來自:51CTO技術棧(微訊號:blog51cto)
作者:Jay Runkel,陳峻編譯
原文連結:https://dzone.com/articles/active-active-application-architectures-with-mongo、https://dzone.com/articles/active-active-application-architectures-with-mongo-1
投資界有一句至理名言——“不要把雞蛋放在同一個籃子裡”。說的是投資需要分解風險,以免孤註一擲失敗之後造成巨大的損失。

隨著企業服務視窗的不斷增加,業務中斷對很多企業意味著毀滅性的災難,因此,跨多個資料中心的應用部署成為了當下最熱門的話題之一。
如今,在跨多個資料中心的應用部署最佳實踐中,資料庫通常負責處理多個地理區域的讀取和寫入,對資料變更的複製,並提供盡可能高的可用性、一致性和永續性。
但是,並非所有的技術在選擇上都是平等的。例如,一種資料庫技術可以提供更高的可用性保證,卻同時只能提供比另一種技術更低的資料一致性和永續性保證。
本文先分析了在現代多資料中心中應用對於資料庫架構的需求。隨後探討了資料庫架構的種類及優缺點,最後專門研究 MongoDB 如何適用於這些類別,並最終實現雙活的應用架構。
雙活的需求
當組織考慮在多個跨資料中心(或區域雲)部署應用時,他們通常會希望使用“雙活”的架構,即所有資料中心的應用伺服器同時處理所有的請求。
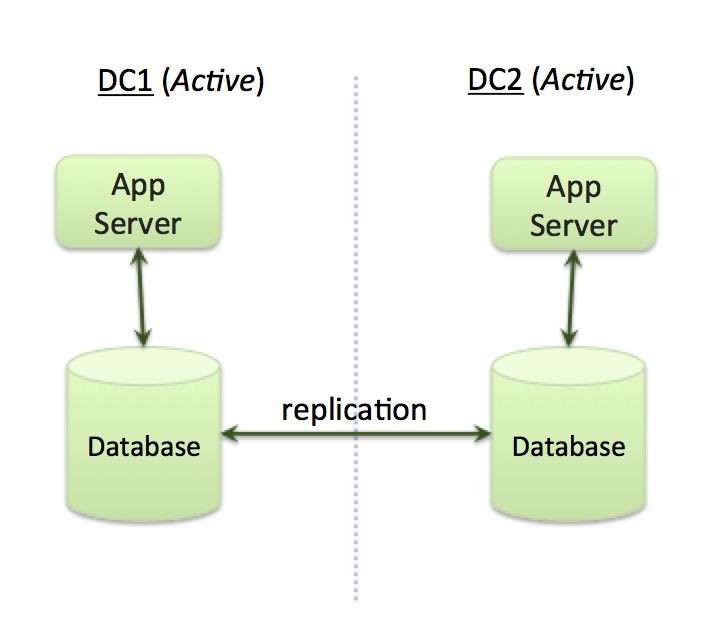
圖 1:“雙活”應用架構
如圖 1 所示,該架構可以實現如下標的:
-
透過提供本地處理(延遲會比較低),為來自全球的請求提供服務。
-
即使出現整個區域性的宕機,也能始終保持高可用性。
-
透過對多個資料中心裡伺服器資源的並行使用,來處理各類應用請求,並達到最佳的平臺資源利用率。
“雙活”架構的替代方案是由一個主資料中心(區域)和多個災備(DR)區域(如圖 2 所示)所組成的主-DR(也稱為主-被)架構。
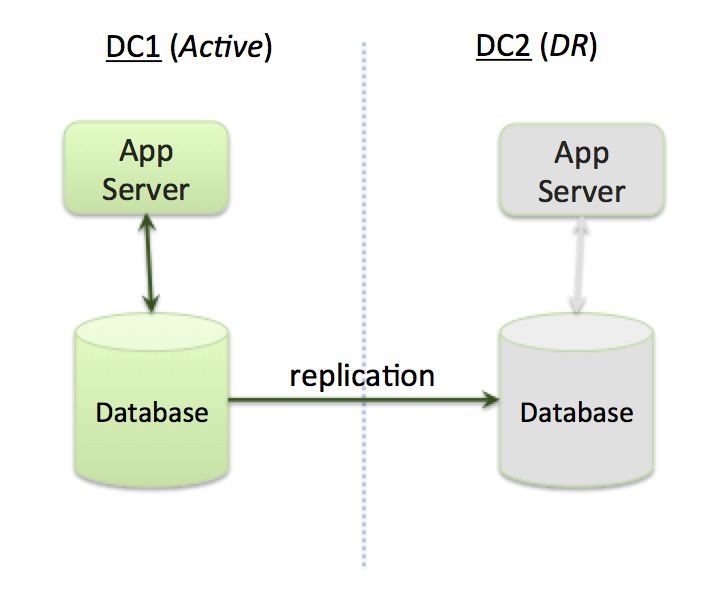
圖 2:主-DR 架構
在正常執行條件下,主資料中心處理請求,而 DR 站點處於空閑狀態。如果主資料中心發生故障,DR 站點立即開始處理請求(同時變為活動狀態)。
一般情況下,資料會從主資料中心複製到 DR 站點,以便在主資料中心出現故障時,能夠迅速實施接管。
如今,對於雙活架構的定義尚未得到業界的普遍認同,上述主-DR 的應用架構有時也被算作“雙活”。
區別在於從主站到 DR 站點的故障轉移速度是否夠快(通常為幾秒),並且是否能夠自動化(無需人為幹預)。在這樣的解釋中,雙活體系架構意味著應用停機時間接近於零。
