作者: GURCHETAN SINGH 翻譯:張逸 校對:丁楠雅
本文共5800字,建議閱讀8分鐘。
本文從線性回歸、多項式回歸出發,帶你用Python實現樣條回歸。
我剛開始學習資料科學時,第一個接觸到的演演算法就是線性回歸。在把這個方法演演算法應用在到各種各樣的資料集的過程中,我總結出了一些它的優點和不足。
首先,線性回歸假設自變數和因變數之間存線上性關係,但實際情況卻很少是這樣。為了改進這個問題模型,我嘗試了多項式回歸,效果確實好一些(大多數情況下都是如此會改善)。但又有一個新問題:當資料集的變數太多的時候,用多項式回歸很容易產生過擬合。

由於而且我建立的模型總是過於靈活,它可能在測試集上結果很好,但在那些“看不見的”資料上表現的就差強人意了。後來我看到另外一種稱為樣條回歸的非線性方法—它將線性/多項式函式進行組合,用最終的結果來擬合資料。
在這篇文章中,我將會介紹線性回歸、多項式回歸的基本概念,然後詳細說明關於樣條回歸的更多細節以及它的Python實現。
註:為了更好的理解本文中所提到的各種概念,你需要有線性回歸和多項式回歸的基礎知識儲備。這裡有一些相關資料可以參考:
https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression/
本文結構
-
瞭解資料
-
簡單回顧線性回歸
-
多項式回歸:對線性會回歸的改進
-
理解樣條回歸及其實現
-
分段階梯函式
-
基函式
-
分段多項式
-
約束和樣條
-
三次樣條和自然三次樣條
-
確定節點的數量和位置
-
比較樣條回歸和多項式回歸
瞭解資料
為了更好的理解這些概念,我們選擇了工資預測資料集來做輔助說明。你可以在這兒下載:
https://drive.google.com/file/d/1QIHCTvHQIBpilzbNxGmbdEBEbmEkMd_K/view
這個資料集是從一本最近熱門的書《Introduction to Statistical learning》(http://www-bcf.usc.edu/~gareth/ISL/ ISLR%20Seventh%20Printing.pdf)上摘取下來的。
我們的資料集包括了諸如ID、出生年份、性別、婚姻狀況、種族、教育程度、職業、健康狀況、健康保險和工資記錄這些資訊。為了詳細解釋樣條回歸,我們將只用年齡作為自變數來預測工資(因變數)。
讓我們開始吧:
#匯入需要的包
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
#讀入資料
data = pd.read_csv(“Wage.csv”)
data.head()
我們會得到這樣的結果:

繼續:
data_x = data[‘age’]
data_y = data[‘wage’]
#將資料劃分為訓練集和驗證集
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(data_x, data_y, test_size=0.33, random_state = 1)
#對年齡和工資的關係進行視覺化
import matplotlib.pyplot as plt
plt.scatter(train_x, train_y, facecolor=’None’, edgecolor=’k’, alpha=0.3)plt.show()
我們會得到這樣的圖:

看到上邊這個散點圖,你會想到什麼?這到底是代表正相關還是負相關?或者說根本沒有聯絡?大家可以在下方的評論區說說自己的觀點。
介紹線性回歸
線性回歸是預測模型中最簡單同時應用最廣泛的統計方法。它是用來解決基於回歸任務的一種監督學習方法。
這種方法建立了自變數和因變數之間線性的關係,所以被稱為線性回歸。主要是一個線性方程,就像下邊這個式子。可以這麼理解:我們的特徵就是一組帶繫數的自變數。

這個式子中,我們認為Y是因變數,X為自變數,所有的β都是繫數。這些繫數即為對應特徵的權重,表示了每個特徵的重要性。比如說:某個預測的結果高度依賴於諸多特徵中的一個(X1),則意味著與其他所有特徵相比,X1的繫數(即權重)值會更高。
下麵我們來試著理解一下只有一個特徵的線性回歸。即:只有一個自變數。它被稱為簡單線性回歸。對應的式子是這樣的:

前面提到,我們只用年齡這一個特徵來預測工資,所以很顯然,可以在訓練集上應用簡單線性回歸,並且在驗證集上計算該模型的誤差(RMSE)
from sklearn.linear_model import LinearRegression
#擬合線性回歸模型
x = train_x.reshape(-1,1)
model = LinearRegression()
model.fit(x,train_y)
print(model.coef_)
print(model.intercept_)
-> array([0.72190831])
-> 80.65287740759283
#在驗證集上進行預測
valid_x = valid_x.reshape(-1,1)
pred = model.predict(valid_x)
#視覺化
#我們將使用valid_x的最小值和最大值之間的70個點進行繪製
xp = np.linspace(valid_x.min(),valid_x.max(),70)
xp = xp.reshape(-1,1)
pred_plot = model.predict(xp)
plt.scatter(valid_x, valid_y, facecolor=’None’, edgecolor=’k’, alpha=0.3)
plt.plot(xp, pred_plot)
plt.show()
得出影象如下:

現在對預測出的結果算一下RMSE:
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(valid_y, pred))
print(rms)
-> 40.436
從上邊的圖中我們可以看出,線性回歸模型並沒有抓住資料的全部特點,對於工資預測問題來說,這個方法表現的並不理想。
所以結論是,儘管線性模型在描述和實現上比較簡單,並且非常容易理解並應用。但它在預測能力方面還是比較有限。這是因為線性模型假定自變數和因變數之間總是存線上性關係。這個假設是很弱的,它僅僅是近似,而且在有些情況下,近似效果非常差。
在下麵要提到的其他方法中,得把這種線性的假設暫且擱到一邊,但也不能完全拋之腦後。我們會在這個最簡單的線性模型基礎上進行拓展,得到多項式回歸、階梯函式,或者更複雜一點的,比如樣條回歸,也會在下麵進行介紹。
線性回歸的改進:多項式回歸
來看看這樣一組視覺化的圖:

這些圖看起來挖掘出了年齡和工資之間的更多聯絡。它們是非線性的,因為在建立年齡和工資模型的時候使用的是非線性等式。這種使用非線性函式的回歸方法,叫做多項式回歸。
多項式回歸透過增加額外的預測項對簡單線性模型進行了拓展。具體來講,是將每個原始預測項提升了冪次。例如,一個三次回歸使用了這樣三個變數: 作為預測項。它提供了一個簡單的辦法來讓非線性更好的擬合資料。
作為預測項。它提供了一個簡單的辦法來讓非線性更好的擬合資料。
那這種方法是如何做到用非線性模型來代替線性模型,在自變數和因變數之間建立關係的呢?這種改進的根本,是使用了一個多項式方程取代了原來的線性關係。

但當我們增加冪次的值時,曲線開始高頻震蕩。這導致曲線的形狀過於複雜,最終引起過擬合現象。
#為回歸函式生成權重,設degree=2
weights = np.polyfit(train_x, train_y, 2)
print(weights)
-> array([ -0.05194765, 5.22868974, -10.03406116])
#根據給定的權重生成模型
model = np.poly1d(weights)
#在驗證集上進行預測
pred = model(valid_x)
#我們只畫出其中的70個點
xp = np.linspace(valid_x.min(),valid_x.max(),70)
pred_plot = model(xp)
plt.scatter(valid_x, valid_y, facecolor=’None’, edgecolor=’k’, alpha=0.3)
plt.plot(xp, pred_plot)
plt.show()
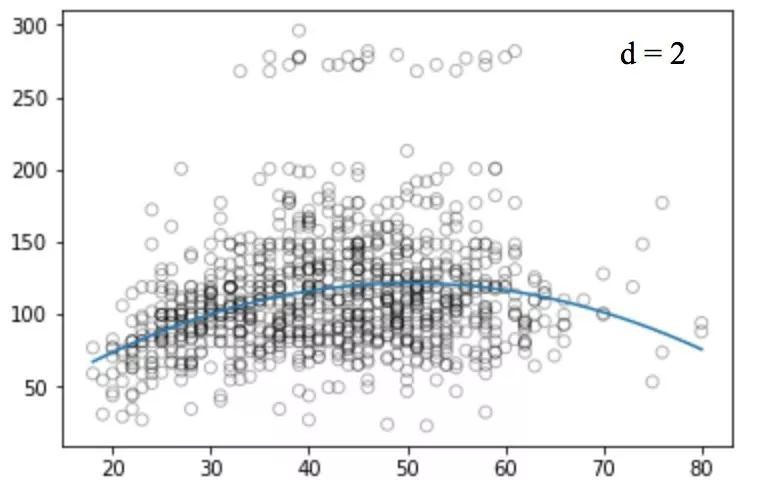
類似的,我們畫出不同degree值對應的圖:


