來自:51CTO技術棧(微訊號:blog51cto)
作者:鄭永寬
大家熟知的京東可能是京東電商,事實上京東有四個最主要的平臺:電商、物流、金融和保險,京東雲是這些平臺能力的輸出視窗。京東雲有基礎設施、主機網路,上面還有一些中介軟體和 PaaS 服務,主要是為了支撐電商和物流。

2017 年 12 月 1 日-2 日,由 51CTO 主辦的 WOTD 全球軟體開發技術峰會在深圳中州萬豪酒店隆重舉行。
京東雲資深架構師在主會場與來賓分享了”京東雲自動化運維體系構建”的主題演講,以下是演講實錄。
說到京東雲,我們最看重運維,需要自動化運維平臺。對此有幾個關鍵問題,主要是圍繞安全、部署變更、網路管理、監控管理……利用自動化運維來提高平臺架構穩定性和人員的開發效率。
在京東雲的整體環境中,除了有我們技術團隊所管理和維護的雲自身應用之外,還啟用並提供著各種 SaaS 服務。
如何保持客戶在雲端業務的穩定性?我們對此進行了深入的研究和探索,下麵分四個部分為大家講解:
-
京東雲自動化運維基礎元件
-
京東雲自動化運維部署介紹
-
京東雲自動化運維監控系統
-
總結與展望
京東雲自動化運維基礎元件

針對上述問題,我們從四個方面進行入手:
-
服務與資源管理
-
任務排程管理
-
監控平臺
-
客戶端
如上圖所示,京東雲運維平臺大致的搭建路線圖為:基礎元件→客戶端體系 →部署系統(包括:各種釋出系統、任務排程系統、以及監控系統),最終對運維平臺進行完善,從而更好地服務於我們的客戶。
服務與資源管理
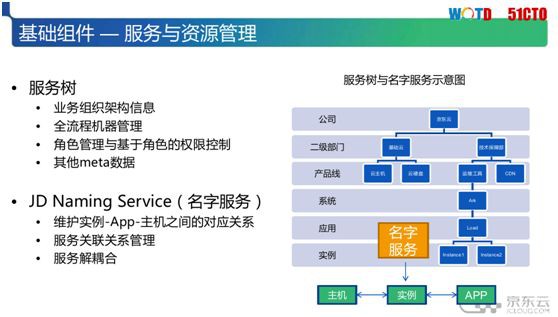
首先我們來看第一個基礎元件:對於服務組織資源的管理,即運用 CMDB 來實現所謂的配置管理。
透過 CMDB 的“服務樹”概念,我們可以掌握如下三個方面:
-
找到各個服務項之間的依賴關係,進而獲知它們在哪裡被用到、由誰在使用、以及其本身所具備的用處。
-
機器狀態。對於京東這樣體量的大公司而言,機器的數量多達十萬左右,我們需要掌握其中每一臺機器的當前狀態、具體的機型、坐落在哪個機房、以及它們是如何被使用的。
-
角色管理與基於角色的許可權控制,我們需要掌握到具體是誰、能夠在什麼時候、進行什麼樣的操作、實現什麼功能。
所以說,“服務樹”主要涉及到服務在系統中的實時資訊,包括:哪個服務處於哪臺機器之上,有哪些實體,屬於哪個 App,具有哪些內部邏輯過程,如何對外部申請所需的許可權,以及我們如何實現對它的監控等。這些都需要能從伺服器上獲取到。
其次是 Naming service,它能夠解決服務之間的解耦關係,也就是服務和實體間的關聯關係、以及服務向外所提供的視窗。
上圖右側展示了“服務樹”與名字服務的示意圖,最下方展示了一個從應用到實體關係的解耦,往上則是客戶端的 back off(解耦合)。
任務排程管理

