《詩》、《書》隱約者,欲遂其志之思也。昔西伯拘羑里,演《周易》;孔子厄陳、蔡,作《春秋》…大抵賢聖發憤之所為作也。此人皆意有所鬱結,不得通其道也…”回顧古今中外的著名的詩人和作家,幾乎無一不是曾有一段被排擠,誹謗,不得志和身處逆境之經歷,有些甚至還很悲慘。正是在這種悲難,惡劣環境中,才使得其奮發圖強。
重要的是,唐詩中的“悲”不僅僅是做“兒女態”的悲,更是具有超越時空、憐憫蒼生以及同情至美愛情的大慈大悲。如下:
-
陳子昂的《登幽州臺歌》,“前不見古人,後不見來者。念天地之悠悠,獨愴然而涕下。”從時間與空間兩個角度把悲涼拉長了。
-
李白的《將進酒》中“君不見明鏡高堂悲白髮,朝如青絲暮成雪”,以及《夢遊天姥吟留別》中“世間行樂亦如此,古來萬事東流水”讓人唏噓!還有《長相思》第一首中“天長路遠魂飛苦,夢魂不到關山難。長相思,摧心肝。”
-
杜甫的《登高》中“無邊落木蕭蕭下,不盡長江滾滾來。萬裡悲秋常作客,百年多病獨登臺。”老病殘軀,孤苦無依獨登臺,心中悲涼陡然而生。《石壕吏》中“老嫗力雖衰,請從吏夜歸。急應河陽役,猶得備晨炊”等句語言樸實,但極具張力!
-
白居易的《長恨歌》末尾“七月七日長生殿,夜半無人私語時。在天願作比翼鳥,在地願為連理枝。天長地久有時盡,此恨綿綿無絕期。”相愛而不能相聚,生死遺恨,沒有盡頭!
與上面情緒分析模型採用的內部原理一致,這裡採用的還是LSTM,2層網路。
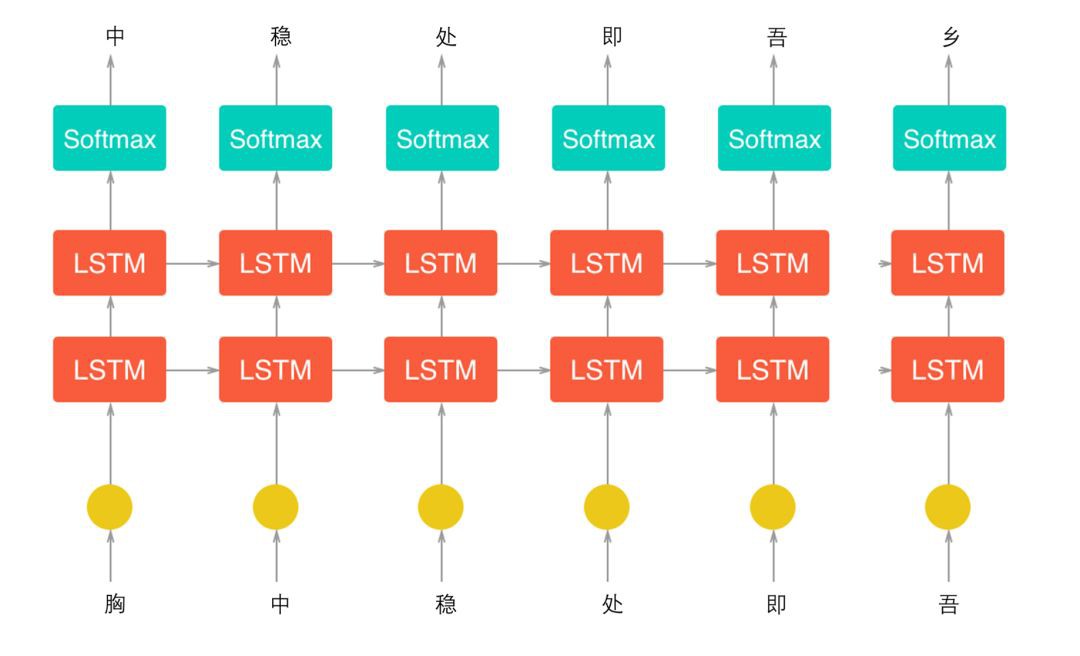
上圖是文字生成的簡要原理圖,是基於字元(字母和標點符號等單個字串,以下統稱為字元)進行模型構建,也就是說我們的輸入和輸出都是字元。舉個慄子,假如我們有一個一句詩“胸中穩處即吾鄉”,我們想要基於這句詩來構建LSTM,那麼希望的到的結果是,輸入“胸”,預測下一個字元為“中”;輸入“中”時,預測下一個字元為“穩”…輸入“吾”,預測下一個字元為“鄉”,等等。
由於其中的原理過於繁複,涉及大量的code和數學公式,故筆者僅展示生成的結果,訓練的語料即經過預處理的《全唐詩》。
以“春雨”打頭,生成500字的詩詞,結果如下:
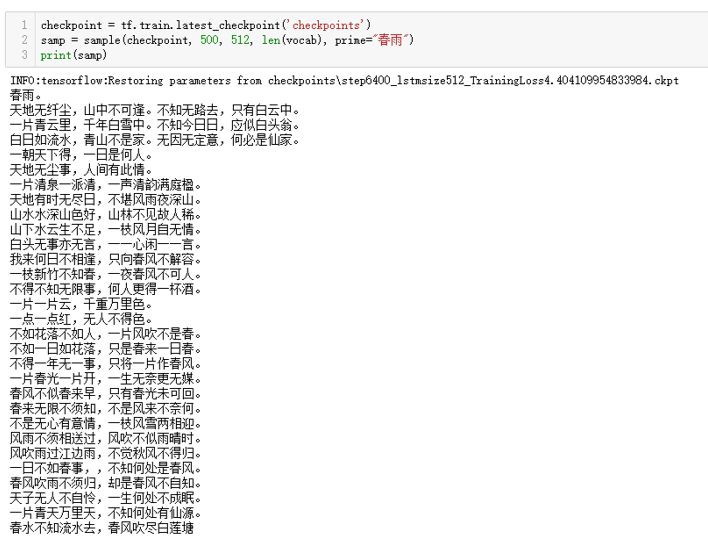
可以看見,其中的詩詞大都圍繞著“春”來展開,也就是打頭的兩個字引導了後續結果的生成,這多虧了LSTM超強的“記憶能力”——記住了詩歌文字序列中的時空依賴關係。
在生成的詩句中,某些詩句還是蠻有意思的,上下聯間的意象有很強的相關性。
下麵是多次生成中產生的較優秀的詩句(當然,這是筆者認為的),其中有些學習到了高階的對仗技巧,如下:

白鷺驚孤島,朱旗出晚流。
筆者最喜歡的是這兩句,它們對仗工整:“白鷺”-“朱旗”,“孤島”-“晚流”,“驚”-“出”。這裡體現出《人間詞話》中的“無我之境”: “無我之境,以物觀物,故不知何者為我,何者為物”,也就是意境交融、物我一體的優美境界,其中的 “驚”、“出”堪稱字眼,極具動感,煉字絕妙!
最後,我們來看看詩歌的資訊檢索問題,也就是筆者隨意輸入一句詩詞,然後機器會按照語意相似度在《全唐詩》中檢索出若干句符合要求的詩詞。
談到這裡,筆者不由得想起一個詞——“射覆”,射覆遊戲早期的耍法主要是制謎猜謎和用盆盂碗等把某物件事先隱藏遮蓋起來,讓人猜度。這兩種耍法都是比較直接的。後來,在此基礎上又產生了一種間接曲折的語言文字形式的射覆遊戲,其法是用相連字句隱寓事物,令人猜度,若射者猜不出或猜錯以及覆者誤判射者的猜度時,都要罰酒。唐浩明的長篇小說《張之洞》中有對射覆遊戲的精彩描寫:
寶竹坡突然對大家說,我有一覆,諸位誰可射中。不帶大家做聲,他立刻說,《左傳》曰:伯姬歸於宋。射唐人詩一句。大家都低頭想。
……
張之洞不慌不忙地念著,白居易詩曰:老大嫁作商人婦。
如果對古文生疏,大家可能很難將這兩句聯想起來,但《張之洞》裡接下來就有關於解謎的描述:
楊銳道:“伯、仲、叔、季,這是中國兄弟姊妹得排行序列。伯姬是魯國的長公主,排行老大。周公平定武庚叛亂後,把商舊都周圍地區封給商紂王的庶子啟,定國名為宋,故宋國為商人後裔聚族之地。伯姬嫁到宋國,不正是’老大嫁作商人婦’嗎?”
大家可能會想,如果是自己來思索的話,不僅需要自己具備淵博的學識,更要有疾如閃電的反應能力,這個非極頂聰明之人不可!
試想,機器來做,可以做好嗎?能的話,又會是如何操作?
這裡,筆者介紹基於WMD(Earth Mover’s Distance)的語意相似度演演算法,與上面的情緒分析類似,還有用到之前訓練得到的字向量模型,藉助外部語意資訊來應對同義不同字的情形。
WMD是一種能使機器以有意義的方式(結合文字的語意特徵)評估兩個文字之間的“距離(也就是文字間的相似度)”的方法,即使二者沒有包含共同的詞彙。它使用基於word2vec的詞向量,已被證明超越了k-近鄰分類中的許多現有技術方法。以下是基於WMD的“射覆”的機器解:

上面兩個句子沒有共同的詞彙,但透過匹配相關單字,WMD能夠準確地測量兩個句子之間的(非)相似性。該方法還使用了基於詞袋模型的文字表示方法(簡單地說,就是詞彙在文字中的頻率),如下圖所示。該方法的直覺是最小化2段文字間的“旅行距離(traveling distance)”,換句話說,該方法是將檔案A的分佈“移動”到檔案B分佈的最有效方式。
簡要的解釋了相關原理後,筆者緊接著展現最後的分析效果。由於對《妖貓傳》中的那首線索式的《清平樂》印象深刻,筆者讓機器在《全唐詩》+《全宋詞》中查詢與它相關性最大的TOP9詩詞。結果如下:

查詢的結果排行第一的是原句,但有一個字不同(其實古語中“花”、“華”互通,華字的繁體是會意字,本意是“花”),略微差異導致相似度不為1.0。第二相似的是一首宋詞,林正大的《括酹江月(七)》,其實這整首詞可以作為李白《清平樂》的註解,因為全篇都是對它的化用:即將《清平樂》中的句、段化解開來,增加了新的聯想,重新組合,靈活運用,對原詩的表達進行了情感上的升華。隨後的兩句詩詞也是類似的情況,只是相似度上略有差異罷了。
緊接著,是剛才機器生成的詩句,看看與它內涵相近的詩句有哪些:

再看看筆者較為欣賞的2句名句,機器很好的捕捉到了它們之間的相似語意關係,即使詞彙不盡相同,但仍能從語意上檢索相似詩句。


寫到這裡,關於《全唐詩》單獨的文字挖掘已經完成,但筆者又想到一個有趣的分析維度——從文字挖掘的角度來比較《全唐詩》、《全宋詞》和《全元曲》之間用字的差異,藉助字這種基本符號來分析各自的文學藝術特徵。
08 文字對比:用Semiotic Squares比較《全唐詩》、《全宋詞》和《全元曲》
因為分析的物件涉及3個,常規的二元對比分析方法難以得出有效的結論。因此,筆者在這裡跨界採用來自符號學領域的研究成果——Semiotic Squares。
“Semiotic Squares(筆者譯作‘符號方塊’)”,是由知名符號學大師Greimas和Rastier發明,是一種提煉式的對比分析(Oppositional Analyses)方法,透過將給定的兩個相反的概念/事例(如 “生命(Life)”和“死亡(Death)”)的分析型別(透過‘或’、‘與’、‘非’的邏輯)拓展到4類(如“生命(Life)”、“死亡(Death)”、“生死相間(也就是活死人,The Living Dead)”、“非生非死(天使,Angels)”,有時還可以拓展到8個或10個分析維度。以下是符號方塊的結構示意圖:

說明:“+”符號將2個詞項組合成一個“元詞項(Metaterm)”(複合詞,Compound Term),例如,5是1和2的複合結果。
Semiotic Squares的構成要素
Semiotic Squares主要包含以下2種元素(我們正在避開方塊的組成關係:對立,矛盾、互補或包含):
(1)詞項(Terms):
Semiotic Square 由4個詞項組成:
-
位置1 (Term 1):詞項A(Term A)
-
位置 2(Term 2):詞項B(Term B)
-
位置 3 (Term Not-2):非B詞項(Term Not-B)
-
位置 4 (Term Not-1):非A詞項(Term Not-A)
Term A和TermB是相反的兩個概念,二者是對立關係,這是“符號方塊”的基礎,另外兩項是透過對Term A和Term B取反而獲得。
(2)元詞項 (Metaterms)
Semiotic Square囊括6個元詞項。這些元詞項由上面的4個基礎詞項組合而成,其中的絕大部分元詞項已被命名。
-
位置5 (Term 1 + Term 2):複合詞項(Complex Term)
-
位置6 (Term 3 + Term 4):中立詞項(Neutral Term)
-
位置7 (Term 1 + Term 3):正向系(Positive Deixis)
-
位置8 (Term 2 + Term 4):負向系(Negative Deixis)
-
位置9(Term 1 + Term 4):未命名(Unnamed)
-
位置10(Term 2 + Term 3):未命名(Unnamed)
下麵以“男性”和“女性”這兩個相對的概念來舉個例子,註意其中錯綜複雜的邏輯關係/型別。

說完了分析的大致原理,筆者這裡就來實戰一番,與上述原始模型不同的是,筆者在這裡除了基本的二元對立分析外,還新增了一個分析維度,總體是關於《全唐詩》、《全宋詞》和《全元曲》的三元文字對比分析。
預處理前的文字是這樣的:

預處理後是這樣的形式:

用Semiotic Squares進行分析的結果如下圖所示(點選即可放大顯示):
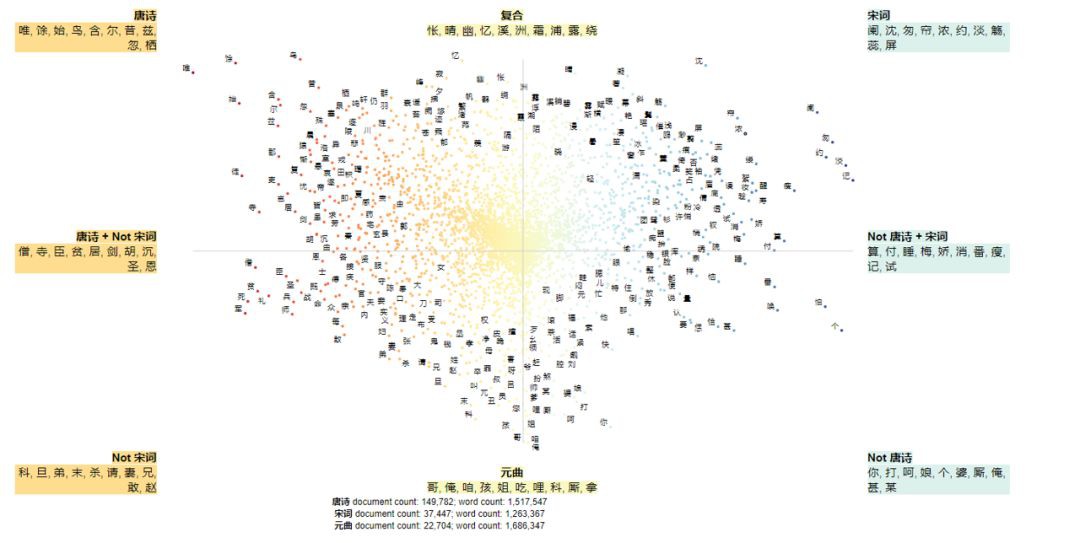
從上面呈現的TOP10高頻字和象限區塊(左上角“唐詩”、右上角“宋詞”和正下方“元曲”)來看,唐詩、宋詞、元曲中出現的獨有高頻字依次是:
-
唐詩:唯、餘、始、鳥、含、爾、昔、茲、忽、棲、川、旌、戎、秦…
-
宋詞:闌、沈、匆、簾、濃、約、淡、觴、蕊、屏、凝、笙、瑤、柔…
-
元曲:哥、俺、咱、孩、姐、吃、哩、科、廝、拿、你、叫、呀、呵…
從上面的關鍵字來看,唐詩、宋詞和元曲各自的特徵很鮮明:
-
唐詩:用字清澹高華、含蓄,詩味較濃,寄情山水和金戈鐵馬的特徵明顯,可以聯想到唐詩流派中典型的山水田園派和盛唐邊塞詩,它們大都反映大唐詩人志趣高遠、投效報國的情懷。
-
宋詞:所用的字型現出婉約、宛轉柔美,表現的多是兒女情長,生活點滴,這也難怪,由於長期以來詞多趨於宛轉柔美,人們便形成了以婉約為正宗的觀念。
-
元曲:所用的字生活氣息濃重,通俗易懂、接地氣、詼諧、灑脫和率真,充分反映了其民間戲曲的特徵,這與蒙元治下的漢族知識分子被打壓,很多文人鬱鬱不得志、轉入到民間戲曲的創作中來有關。
此外,正上方的“複合”中,表徵的是三者皆常用的字,即共性特徵,主要涉及寫景(如 “晴”、“幽”、“溪”、“洲”、“霜”、“浦”、“露”、 “碧”、“帆”、“峰”等)和抒情(等“悵”、“憶”、“寂”、“悠”等)。
下方的兩個象限,“Not 唐詩”和“Not 宋詞”分別代表的“宋詞+元曲”、“唐詩+元曲”,三者之二的共性高頻字,中的兩項也以此類推,筆者在這裡就不贅述了,請讀者朋友們親自去挖掘裡面的玄妙吧。
結語
筆者非專業的詩歌研究者,上面的分析也未必準確,如果有分析不恰當的地方,還請扶正。但是,筆者是想透過分析唐詩,來說下自己對於文字(資料)挖掘的看法:
在資料分析中,得出的資料結果只是“引子”和“線索”,最重要的還是要靠人腦去分析結果,藉助所掌握的背景/業務知識和分析模型,從文字的表層鑽取到其深層,去發現那些不能為淺層閱讀所把握的深層意義,挖掘其價值。
參考資料:
1 資料來源:《全唐詩》、《全宋詞》、《全元曲》
2 使用工具:Excel、python及其相關庫(Gensim、Tensorflow、Keras、Jieba)、Gephi
3 維基百科“唐詩”詞條,https://zh.wikipedia.org/wiki/%E5%94%90%E8%AF%97
4 維基百科“意象”詞條,https://zh.wikipedia.org/wiki/%E6%84%8F%E8%B1%A1
5 漢語中字與詞的關係?,知乎,https://www.zhihu.com/question/23593755
6 王國維,《人間詞話》
7 The Unreasonable Effectiveness of Recurrent Neural Networks,Andrej Karpathy blog, http://karpathy.github.io.
8 Understanding LSTM Networks,Colah,http://colah.github.io/posts/2015-08-Understanding-LSTMs
9 長篇小說《張之洞》,唐浩明
10 Semiotic-Square ,http://www.signosemio.com/greimas/semiotic-square.asp
作者:蘇格蘭折耳喵
來源:運營喵是怎樣煉成的(ID:yymzylc)
推薦閱讀
日本老爺爺堅持17年用Excel作畫,我可能用了假的Excel···
Q: 詩興大發了嗎?現在你可以寫了!
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視

