(點選上方公眾號,可快速關註)
來源:五月的倉頡 ,
www.cnblogs.com/xrq730/p/4827590.html
幾個計算機的概念
為以後寫文章考慮,也為鞏固自己的知識和一些基本概念,這裡要理清楚幾個計算機中的概念。
1、計算機儲存單位
從小到大依次為位Bit、位元組Byte、千位元組KB、兆M、千兆GB、TB,相鄰單位之間都是1024倍,1024為2的10次方,即:
-
1Byte = 8bit
-
1K = 1024Byte
-
1M = 1024K
-
1G = 1024M
-
1T = 1024G
2、計算機儲存元件
暫存器:中央處理器CPU的一部分,是計算機中讀寫速度最快的儲存元件,但是容量很少
記憶體:屬於獨立的一個部件,是和CPU溝通的橋梁,用於存放CPU中的運算元據以及與外部儲存器交換的資料。儘管在今天,對記憶體的讀寫速度已經很快了,但是由於暫存器是在CPU上的,所以對於記憶體的讀寫速度和對於暫存器的讀寫速度上還是有幾個數量級的差距。但是沒辦法,對於記憶體的讀寫I/O操作是很難消除的,暫存器數量有限,不可能透過暫存器來完成所有的運算任務
3、核心空間和使用者空間
連線記憶體和暫存器的是地址匯流排,地址匯流排的寬度影響了物理地址的索引範圍,因為匯流排寬度決定了處理器一次可以從暫存器或記憶體中獲取多少個Bit,同時也決定了處理器最大可以定址的地址空間。比如32位CPU的系統,可定址範圍為0×00000000~0xFFFFFFFF,即232=4294967296個記憶體位置,每個記憶體位置1個位元組,即32位CPU系統可以有4GB的記憶體空間。不過應用程式是不可以完全使用這些地址空間的,因為這些地址空間被劃分為了核心空間和使用者空間,程式只能使用使用者空間的記憶體。核心空間主要是指作業系統執行時所使用的用於程式排程、虛擬記憶體的使用或者連結硬體資源的程式邏輯。區分核心空間和使用者空間的目的主要是從系統的穩定性的角度考慮的。Windows 32作業系統預設核心空間和使用者空間的比例是1:1,即2G核心空間、2G記憶體空間,32位Linux系統中預設比例則是1:3,即1G核心空間,3G記憶體空間。
4、字長
CPU的主要技術指標之一,指的是CPU一次能並行處理二進位制的位數(Bit)。通常稱處理字長為8位資料的CPU為8位CPU,32位CPU就是在同一時間內處理字長為32位的二進位制資料。不過目前雖然CPU大多是64位的,但還是以32位字長執行
前言
說到Java記憶體區域,可能很多人第一反應是“堆疊”。首先堆疊不是一個概念,而是兩個概念,堆和棧是兩塊不同的記憶體區域,簡單理解的話,堆是用來存放物件而棧是用來執行程式的。其次,堆記憶體和棧記憶體的這種劃分方式比較粗糙,這種劃分方式只能說明大多數程式員最關註的、與物件記憶體分配關係最密切的記憶體區域是這兩塊,Java記憶體區域的劃分實際上遠比這複雜。對於Java程式員來說,在虛擬機器自動記憶體管理機制的幫助下,不再需要為每一個new操作去配對delete/free程式碼,不容易出現記憶體洩露和記憶體上限溢位問題。但是,也正是因為Java把記憶體控制權交給了虛擬機器,一旦出現記憶體洩露和記憶體上限溢位的問題,就難以排查,因此一個好的Java程式員應該去瞭解虛擬機器的記憶體區域以及會引起記憶體洩露和記憶體上限溢位的場景。
執行時資料區域
Java虛擬機器(JVM)內部定義了程式在執行時需要使用到的記憶體區域,從http://images.blogjava.net/blogjava_net/nkjava/jvmstructure.png複製一張圖下來
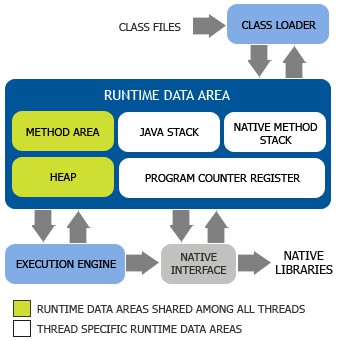