第二個基礎元件是任務排程管理。在實際場景中,不管我們是要協同做某個操作、還是進行釋出上線、或是對檔案進行部署與分發。
這些都需要系統去排程標的機器,以完成相應的任務,也就是我們必須要求指定的機器能夠按照指定的策略,進行指定的命令。由於該過程具有實時性、批次性和共生性,因此對於系統的支撐能力極具挑戰性。
同時,我們需要透過策略來定義不同型別的併發度,比如要對一百臺機器進行釋出上線,那麼我們不會將它們予以同時部署,而是分批次地進行併發。
因此我們需要規定每次併發的具體任務,判定成功與否的邏輯關係,以及檢驗具體的完成程度,並且還要找出那些超時的狀態。由於這些都是透過底層架構來構建出的各種業務,所以它們的排程邏輯實際上都是一樣的。
另外,所有的執行操作都需要是可追溯的,包括能夠知曉什麼人、在什麼時間、進行了什麼操作,可見安全性和規範性是非常重要的。
而如果出現了故障,我們需要及時地截獲輸出,進而定位問題。這些都是任務排程系統需要基於服務樹和 Naming Service 來實現的基礎邏輯。
監控平臺
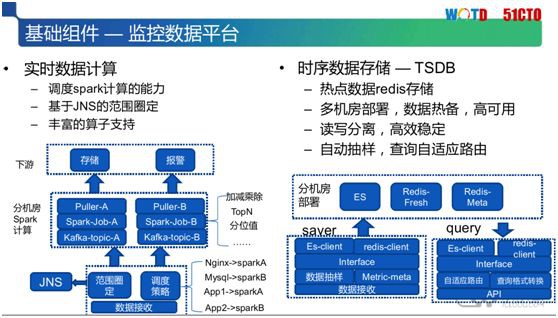
第三個基礎元件就是監控平臺。監控無非是從資料採集、到資料匯聚、再到儲存處理的過程。
不同於平時常見的資料監控,我們構建的是時序性資料儲存(TSDB)。由於需要查詢的資料點非常多,因此我們將每次查詢和收集到的監控點資訊按照順序儲存起來。
另外,我們的系統具有“讀少寫多”的特點,即:“寫”(寫入資料)相對比較均衡;而“讀”(讀取資料)則具有突發性。
比如說:檢視一個監控的狀態,是屬於隨時做的操作。一般此類寫操作是以 1 秒、10 秒、或 1 分鐘作為採集間隔,是一個比較頻發的過程。而讀操作則發生得比較突兀,所以我們需要做到讀寫分離。
因此,我們基於 ES(elasticsearch)實現了 TSPD,其中涉及到兩種封裝:
-
對於熱點資料的封裝,我們將較為重要的資料,以及那些實時的資料存放在 Redis 中。
-
同樣,我們對歷史資料也會進行 ES,然後再封裝,從而實現了讀寫的分離。這種資料的雙寫過程,合理地保證了資料的高可用。
監控資料的另一個特點是自動抽樣,有時候一些頻發的查詢會牽扯到較大的時間跨度。
例如:一個月甚至是一年。由於我們的採集資料間隔是 1 秒、10 秒、或 1 分鐘,那麼如果直接去查詢所有資料點,需要產生龐大的資料量,當然也就很難實現。
因此,我們對寫操作進行了自動抽樣。當查詢 15 天以上的資料時,我們會把這些資料以每分鐘、或每小時進行聚合,然後放在庫中,進而查詢一個月的資料。
透過自適應路由的方式,我們就可以查到有限量的一小時資料,同時我們的資料庫、以及業務系統速度也能具有較快的水平。
另外,對於那些實時的資料處理,我們主要採用的是多地部署和基於JNS的多排程過程,從而實現了多維度的實時計算。
客戶端

第四個基礎元件就是客戶端,由於所有的業務都需要客戶端,因此對於京東這樣體量的公司而言,會細分為部署類(如 JNS)、監控類、初始化等客戶端型別。
設想一下,如果我們需要對十萬臺機器進行載入部署或是上線升級,其工作量是可想而知的。
就算我們只是維護十幾萬機器的 Agent,由於環境複雜,且存在著多個IP,如果只是按照單一維度去處理諸如“什麼時候、出現什麼了問題”的話,既耗時又耗力。
所以在此我們引入了 Agent 的資源超限這一重要概念。比如說:對 Agent 的監控,由於佔有了部分計算資源,則有可能將當前的服務宕機,那麼這種本身處於服務之外的監控就影響到了服務本身的穩定性。
可見對於 Agent 客戶端需要做到如下方面:
-
管理所有 Agent 的部署和升級。
-
維護各個 Agent 的存活性。即在發現哪臺機器上的 Agent 宕機的時候,我們需要知道如何將其重新啟用上線。
-
資源超限守護。
-
分級釋出。
在具體實現上,我們運用 ifrit 進行管控。即當一臺機器在引入某個服務時,負責管理的 Agent 會在我們的 ifrit 伺服器上進行註冊,以告知其當前所處的分機房和使用的 Agent 的版本。
那麼它對應的客戶端就可以相應地將這些資訊包下載下來,從而掌握 Agent 的最新版本等資訊。這就形成了一個簡單的客戶端體系結構。
京東雲自動化運維部署介紹