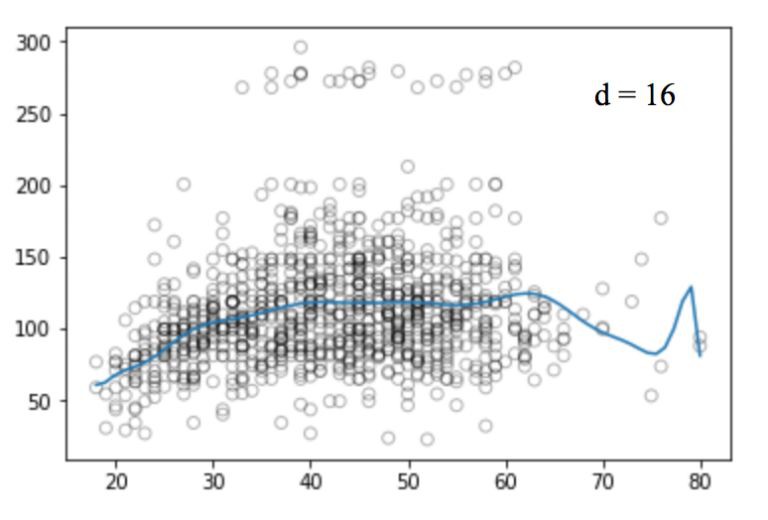

不幸的是,多項式回歸也有很多問題,隨著等式的複雜性的增加,特徵的數量也會增長到很難控制的地步。而且,即便是在上述這個簡單的一維資料集上,多項式回歸也可能會導致過擬合。
除此之外,還有其他問題。比如:多項式回歸本質是非區域性性的。也就是說,在訓練集中改變其中一個點的y值,會影響到離這個點很遠的其他資料的擬合效果。因此,為了避免在整個資料集上使用過高階的多項式,我們可以用很多不同的低階多項式函式來作為替代。
樣條回歸法及其實現
為了剋服多項式回歸的缺點,我們可以用另外一種改進的回歸方法。這種方法沒有將模型應用到整個資料集中,而是將資料集劃分到多個區間,為每個區間中的資料單獨擬合一個模型。這種方法被稱為樣條回歸。
樣條回歸是最重要的非線性回歸方法之一。在多項式回歸中,我們透過在已有的特徵上應用不同的多項式函式來產生新的特徵,這種特徵對資料集的影響是全域性的。為瞭解決這個問題,我們可以根據資料的分佈特點將其分成不同的部分,併在每一部分上擬合線性或低階多項式函式。
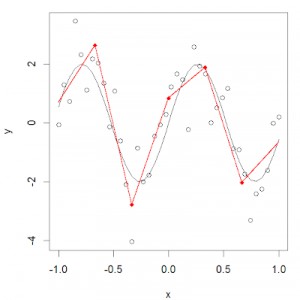
進行分割槽的點被稱為節點。我們可以用分段函式來對每個區間中的資料進行建模。有很多不同的分段函式可以用來擬合這些資料。
在下一小節中,我們會詳細介紹這些函式。
-
分段階梯函式
階梯函式是一種最常見的分段函式。它的函式值在一段時間個區間內會保持一個常數不變。我們可以對不同的資料區間應用不同的階梯函式,以免對整個資料集的結構產生影響。
在這裡我們將X的值進行分段處理,並且對每一部分擬合一個不同的常數。
更具體來講,我們設定分割點C1,C2,…Ck。在X的範圍內構造K+1個新變數。

