來自:碼農翻身(微訊號:coderising)
1分散式系統的難題
張大胖遇到了一個難題。
他們公司的有個伺服器,上面儲存著寶貴的資料,領導Bill 為了防止它掛掉, 要求張大胖想想辦法把資料做備份。
張大胖發揮了抽象的能力,在腦海裡浮出了這麼一個畫面, 這個唯一的機器可以成為一個節點:
為了提高可用性,可以增加幾臺機器,透過區域網連線起來,形成一個了分散式的系統:

資料在每個節點上都存放一份不就可以高枕無憂了?
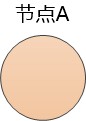
可張大胖很快發現這不是一件容易的事情,比如每個節點都儲存著一個賬戶的餘額100元,現在有人透過節點A向該賬戶增加了20元, 還有人透過節點B向該賬戶減去了30元。
現在餘額到底是多少呢?
為了保持一致性, 節點A得把”餘額加上20″這樣的訊息發給B, C , 節點B得把“餘額減去30”這樣的訊息傳送到A, C, 如果網路出了問題,訊息沒有傳送到別的節點, 或者某個節點乾脆壞掉了,那資料極有可能出現不一致。
如果使用者在這個不一致的系統上繼續操作,很快就會陷入混亂。
2誰來當老大?
張大胖想了半天,覺得不能這麼無序地操作,得給這三個節點找個“老大”。
所有的操作都透過“老大”來進行,然後讓老大把訊息發給各個“小弟”。

可是誰來當老大呢? 還有,這個老大如果掛掉了怎麼辦?
可以手工地調整, 例如節點A掛掉了, 就手工地讓節點B當“老大” , 讓節點C當“小弟”。
但是這就有點麻煩了,能不能自動化地來實現?
這個問題很有意思, 張大胖入了迷,繼續深入思考: 建立一個競選的機制, 就讓他們競爭上崗吧。
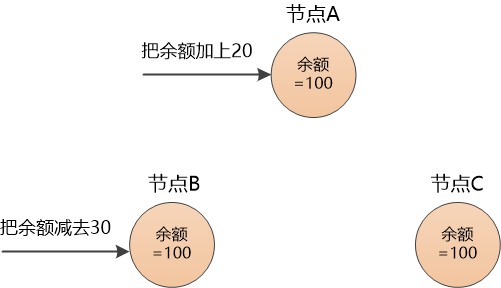
初始情況下,每個節點都是候選人, 都可以向其他節點發起投票邀請,讓大家投自己,如果獲得的投票數過半,就可以當“老大”了。
為了避免大家同時發起投票邀請,可以給每個節點都分配一個隨機的“選舉超時時間”(election timeout),通俗來講就是一個等待時間,在這段時間內,一個節點必須耐心等待,過了這段時間,才可以競爭上崗,爭當老大。
每個節點都有一個計時器,從0開始計時,誰的等待時間到了, 就率先發起競選,給其他節點打電話,要求他們投票讓自己成為老大。
比如節點A等待170ms , 節點B等待200ms , 節點C等待250ms 。
由於節點A的等待時間最短, 會捷足先登, 它先增加自己的任期(Term),這是一個整數,初始值為0 , 然後給自己投了一票,然後打電話給節點B和節點C,要求他們都投它。
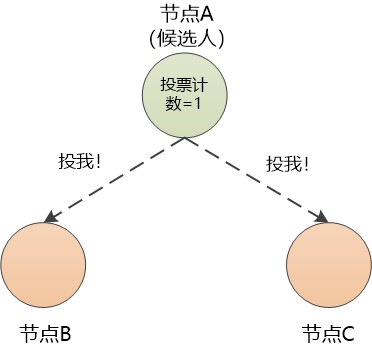
節點B和節點C收到了投票要求,如果自己還沒有發起競選投票(等待時間未到),那隻好同意節點A當老大,與此同時要重置自己的計時器,重新從0開始計時,也就是說重新開始新一輪的等待。

節點A得知其他兩個節點同意了,投票計數變為3,已經過了半數, 就明白自己可以當老大了。
節點A成為老大後,開始向節點B和節點C定時傳送訊息,B,C收到訊息後也要回應,維持心跳。
B和C每次收到心跳訊息,都得重置自己的計時器, 重新從0開始計數。
此時節點B和節點C就成了“小弟”。
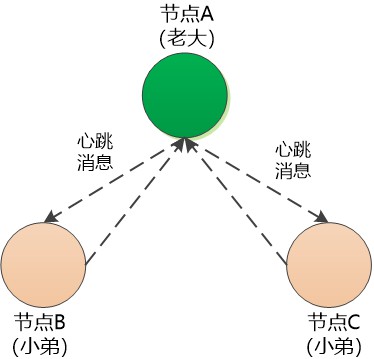
如果節點A 不幸掛掉,節點B和節點C在自己的等待時間內收不到心跳訊息,他們兩個就會重新競爭上崗。