有一種常見的誤解,認為雙活的應用架構需要有多主資料庫。這樣理解是錯誤的,因為它曲解了多個主資料庫對於資料一致性和永續性的把握。
一致性確保了能讀取到先前寫入的結果,而資料永續性則確保了提交的寫入資料能夠被永久儲存,不會產生衝突寫入;或是由於節點故障所產生的資料丟失。
雙活應用的資料庫需求
在設計雙活的應用架構時,資料庫層必須滿足如下四個方面的架構需求(當然,也要具備標準資料庫的功能,如具有:豐富的二級索引能力的查詢語言,低延遲地訪問資料,本地驅動程式,全面的操作工具等):
-
效能,低延遲讀取和寫入操作。這意味著:能在本地資料中心應用的節點上,處理讀取和寫入操作。
-
資料永續性,透過向多個節點的複製寫入來實現,以便在發生系統故障時,資料能保持不變。
-
一致性,確保能讀取之前寫入的結果,而且在不同地區和不同節點所讀到的結果應該相同。
-
可用性,當某個節點、資料中心或網路連線中斷時,資料庫必須能繼續執行。另外,從此類故障中恢復的時間應盡可能短,一般要求是幾秒鐘。
分散式資料庫架構
針對雙活的應用架構,一般有三種型別的資料庫結構:
-
使用兩步式提交的分散式事務。
-
多主資料庫樣式,有時也被稱為“無主庫樣式”。
-
分割(分片)資料庫具有多個主分片,每個主分片負責資料的某個唯一片區。
下麵讓我們來看看每一種結構的優缺點。
兩步式提交的分散式事務
分散式事務方法是在單次事務中更新所有包含某個記錄的節點,而不是寫完一個節點後,再(非同步)複製到其他節點。
該事務保證了所有節點都會接收到更新,否則如果某個事務失敗,則所有節點都恢復到之前的狀態。
雖然兩步式提交協議可以確保永續性和多節點的一致性,但是它犧牲了效能。
兩步式提交協議要求在事務中所有參與的節點之間都要進行兩步式的通訊。即在操作的每個階段,都要傳送請求和確認,以確保每個節點同時完成了相同的寫入。
當資料庫節點分佈在多個資料中心時,會將查詢的延遲從毫秒級別延長到數秒級別。
而在大多數應用,尤其是那些客戶端是使用者裝置(移動裝置、Web 瀏覽器、客戶端應用等)的應用中,這種響應級別是不可接受的。
多主資料庫
多主資料庫是一種分散式的資料庫,它允許某條記錄只在多個群集節點中一個之上被更新。而寫操作通常會複製該記錄到多個資料中心的多個節點上。
從錶面上看,多主資料庫應該是實現雙活架構的理想方案。它使得每個應用伺服器都能不受限地讀取和寫入本地資料的副本。但是,它在資料一致性上卻有著嚴重的侷限性。
由於同一記錄的兩個(或更多)副本可能在不同地點被不同的會話同時更新。這就會導致相同的記錄會出現兩個不同的版本,因此資料庫(有時是應用本身)必須透過解決衝突來解決不一致的問題。