上圖中的I()是一個指示函式,如果條件滿足,則傳回1,反之則傳回0.比如當Ck≤X時,函式值I(Ck≤X)為1,反之它就等於0.。對於任意給定的值X,C1,C2,…Ck只能有一個值為非零。因為X只能被分到一個區間中。
#將資料劃到四個區間中
df_cut, bins = pd.cut(train_x, 4, retbins=True, right=True)
df_cut.value_counts(sort=False)
->(17.938, 33.5] 504
(33.5, 49.0] 941
(49.0, 64.5] 511
(64.5, 80.0] 54
Name: age, dtype: int64
df_steps = pd.concat([train_x, df_cut, train_y],
keys=[‘age’,’age_cuts’,’wage’], axis=1)
#將講年齡編碼為啞變數
df_steps_dummies = pd.get_dummies(df_cut)
df_steps_dummies.head()

df_steps_dummies.columns = [‘17.938-33.5′,’33.5-49′,’49-64.5′,’64.5-80’]
#擬合廣義線性模型
fit3 = sm.GLM(df_steps.wage, df_steps_dummies).fit()
#同樣將驗證集劃分到四個桶中
bin_mapping = np.digitize(valid_x, bins)
X_valid = pd.get_dummies(bin_mapping)
#去掉離群點
X_valid = pd.get_dummies(bin_mapping).drop([5], axis=1)
#進行預測
pred2 = fit3.predict(X_valid)
#計算RMSE
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(valid_y, pred2))
print(rms)
->39.9
#在這我們只畫出70個觀察點的圖
xp = np.linspace(valid_x.min(),valid_x.max()-1,70)
bin_mapping = np.digitize(xp, bins)
X_valid_2 = pd.get_dummies(bin_mapping)
pred2 = fit3.predict(X_valid_2)
#進行視覺化
fig, (ax1) = plt.subplots(1,1, figsize=(12,5))
fig.suptitle(‘Piecewise Constant’, fontsize=14)
#畫出樣條回歸的散點圖
ax1.scatter(train_x, train_y, facecolor=’None’, edgecolor=’k’, alpha=0.3)
ax1.plot(xp, pred2, c=’b’)
ax1.set_xlabel(‘age’)
ax1.set_ylabel(‘wage’)
plt.show()

但是這種分段的方法有明顯的概念性問題。最明顯的問題是,我們研究的大多數問題會隨著輸入的改變有一個連續變化的趨勢。但這種方法不能構建預測變數的連續函式,因此大多數情況下,應用這種方法,首先得假定輸入和輸出之間沒有什麼關係。
例如在上面的圖表中,我們可以看到,擬合第一個區間的函式顯然沒有捕捉到工資隨年齡的增長而增長的趨勢。
-
基函式
為了捕捉回歸模型中的非線性,我們得變換部分或者全部的預測項。而為了避免將每個自變數視為線性的,我們希望有一個更普遍的“變換族”來應用到預測項中。它應該有足夠的靈活性,以擬合各種各樣形狀的曲線(當模型合適時),同時註意但不能過擬合。
這種可以組合在一起捕捉一般資料分佈的變換被稱為基函式。在這個例子中,基函式是b1(x),b2(x),…,bk(x)
此時,我們擬合的不再是一個線性模型,而是如下所示:

下麵我們來看一個普遍使用的基函式:分段多項式。
-
分段多項式
首先,分段多項式在X的不同範圍內擬合的是不同的低階多項式,而不是像分段階梯函式那樣擬合常數。由於我們使用的多項式次數較低,因此不會觀察到曲線有什麼大的震蕩。
比如:分段二次多項式透過擬合二次回歸方程來起作用:

上式中的繫數β0、β1還有β2在X的不同區間內是取值不一樣的。
一個分段三次多項式,在點C處存在節點,那麼它會具有以下形式:

換句話說,我們在資料上擬合了兩個不同的三次多項式:一個應用於滿足Xi
第一個多項式函式的繫數為: β01, β11, β21, β31,第二個繫數則是 β02, β12, β22, β32。這兩個多項式函式中的每一個都可以用最小均方誤差來擬合。
註意:這個多項式函式有8個自由度,每個多項式有4個(因為是4個變數)。
使用的節點越多,得到的分段多項式就更加靈活,因為我們對X的每一個區間都使用不同的函式,並且這些函式僅僅與該區間中資料的分佈情況相關。一般來說,如果我們在X的範圍內設定K個不同的節點,最終會擬合K+1個不同的三次多項式。 而且我們其實可以使用任何低階的多項式來擬合某一段的資料。比如:可以改用分段線性函式,實際上,上面使用的階梯函式是0階的分段多項式。
下麵我們來看看構建分段多項式時應遵循的一些必要條件和約束。
-
約束和樣條
在使用分段多項式時,我們得非常小心,因為它有很多的限制條件。看看下邊這幅圖:
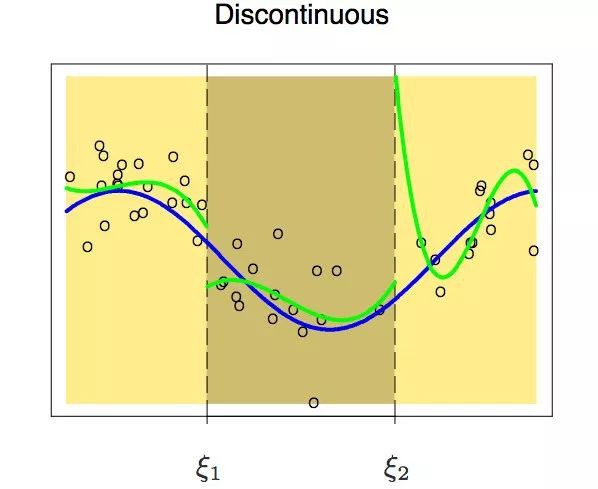
我們可能會遇到這種情況—-節點兩端的多項式在節點上不連續。這是要避免的,因為多項式應該為每一個輸入生成一個唯一的輸出。
上面那幅圖很顯然:在第一個節點處有兩個不同的值。所以,為了避免這種情況,要有一個限制條件:節點兩端的多項式在節點上也必須是連續的。
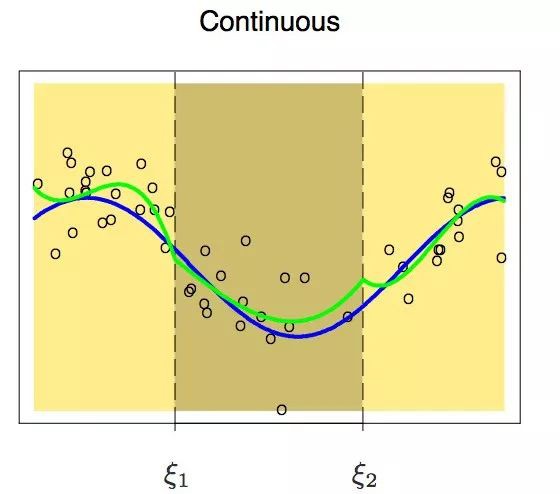
增加這個限制條件之後,我們得到了一組連續的多項式。但這樣就夠了嗎?答案顯然是否定的。在繼續閱讀下文之前,讀者可以先考慮一下這個問題,看看我們是不是漏掉了什麼。
觀察上面的圖可以發現,在節點處,曲線還是不平滑。為了得到在節點處依然光滑的曲線,我們又加了一個限制條件:兩個多項式的一階導數必須相同。要註意的一點是:我們每在分段三次多項式上增加一個約束,都相當於降了一個自由度。因為我們降低了分段多項式擬合的複雜性。因此,在上述問題中,我們只使用了10個自由度而不是12個。
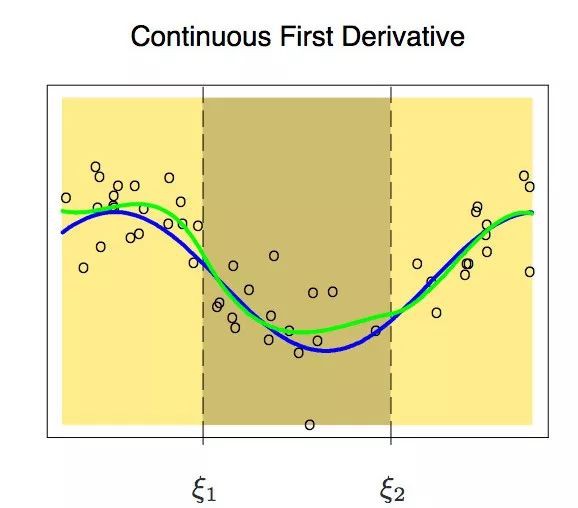
在加上關於一階導數的約束以後,我們得到瞭如上所示的圖形。因為剛才新增加約束的緣故,它的自由度從12個減少到了8個。但即便目前曲線看起來好多了,但還有一些可以改進的空間。現在,我們又要新增加一個約束條件:兩個多項式在節點處的二次導數必須相等。