之所以要劃分這麼多區域出來是因為這些區域都有自己的用途,以及建立和銷毀的時間。有些區域隨著虛擬機器行程的啟動而存在,有的區域則依賴使用者執行緒的啟動和結束而銷毀和建立。圖中綠色部分就是所有執行緒之間共享的記憶體區域,而白色部分則是執行緒執行時獨有的資料區域,從這個分類角度來看一下這幾個資料區。
1、執行緒獨有的記憶體區域
(1)PROGRAM COUNTER REGISTER,程式計數器
這塊記憶體區域很小,它是當前執行緒所執行的位元組碼的行號指示器,位元組碼直譯器透過改變這個計數器的值來選取下一條需要執行的位元組碼指令。Java方法這個計數器才有值,如果執行的是一個Native方法,那這個計數器是空的。
(2)JAVA STACK,虛擬機器棧
生命週期和執行緒相同。每個方法執行的同時都會建立一個棧幀,用於儲存區域性變數表、運算元棧、動態連結、方法出口等資訊,每一個方法從呼叫直至執行完畢的過程,就對應著一個棧幀在虛擬機器中入棧到出棧的過程。棧的大小和具體JVM的實現有關,通常在256K~756K之間。
(3)NATIVE METHOD STACK,方法棧
和虛擬機器棧起的作用一樣,只不過方法棧為虛擬機器使用到的Native方法服務。虛擬機器規範並沒有對這個區域有什麼強制規定,因此我們使用的HotSpot虛擬機器,就乾脆沒有這塊區域了,它和虛擬機器棧是一起的。
2、執行緒間共享的記憶體區域
(1)HEAP,堆
大多數應用,堆都是Java虛擬機器所管理的記憶體中最大的一塊,它在虛擬機器啟動時建立,此記憶體唯一的目的就是存放物件實體。由於現在垃圾收集器採用的基本都是分代收集演演算法,所以堆還可以細分為新生代和老年代,再細緻一點還有Eden區、From Survivior區、To Survivor區,這個後面都會講到的。
(2)METHOD AREA,方法區
這塊區域用於儲存虛擬機器載入的類資訊、常量、靜態變數、即時編譯器編譯後的程式碼等資料,虛擬機器規範是把這塊區域描述為堆的一個邏輯部分的,但實際它應該是要和堆區分開的。從上面提到的分代收集演演算法的角度看,HotSpot中,方法區≈永久代。不過JDK 7之後,我們使用的HotSpot應該就沒有永久代這個概念了,會採用Native Memory來實現方法區的規劃了。
(3)RUNTIME CONSTANT POOL,執行時常量池
上面的圖中沒有畫出來,因為它是方法區的一部分。Class檔案中除了有類的版本資訊、欄位、方法、介面等描述資訊外,還有一項資訊就是常量池,用於存放編譯期間生成的各種字面量和符號取用,這部分內容將在類載入後進入方法區的執行時常量池中,另外翻譯出來的直接取用也會儲存在這個區域中。這個區域另外一個特點就是動態性,Java並不要求常量就一定要在編譯期間才能產生,執行期間也可以在這個區域放入新的內容,String.intern()方法就是這個特性的應用。
3、直接記憶體
想想還是把這塊加上。直接記憶體並不是虛擬機器執行時資料區的一部分,也不是Java虛擬機器規範中定義的記憶體區域。但是這部分記憶體也被頻繁地使用,而且也可能導致記憶體上限溢位問題。JDK1.4中新增加了NIO,引入了一種基於通道與緩衝區的I/O方式,它可以使用Native函式庫直接分配堆外記憶體,然後透過一個儲存在Java堆中的DirectByteBuffer物件作為這塊記憶體的取用進行操作。這樣能在一些場景中顯著提高效能,因為避免了在Java堆和Native堆中來回覆制資料。顯然,本機直接記憶體的分配不會受到Java堆大小的限制,但是,既然是記憶體,肯定還是會受到本機總記憶體(包括RAM、SWAP區)大小以及處理器定址空間的限制。
物件建立