常用的衝突解決策略是:最近的更新“獲勝”,或是具有更多修改次數的記錄“獲勝”。因為如果使用其他更為複雜的解決策略,則效能上將受到顯著的影響。
這也意味著,從進行寫入到完成衝突解決機制的這個時間段內,不同的資料中心會讀取到某個相同記錄的不同值和衝突值。
分割槽(分片)資料庫
分割槽資料庫將資料庫分成不同的分割槽,或稱為分片。每個分片由一組伺服器來實現,而每個伺服器都包含一份分割槽資料的完整副本。這裡關鍵在於每個分片都保持著對資料分割槽的獨有控制權。
對於任何給定時間內的每個分片來說,由一臺伺服器充當主伺服器,而其他伺服器則充當其副本。資料的讀取和寫入被髮布到主資料庫上。
如果主伺服器出於任何原因的(例如硬體或網路故障)失敗,則某一臺備用伺服器會自動接任為主伺服器的角色。
資料庫中的每條記錄都屬於某個特定的分割槽,並由一個分片來進行管理,以確保它只會被主分片進行寫入。分片內的記錄對映到每個分片的一個主分片,以確保一致性。
由於叢集內包含多個分片,因此會有多個主分片(多個主分割槽),因此這些主分片可以被分配到不同的資料中心,以確保都在每個資料中心的本地都能發生寫入操作,如圖 3 所示:

圖 3:分割槽資料庫
分片資料庫可用於實現雙活的應用架構,其方法是:至少部署與資料中心一樣多的分片,併為分片分配主分片,以便每個資料中心至少有一個主分片,如圖 4 所示:
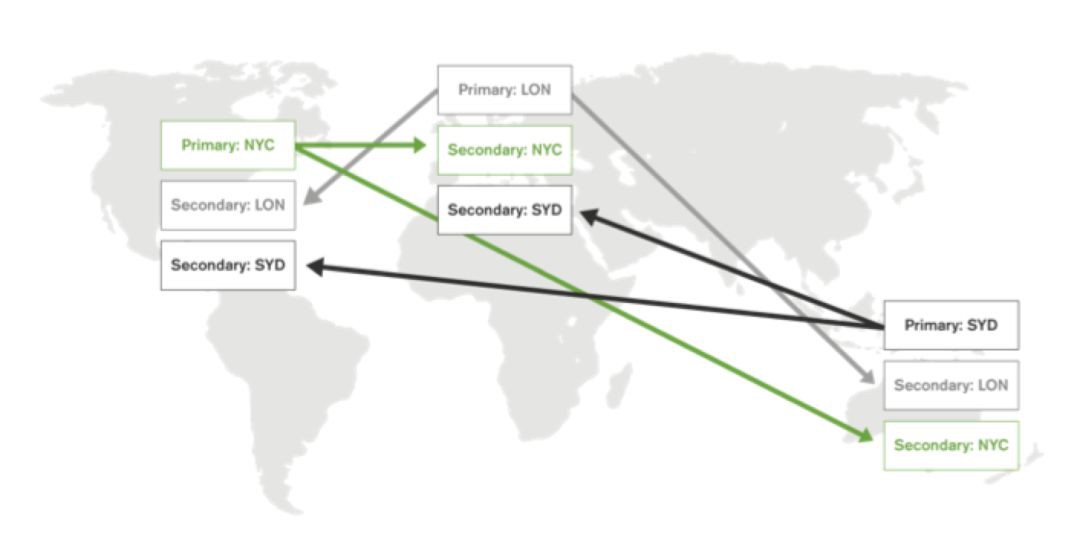
圖 4:具有分片資料庫的雙活架構
另外,透過配置分片能保證每個分片在各種資料中心裡至少有一個副本(資料的副本)。
例如,圖 4 中的圖表描繪了跨三個資料中心的分散式資料庫架構:
-
紐約(NYC)
-
倫敦(LON)
-
悉尼(SYD)
群集有三個分片,每個分片有三個副本:
-
NYC 分片在紐約有一個主分片,在倫敦和悉尼有副本。
-
LON 分片在倫敦有一個主分片,在紐約和悉尼有副本。
-
SYD 分片在悉尼有一個主分片,在倫敦和紐約有副本。
透過這種方式,每個資料中心都有來自所有分片的副本,因此本地應用伺服器可以讀取整個資料集和一個分片的主分片,以便在其本地進行寫入操作。
分片資料庫能滿足大多數使用場景的一致性和效能要求。由於讀取和寫入發生在本地伺服器上,因此效能會非常好。
從主分片中讀取時,由於每條記錄只能分配給一個主分片,因此保證了一致性。
例如:我們在美國的新澤西州和俄勒岡州有兩個資料中心,那麼我們可以根據地理區域(東部和西部)來分割資料集,並將東海岸使用者的流量路由到新澤西州的資料中心。
因為該資料中心包含的是主要用於東部的分片;並將西海岸使用者的流量路由到俄勒岡州資料中心,因為該資料中心包含的是主要用於西部的分片。
我們可以看到分片的資料庫為我們提供了多個主資料庫的所有好處,而且避免了資料不一致所導致的複雜性。