這次的結果看起來真的是好多了。它進一步將自由度下降為6個。像這樣具有m-1階連續導數的m階多項式被稱為樣條。所以,在上邊的圖中,我們實際上是建立了一個三次樣條。
-
三次樣條和自然三次樣條
三次樣條是具有一組額外約束(連續性、一階導數連續性、二階導數連續性)的分段多項式。通常,一個有K個節點的三次樣條其自由度是4+K。很少會用到比三次還要高階的樣條(除非是對光滑性非常感興趣)
from patsy import dmatrix
import statsmodels.api as sm
import statsmodels.formula.api as smf
#生成一個三節點的三次樣條(25,40,60)
transformed_x = dmatrix(“bs(train, knots=(25,40,60), degree=3, include_intercept=False)”, {“train”: train_x},return_type=’dataframe’)
#在資料集及上擬合廣義線性模型
fit1 = sm.GLM(train_y, transformed_x).fit()
#生成一個4節點的三次樣條曲線
transformed_x2 = dmatrix(“bs(train, knots=(25,40,50,65),degree =3, include_intercept=False)”, {“train”: train_x}, return_type=’dataframe’)
#在資料集上擬合廣義線性模型
fit2 = sm.GLM(train_y, transformed_x2).fit()
#在兩個樣條上均進行預測
pred1 = fit1.predict(dmatrix(“bs(valid, knots=(25,40,60), include_intercept=False)”, {“valid”: valid_x}, return_type=’dataframe’))
pred2 = fit2.predict(dmatrix(“bs(valid, knots=(25,40,50,65),degree =3, include_intercept=False)”, {“valid”: valid_x}, return_type=’dataframe’))
#計算RMSE值
valuesrms1 = sqrt(mean_squared_error(valid_y, pred1))
print(rms1)
-> 39.4
rms2 = sqrt(mean_squared_error(valid_y, pred2))
print(rms2)
-> 39.3
#我們將使用70個點進行圖形的繪製
xp = np.linspace(valid_x.min(),valid_x.max(),70)
#進行一些預測
pred1 = fit1.predict(dmatrix(“bs(xp, knots=(25,40,60), include_intercept=False)”, {“xp”: xp}, return_type=’dataframe’))
pred2 = fit2.predict(dmatrix(“bs(xp, knots=(25,40,50,65),degree =3, include_intercept=False)”, {“xp”: xp}, return_type=’dataframe’))
#畫出樣條曲線和誤差圖
plt.scatter(data.age, data.wage, facecolor=’None’, edgecolor=’k’, alpha=0.1)
plt.plot(xp, pred1, label=’Specifying degree =3 with 3 knots’)
plt.plot(xp, pred2, color=’r’, label=’Specifying degree =3 with 4 knots’)
plt.legend()
plt.xlim(15,85)
plt.ylim(0,350)
plt.xlabel(‘age’)
plt.ylabel(‘wage’)
plt.show()