Java是一門面向物件的語言,Java程式執行過程中無時無刻都有物件被創建出來。在語言層面上,建立物件(克隆、反序列化)就是一個new關鍵字而已,但是虛擬機器層面上卻不是如此。看一下在虛擬機器層面上建立物件的步驟:
1、虛擬機器遇到一條new指令,首先去檢查這個指令的引數能否在常量池中定位到一個類的符號取用,並且檢查這個符號取用代表的類是否已經被載入、解析和初始化。如果沒有,那麼必須先執行類的初始化過程。
2、類載入檢查透過後,虛擬機器為新生物件分配記憶體。物件所需記憶體大小在類載入完成後便可以完全確定,為物件分配空間無非就是從Java堆中劃分出一塊確定大小的記憶體而已。這個地方會有兩個問題:
(1)如果記憶體是規整的,那麼虛擬機器將採用的是指標碰撞法來為物件分配記憶體。意思是所有用過的記憶體在一邊,空閑的記憶體在另外一邊,中間放著一個指標作為分界點的指示器,分配記憶體就僅僅是把指標向空閑那邊挪動一段與物件大小相等的距離罷了。如果垃圾收集器選擇的是Serial、ParNew這種基於壓縮演演算法的,虛擬機器採用這種分配方式。
(2)如果記憶體不是規整的,已使用的記憶體和未使用的記憶體相互交錯,那麼虛擬機器將採用的是空閑串列法來為物件分配記憶體。意思是虛擬機器維護了一個串列,記錄上哪些記憶體塊是可用的,再分配的時候從串列中找到一塊足夠大的空間劃分給物件實體,並更新串列上的內容。如果垃圾收集器選擇的是CMS這種基於標記-清除演演算法的,虛擬機器採用這種分配方式。
另外一個問題及時保證new物件時候的執行緒安全性。因為可能出現虛擬機器正在給物件A分配記憶體,指標還沒有來得及修改,物件B又同時使用了原來的指標來分配記憶體的情況。虛擬機器採用了CAS配上失敗重試的方式保證更新更新操作的原子性和TLAB兩種方式來解決這個問題。
3、記憶體分配結束,虛擬機器將分配到的記憶體空間都初始化為零值(不包括物件頭)。這一步保證了物件的實體欄位在Java程式碼中可以不用賦初始值就可以直接使用,程式能訪問到這些欄位的資料型別所對應的零值。
4、對物件進行必要的設定,例如這個物件是哪個類的實體、如何才能找到類的元資料資訊、物件的雜湊碼、物件的GC分代年齡等資訊,這些資訊存放在物件的物件頭中。
5、執行
以上這部分內容,如果有下載OpenJDK的原始碼的話,可以透過參考hotspot/src/share/vm/interpreter/bytecodeInterpreter.cpp檔案,從1939行開始。1939行的程式碼是CASE(_new):{…},意思是當程式碼中遇見new這個關鍵字,虛擬機器做的事情。實際虛擬機器可能並不是執行的這段程式碼,但是透過這段程式碼來瞭解new物件的時候虛擬機器的運作過程基本上是沒問題的。
物件定位方式
建立物件是為了使用物件,Java程式需要透過棧上的reference(取用)資料來操作堆上的具體物件。比如我們寫了一句
Object obj = new Object()
而new Object()之後其實有兩部分內容,一部分是類資料(比如代表類的Class物件)、一部分是實體資料
由於reference在Java虛擬機器規範中只是一個指向物件new Object()的取用obj,並沒有規定obj應該透過何種方式去定位、訪問堆中物件的具體位置,所以物件訪問方式也是取決於虛擬機器而定的。主流方式有兩種:
1、控制代碼訪問。Java堆中劃分出一塊控制代碼池,obj指向的是物件的控制代碼地址,控制代碼中則包含了類資料的地址和實體資料的地址
2、指標訪問。物件中儲存所有的實體資料和類資料的地址,obj指向的是這個物件
HotSpot虛擬機器採用的是後者,不過前者的物件訪問方式也是十分常見的。
系列
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