上圖中節點C佔據了先機,率先發起競選投票。
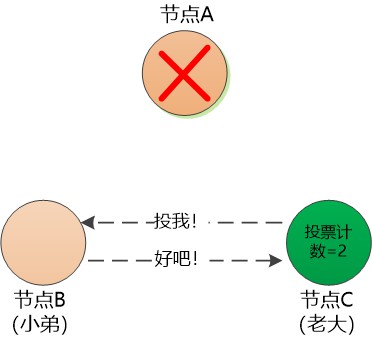
節點B慢了一步, 無奈中同意支援節點C , 節點C獲得了超過半數的支援,成為“老大” , 節點B成為“小弟”。
(可能有人會想到:節點B和節點C 同時發起競選投票,每個節點的投票計數都是1 ,都過不了半數, 該怎麼處理呢? 很簡單,再次發起一輪競選投票即可,當然為了防止B和C一直同時發起競選投票,從而陷入無限迴圈,要重置一個隨機的等待時間。)
投票過半數很重要,張大胖想,只有這樣才能保證“老大”節點的唯一性。
對於每個節點,處理流程其實非常簡單:

3資料的複製
張大胖費了半天勁,終於把分散式系統中怎麼自動地選取“老大”節點給確定了。
接下來就是要把發給“老大”的資料,想辦法複製到“小弟”的節點上。 該怎麼處理?
由於是分散式的,只有大多數節點都成功地儲存了資料,才算儲存成功。
所以那個“老大”節點必須得承擔起協調的職責。
張大胖想了一個複製日誌的辦法: 每個節點都有一個日誌的佇列。

在真正把資料提交之前,先把資料追加到日誌佇列中,然後向個“小弟”複製。

1. 客戶端傳送資料給節點A (“老大”)。
節點A 先把資料記錄到日誌中,即此時處於“未提交狀態”
2. 在下一次的心跳訊息中, 資料被髮送給各個“小弟”。
3. 各個“小弟” 也把資料記錄到日誌中(也處於未提交狀態),然後向“老大”報告自己已經記錄了日誌。
4. 如果節點A收到響應超過了半數, 節點A就提交資料,通知客戶端資料儲存成功。
5. 節點A在下一次心跳訊息中,通知各個“小弟”該資料已經提交。各個“小弟”也提交自己的資料。
如果某個“小弟”不幸掛掉,那“老大”會不斷地嘗試聯絡它, 一旦它重新開始工作,就需要從“老大”那裡去複製資料,和“老大”保持一致。
4RAFT
張大胖對這個初步的設計還比較滿意,他把這個方案交給領導Bill去審查。
Bill 看了以後,笑道: “你現在其實就是在折騰一個一致性演演算法, 說白了就是允許一組機器像一個整體一樣工作,即使其中一些機器出現故障也能夠繼續工作下去。”
“沒錯沒錯,領導總結得真是精準。” 張大胖拍馬屁。
“不過,”Bill 話鋒一轉, “ 你設計的日誌的複製還有很多漏洞,我看你的設計中一共有5步, 如果在這5步中,那個“老大”節點A掛掉了怎麼辦?資料是不是就不一致了?”
“這個…… ” 張大胖確實沒有仔細考慮。他暗自後悔,只顧低頭拉車,忘了抬頭看路,忽略了分散式環境下的複雜問題。
“不過你已經做得很不錯了,” 領導馬上鼓勵道, “你設計的這一套體系其實和RAFT演演算法非常類似。”
“RAFT? ”
“對,RAFT是個分散式的一致性演演算法,相比複雜難懂的Paxos, RAFT在可理解,可實現性上做了很大的改進。 你這裡的‘老大’,RAFT演演算法叫做Leader, ‘小弟’叫做Follower,不過人家對日誌的複製,以及如何確保資料的一致性有著非常詳細的規定。 ”
張大胖一聽說有現成的演演算法,立刻高興起來: “太好了,分散式的難題已經被別人解決,我去把它實現了。”
後記: 雖然RAFT比Paxos更容易理解, 但是一旦進入各個邊界條件,仍然是非常複雜,所以本文只是介紹了Leader的選舉,和日誌複製的概要流程, 具體的細節還有很多,感興趣的話可以去看看Raft的論文,點選閱讀原文可以檢視中文版。
●編號662,輸入編號直達本文
●輸入m獲取文章目錄

前端開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