眾所周知,多項式擬合資料在邊界附近往往表現的很不穩定。這是很危險的。樣條也有類似的問題。那些擬合超出邊界節點資料的多項式比該區域區間中相應的全域性多項式得出的結果更加讓人意外。為了將這種曲線的平滑性延伸到邊界之外的節點上,我們將使用被稱為自然樣條的特殊型別樣條。
自然三次樣條又多一個約束條件,即:要求函式在邊界之外是線性的。這個條件將三次和二次部分變為0,每次自由度減少2個,兩個端點共減少4個自由度,最後k+4減少為k。
#生成自然三次樣條
transformed_x3 = dmatrix(“cr(train,df = 3)”, {“train”: train_x}, return_type=’dataframe’)
fit3 = sm.GLM(train_y, transformed_x3).fit()
#在驗證集上進行預測
pred3 = fit3.predict(dmatrix(“cr(valid, df=3)”, {“valid”: valid_x}, return_type=’dataframe’))
#計算RMSE的值
rms = sqrt(mean_squared_error(valid_y, pred3))
print(rms)
-> 39.44
#選取其中70個點進行作圖
xp = np.linspace(valid_x.min(),valid_x.max(),70)
pred3 = fit3.predict(dmatrix(“cr(xp, df=3)”, {“xp”: xp}, return_type=’dataframe’))
#畫出樣條曲線
plt.scatter(data.age, data.wage, facecolor=’None’, edgecolor=’k’, alpha=0.1)
plt.plot(xp, pred3,color=’g’, label=’Natural spline’)
plt.legend()
plt.xlim(15,85)
plt.ylim(0,350)
plt.xlabel(‘age’)
plt.ylabel(‘wage’)
plt.show()

-
如何選取確定節點的數量和位置
當我們擬合一個樣條曲線時,該如何選取節點呢?一個可行的方法是選擇那些劇烈變化的區域,因為在這種地方,多項式的繫數會迅速改變。所以,可以將在那些我們認為函式值變化劇烈的地方設定更多的節點,在比較穩定的地方少放一些。
不過雖然這種方法雖然效果還可以,但是實際上經常是以一種統一的方式來選取節點。一種方法是指定所需的自由度,然後由軟體自動的將相應數量的節點放在資料的統一分位數處。
或者另一種選擇是改變節點的數量,不斷實踐來測試到底哪一種方案會得到更好的曲線。
當然還有一種更加客觀的做法—–交叉驗證,要是用這種方法,我們要做到以下幾點:
-
取走一部分資料
-
選擇一定數量的節點使樣條能擬合剩下的這些資料
-
再用樣條去預測之前取走的那部分資料
不斷重覆這個過程,直到所有的資料都被取走一次。再計算整個交叉驗證的RMSE。這個過程可以針對不同數量的節點進行重覆,最後我們選擇使得RMSE值最小的那個K值。
-
比較對樣條回歸和多項式回歸進行比較
通常情況下,樣條回歸總是表現得的總是比多項式回歸要好一些。這是因為多項式回歸必須要用很高階的項才能對資料擬合出比較靈活的模型。但是樣條回歸則是透過增加節點的數量做到這一點,同時還保持了階數不變。
而且樣條回歸方法會得到更加穩定的模型。它允許我們在函式變化比較劇烈的地方增加更多節點,反之,函式變化平緩的地方節點就會少一些。多項式模型如果要求更靈活,它就會犧牲邊界上的穩定性,但三次自然樣條卻很好的兼顧了靈活性和穩定性。

結語
在這篇文章中,我們學習了樣條回歸以及其在與線性回歸及多項式回歸相比時的一些優勢。還有另外一種生成樣條的方法叫做平滑樣條。它與Ridge/Lasso正則化類似,乘懲罰結合了損失函式和平滑函式。大家可以在《統計學習入門》一書中閱讀更多的內容。或者你感興趣的話,也可以在一個具有很多變數的資料集上試試看這些方法,親身體會一下個中差異。
譯者補充
本文所有實驗需要的包彙總:
原文標題:Introduction to Regression Splines (with Python codes)
原文連結:https://www.analyticsvidhya.com /blog/2018/03/introduction-regression-splines-python-codes/
譯者簡介:張逸,中國傳媒大學大三在讀,主修數字媒體技術。對資料科學充滿好奇,感慨於它創造出來的新世界。目前正在摸索和學習中,希望自己勇敢又熱烈,學最有意思的知識,交最志同道合的朋友。
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
