實現演演算法
排序歸併連線演演算法大致可以分為以下幾步:
(1)首先以標的SQL中指定的謂詞條件(如果有的話)去訪問表T1,然後對訪問結果按照表T1中的連線列來排序,排好序後的結果集我們記為結果集1。
(2)接著以標的SQL中指定的謂詞條件(如果有的話)去訪問表T2,然後對訪問結果按照表T2中的連線列來排序,排好序後的結果集我們記為結果集2。
(3)最後對結果集1和結果集2執行合併操作。
排序歸併連線可以分為2個過程:排序、歸併。以下介紹的是歸併實現的演演算法。這個演演算法用偽程式碼實現如下:
pr := r的第一個記錄的地址;
ps := s的第一個記錄的地址;
while (ps≠null and pr≠null) do
begin ts := ps所指向的記錄; Ss := { ts };
讓ps指向關係s的下一個記錄; done := false;
while (not done and ps≠null) do
begin ts’:= ps所指向的記錄;
if (ts’[JoinAttrs] = ts [JoinAttrs])
then begin Ss := Ss∪{ ts’};
讓ps指向關係s的下一個記錄;
end
else done := true;
end(在連線屬性上具有相同值的S記錄被加入到了Ss中。Ps指向在連線屬性上具有另一個值的S記錄。)
這段偽程式碼看的人頭大,用圖來進行解釋就很好理解了。假設記錄集T1、T2已經排好序,為了簡單起見,只顯示T1和T2在連線列上的取值。假設為等值連線,大致過程如下:
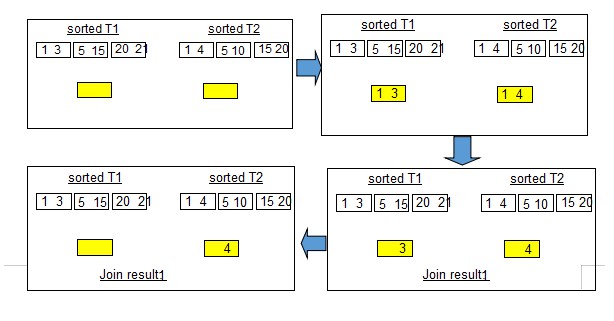
假設記憶體中有2個BUFFER,一個BUFFER能容納2個記錄,取出T1的(1,3)和T2的(1,4)進行比較,此時只有(1,1)是匹配的,把1所在的記錄放到結果集中,3,4不匹配,那麼接下來再取出記錄集中的其他值:
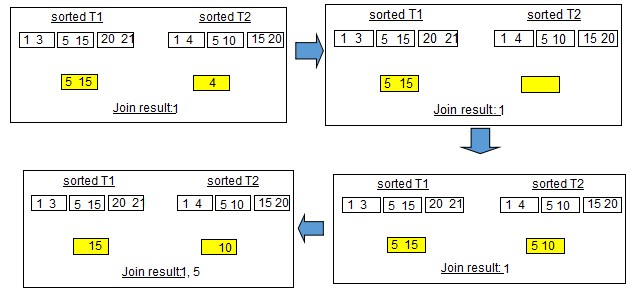
此時可能會有疑問:3和4怎麼沒了呢?這是因為T2中剩下最小的值是4,由於我們的假設是等值連線,那麼顯然,3捨棄。同理捨棄4。接下來就是新的一輪迴圈啦,直到兩個表比較完成。
表訪問過程
排序歸併連線每個表最大的訪問次數為1,這個訪問次數是為了根據WHERE子句中的條件篩選和過濾出用於歸併的記錄集,歸併過程是對排序過程篩選出來的BUFFER進行操作的。
構造表T1和T2,構造過程略,表的記錄數:
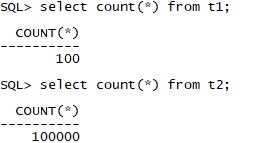
為了得到真實的執行計劃,尤其是表訪問次數,我選擇了alter session set statistics_level=all 來獲取執行計劃。
執行查詢陳述句:
SELECT /*+ leading(t1) use_merge(t2)*/ *
FROM t1, t2
WHERE t1.id = t2.t1_id;
這裡HINT裡使用了LEADING,實際上只是指定了首先進行排序操作的表,並非驅動表。
獲取執行計劃:
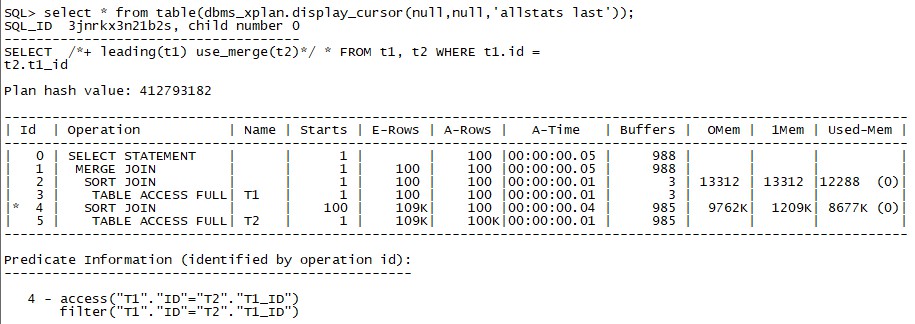
表T1和表T2都只訪問了一次,如果查詢一個T1中不存在的值那麼執行計劃為
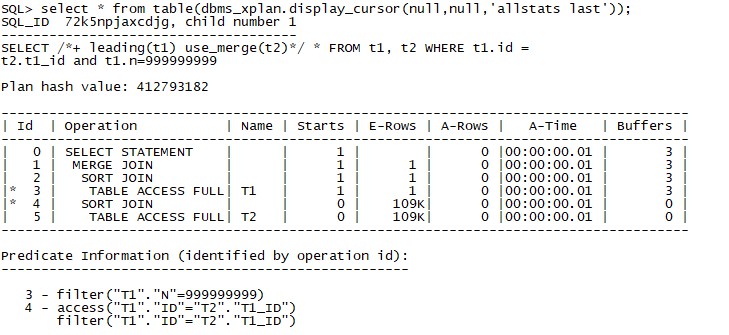
T1表訪問次數為1,T2表訪問次數為0,可以看到BUFFERS的訪問數目為3,是在步驟3中產生的,步驟4和5的BUFFERS都是0,也就是說,T1表即LEADING表沒有傳回值時,不會再去訪問T2。如果修改HINT,使T2成為驅動表,那麼執行計劃就不一樣了:
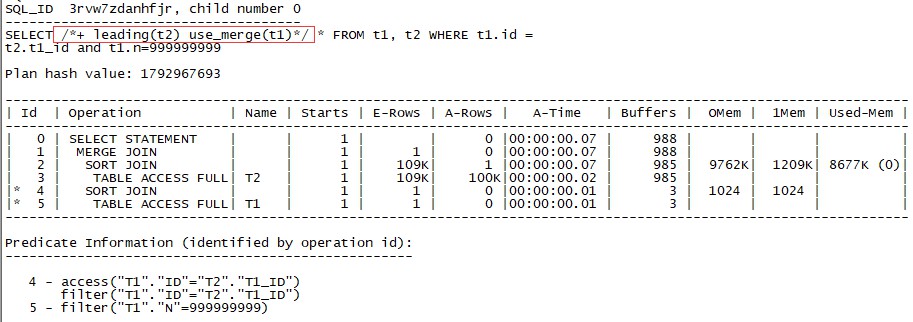
這時候相比於使用T1作為驅動表,耗費的資源要多很多,包括記憶體消耗、邏輯讀、以及執行時間都大大增漲。
嘗試一種特殊的情況:
SELECT /*+ leading(t2) use_merge(t1)*/ *
FROM t1, t2
WHERE t1.id = t2.t1_id
and 1=2;
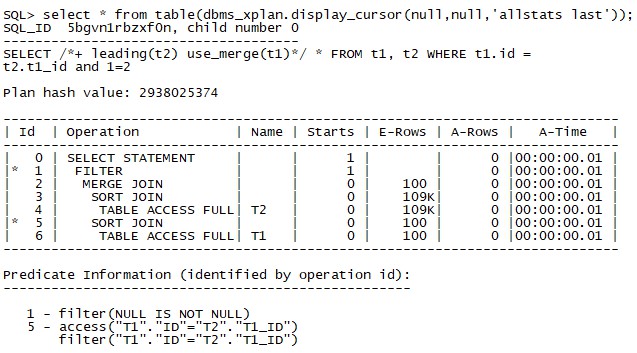
此時表的訪問次數都為0。這是因為限制條件中有一個永假的條件: AND 1=2,最佳化器此時會聰明地繞過表的訪問,直接訪問資料字典(filter(NULL IS NOT NULL)),傳回結果為表的結構。