有了上述客戶端與元件體系的構建基礎,我們進一步構建部署和釋出任務就相對比較容易了。
我們先看看應用的部署系統。它除了實現應用部署之外,還管理著各種服務的維護和資源、以及接入的過程。
如上圖所示:我們除了“往前”進行了編譯構建,還“往後”實現了流量接入。

如上圖所示,該 Agent 在此處有著一個核心的要求:實現跨平臺。由於京東整體平臺的環境較為複雜,我們有不同的虛擬機器、Docker、物理機,它們需要把前面所提到的多種操作融合起來。
因此我們需要做到如下容錯功能:
-
不允許出現由於單臺宕機而引發服務故障。
-
出現了服務故障,系統可以實現自我發現。
-
面對雙十一和 618 之類的重要促銷場景。系統能夠快速擴容,以應對此類流量的驟增。

針對上述功能的實現,我們在部署中分為兩種型別:
-
基於 Docker 的映象輸出。
-
基於傳統物理機或虛擬機器的包輸出。
一般的流程是:編譯構建自身產品庫(其中包含程式碼包和程式碼項)→透過部署服務和上述排程系統的部署服務進行釋出(在物理機和容器上都可實現)→部署完成開始執行→對執行予以維護(尤其對映象日誌進行收集)→透過日誌服務,進一步做分析。
同時我們在前端做好了流量的接入,中間部分也提供了一個 LB(負載均衡)的網路。透過上述兩種部署方式,我們可以根據服務的實際需要進行按需升級。
另外,我們此處採用的是基於 NS 的服務自動化與資源管理。它並不需要關心當前服務的具體過程是如何被實現的,而只註重:當前的容量、需要什麼資源、以及能夠獲得的資源。
京東雲自動化運維監控系統

除了上述提到的部署,我們對監控系統也十分重視。監控最重要的作用就是在出現問題時能夠及時恢復。
要實現這一點就必須做到如下方面:
-
能在第一時間發現問題,這是恢復的基礎。
-
快速定位問題,及時判斷問題出在哪裡,是虛擬機器上還是硬體上。
-
能夠自動運用既定的演演算法,透過自動排程預案或人工響應予以快速處理和恢復。
因此,面對既有虛擬機器又有 Docker 的複雜環境,為了保證伺服器不停止執行,我們在上線過程中採用的是部署聯動式的分級釋出。
它可以監控到某個服務是處於機器層、服務層,還是在對外流量接入層、甚至是在網路層。這些都是監控所需要解決的問題。

上圖是監控的整體架構,這裡展示了從底層的資料抽象、到資料的採集,然後經過資料處理,以及離線處理的全過程。
其中資料的採集樣式包括:採集 Agent、外部探測和 API 推送。
同時在處理邏輯上包括了:如何去判斷異常型別,以及針對異常所做出的報警型別和採取的是運維通訊還是研發通訊等方式。我們對這些步驟都事先進行了較好的規劃。
當然,這些故障本身又屬於事件型別。因此我們需要考慮如何將事件儲存起來,以方便查詢和進一步做出相應的決策。
由於先前的事件可能會影響到後續事件,因此如果您擁有一個很好的事件庫,那麼就能夠讓系統的下游獲取到上游究竟是何時何地出現了何種故障,這些對於下游的排障都是極有幫助的。
與此同時,我們也會對監控的資料進行一些離線處理,透過各種高效的演演算法,反饋到計算相應的報警之中。最終各種資料都是以趨勢圖或 Dashboard 的方式來展示各種事件和報警。

有了前面的基礎,我們所構建的京東雲監控體系就由如下四種監控型別組成:
-
基礎監控,針對的是機器層面,不需要使用者去配置,自動採集的是 CPU、記憶體、硬碟、網路等簡單的資訊。
-
存活監控,針對的是服務監控,包括監控行程、埠和語意等方面。
-
效能監控,針對的是服務層的對外表現狀況。我們透過四大核心指標,來解決服務效能上是否存在異常。同時我們運用日誌監控來收集pv、錯誤和容量,並確定所謂的異常邊界的問題。
-
業務監控,類似於黑盒子,從使用者的角度來觀察服務,發現問題。例如:所有服務指標狀態都顯示 OK,但是服務對外表現不佳,網站無法被訪問。
這個問題實際上對於京東來說會非常地嚴重,因為它會直接影響到使用者流量乃至使用者訂單的損失,所以我們要從使用者的層面上做好黑盒檢測。
基礎監控

具體來說,對於機器監控,我們從採集、到計算、再到報警,實現了機器連通性的全程自動化,從而免於人工的幹預。
同時我們給各種報警指標設定了預設值,比如說:透過發現某臺機器的 cpu.idle 小於 10%,我們就可以獲知它所隸屬的服務,從服務名稱獲知其維護者是誰,進而向其維護者發出報警資訊,透過報警資訊我們就能大概知曉相關的資料,這樣便實現了後臺聯動。
存活監控

對於存活監控來說,主要檢視的是行程以及埠兩個方面是否存活。為了實現部署聯動,我們規定了行程與埠的部署路徑。
有了行程的路徑,我們就能獲知行程的型別和對外開通的埠,從而實現了自然監控。
效能監控
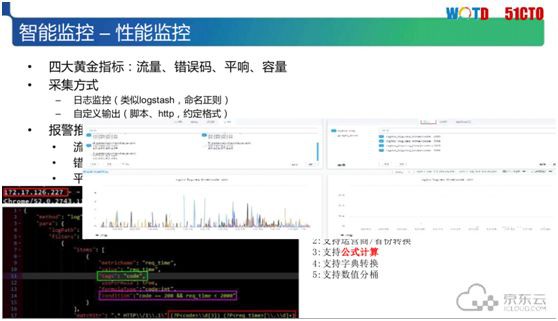
我們再來看效能監控方面,它主要關註的是服務對外的指標,該指標一般來自於日誌。
為了統一,我們事先規定、規範、並約定一種日誌格式,從多個維度讀取日誌資訊裡的不同 tag(標簽)值。
比如說:從宏觀層面上看京東的整體流量是平穩的,但是我們透過多維度的聚合,就能發現某個省的機房流量存在著細微的底層波動。
當然在採集方式上除了從日誌裡主動抓取之外,我們還能從程式和使用者處的報警來獲知。
業務監控

業務監控是從使用者處檢視服務是否正常。例如:電商常用到的是透過模擬全國各地的使用者訪問來發現分省份、分運營商或者分機房訪問的情況。
這就是運用外網或是自定義的方式來測試業務。另外,我們也會運用模擬雲操作的方式,去監控雲服務。
例如:模擬一個使用者登入到雲網站→購買一臺主機→部署一個映象→進行一次釋出。
我們來判斷全程是否一切正常。如此,我們就能夠從使用者的角度,先於使用者發現問題、處理問題、併排除故障。
總結與展望

如上圖所示,我們最終在前面的基礎上構建了京東雲的自動化運維平臺 ark。
在介面上,它能夠提供:
-
配置管理、JNS 管理和資源管理。
-
當天的部署過程。
-
應用相關的工具和元件。
-
各種報表。
-
監控的對外展示,包括如何做對比、報表和查詢。

總結起來,我們的監控自動化平臺,透過各種技術的運用基本實現了服務化,做到了全生命週期的 DevOps。
面對數量龐大的 SaaS 客戶,我們的解決方案為他們保證了交付效率、節約了成本、併為各種可能碰到的問題做好了準備。

鄭永寬,京東雲資深架構師,華中科技大學碩士。擁有 6 年自動化運維平臺研發運營經驗。2011 年-2016 年任百度自動化運維平臺經理,主要負責分散式任務排程系統,資料傳輸系統,百度部署釋出系統。2016 年至今,任京東雲運維平臺負責人,主要負責京東雲自動化運維體系構建。
●編號158,輸入編號直達本文
●輸入m獲取到文章目錄

Linux學習
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