應用伺服器可以從本地主伺服器上進行讀取和寫入,由於每個主伺服器擁有各自的記錄,因此不會出現任何的不一致。相反,多主資料庫的解決方案則可能會造成資料丟失和讀取的不一致。
資料庫架構比較

圖 5:資料庫架構比較
圖 5 提供了每一種資料庫架構在滿足雙活應用需求時所存在的優缺點。在選擇多主資料庫和分割槽資料庫時,其決定因素在於應用是否可以容忍可能出現的讀取不一致和資料的丟失問題。
如果答案是肯定的,那麼多主資料庫可能會稍微容易部署些。而如果答案是否定的,那麼分片資料庫則是最好的選擇。
由於不一致性和資料丟失對於大多數應用來說都是不可接受的,因此分片資料庫通常是最佳的選擇。
MongoDB 雙活應用
MongoDB 是一個分片資料庫架構的範例。在 MongoDB 中,主伺服器和次伺服器集的構造被稱為副本集。副本集為每個分片提供了高可用性。
一種被稱為區域分片(Zone Sharding)的機制被配置為:由每個分片去管理的資料集。如前面所提到的,ZoneSharding 可以實現地域分割槽。
白皮書《MongoDB多資料中心部署》:
-
https://www.mongodb.com/collateral/mongodb-multi-data-center-deployments?utm_medium=dzone-synd&utm;_source=dzone&utm;_content=active-application&jmp;=dzone-ref
Zone Sharding 相關檔案:
-
https://docs.mongodb.com/manual/tutorial/sharding-segmenting-data-by-location/的“分割槽(分片)資料庫”部分描述了 MongoDB 具體實現和運作的細節。
其實許多組織,包括:Ebay、YouGov、Ogilvyand Maher 都正在使用 MongoDB 來實現雙活的應用架構。
除了標準的分片資料庫功能之外,MongoDB 還提供對寫入耐久性和讀取一致性的細粒度控制,並使其成為多資料中心部署的理想選擇。對於寫入,我們可以指定寫入關註(write concern)來控制寫入的永續性。
Writeconcern 使得應用在 MongoDB 確認寫入之前,就能指定寫入的副本數量,從而在一個或多個遠端資料中心內的伺服器上完成寫入操作。籍此,它保證了在節點或資料中心發生故障時,資料庫的變更不會被丟失。
另外,MongoDB 也補足了分片資料庫的一個潛在缺點:寫入可用性無法達到 100%。
由於每條記錄只有一個主節點,因此如果該主節點發生故障,則會有一段時間不能對該分割槽進行寫入。
MongoDB 透過多次嘗試寫入,大幅縮短了故障切換的時間。透過多次嘗試的寫入操作,MongoDB 能夠自動應對由於網路故障等暫時性系統錯誤而導致的寫入失敗,因此也大幅簡化了應用的程式碼量。
MongoDB 的另一個適合於多資料中心部署的顯著特徵是:MongoDB 自動故障切換的速度。
當節點或資料中心出現故障或發生網路中斷時,MongoDB 能夠在 2-5 秒內(當然也取決於對它的配置和網路本身的可靠性)進行故障切換。
發生故障後,剩餘的副本集將根據配置去選擇一個新的主切片和 MongoDB 驅動程式,從而自動識別出新的主切片。一旦故障切換完成,其恢復行程將自動履行後續的寫入操作。
對於讀取,MongoDB 提供了兩種功能來指定所需的一致性級別。
首先,從次資料進行讀取時,應用可以指定最大時效值(maxStalenessSeconds)。
這可以確保次節點從主節點複製的滯後時間不能超過指定的時效值,從而次節點所傳回的資料具有其時效性。
另外,讀取也可以與讀取關註(ReadConcern)相關聯,來控制查詢到的傳回資料的一致性。
例如,ReadConcern 能透過一些傳回值來告知 MongoDB,那些被覆制到副本集中的多數節點上的資料。
這樣可以確保查詢只讀取那些沒有因為節點或資料中心故障而丟失的資料,並且還能為應用提供一段時間內資料的一致性檢視。
MongoDB 3.6 還引入了“因果一致性(causal consistency)”的概念,以保證客戶端會話中的每個讀取操作,都始終只“關註”之前的寫入操作是否已完成,而不管具體是哪個副本正在為請求提供服務。
透過在會話中對操作進行嚴格的因果排序,這種因果一致性可以確保每次讀取都始終遵循邏輯上的一致,從而實現分散式系統的單調式讀取(monotonic read)。而這正是各種多節點資料庫所無法滿足的。
因果一致性不但使開發人員,能夠保留過去傳統的單節點式關係型資料庫,在實施過程中具備的資料嚴格一致性的優勢;又能將時下流行架構充分利用到可擴充套件和具有高可用性的分散式資料平臺之上。

譯者,陳峻(Julian Chen) ,有著十多年的 IT 專案、企業運維和風險管控的從業經驗,日常工作深入系統安全各個環節。作為 CISSP 證書持有者,他在各專業雜誌上發表了《IT運維的“六脈神劍”》、《律師事務所IT服務管理》 和《股票交易網路系統中的安全設計》等論文。他還持續分享並更新《廉環話》系列博文和各種外文技術翻譯,曾被(ISC)2 評為第九屆亞太區資訊保安領袖成就表彰計劃的“資訊保安踐行者”和 Future-S 中國 IT 治理和管理的 2015 年度踐行人物。
●編號312,輸入編號直達本文
●輸入m獲取文章目錄

大資料與人工智慧
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
