
作者 | Gustavo Duarte
譯者 | qhwdw ? ? ? ? ? 共計翻譯:102 篇 貢獻時間:160 天
上一篇文章中我們學習了核心怎麼為一個使用者行程 管理虛擬記憶體[1],而沒有提及檔案和 I/O。這一篇文章我們將專門去講這個重要的主題 —— 頁面快取。檔案和記憶體之間的關係常常很不好去理解,而它們對系統效能的影響卻是非常大的。
在面對檔案時,有兩個很重要的問題需要作業系統去解決。第一個是相對記憶體而言,慢的讓人發狂的硬碟驅動器,尤其是磁碟尋道[2]。第二個是需要將檔案內容一次性地載入到物理記憶體中,以便程式間共享檔案內容。如果你在 Windows 中使用 行程瀏覽器[3] 去檢視它的行程,你將會看到每個行程中載入了大約 ~15MB 的公共 DLL。我的 Windows 機器上現在大約執行著 100 個行程,因此,如果不共享的話,僅這些公共的 DLL 就要使用高達 ~1.5 GB 的物理記憶體。如果是那樣的話,那就太糟糕了。同樣的,幾乎所有的 Linux 行程都需要 ld.so 和 libc,加上其它的公共庫,它們佔用的記憶體數量也不是一個小數目。
幸運的是,這兩個問題都用一個辦法解決了:頁面快取 —— 儲存在記憶體中的頁面大小的檔案塊。為了用圖去說明頁面快取,我捏造出一個名為 render 的 Linux 程式,它開啟了檔案 scene.dat,並且一次讀取 512 位元組,並將檔案內容儲存到一個分配到堆中的塊上。第一次讀取的過程如下:

Reading and the page cache
render 請求 scene.dat 從位移 0 開始的 512 位元組。scene.dat 的 4kb 塊,以滿足該請求。假設該資料沒有快取。scend.dat 從位移 0 開始的 4kb 複製到分配的頁面幀。read() 結束。讀取完 12KB 的檔案內容以後,render 程式的堆和相關的頁面幀如下圖所示:
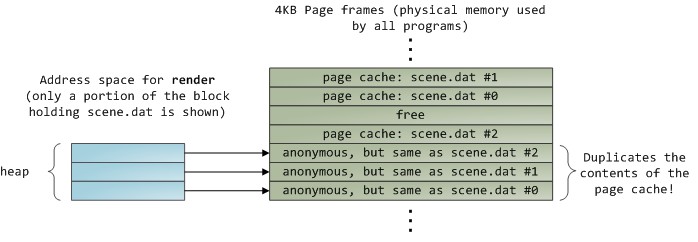
Non-mapped file read
它看起來很簡單,其實這一過程做了很多的事情。首先,雖然這個程式使用了普通的讀取(read)呼叫,但是,已經有三個 4KB 的頁面幀將檔案 scene.dat 的一部分內容儲存在了頁面快取中。雖然有時讓人覺得很驚奇,但是,普通的檔案 I/O 就是這樣透過頁面快取來進行的。在 x86 架構的 Linux 中,核心將檔案認為是一系列的 4KB 大小的塊。如果你從檔案中讀取單個位元組,包含這個位元組的整個 4KB 塊將被從磁碟中讀入到頁面快取中。這是可以理解的,因為磁碟通常是持續吞吐的,並且程式一般也不會從磁碟區域僅僅讀取幾個位元組。頁面快取知道檔案中的每個 4KB 塊的位置,在上圖中用 #0、#1 等等來描述。Windows 使用 256KB 大小的檢視,類似於 Linux 的頁面快取中的頁面。
不幸的是,在一個普通的檔案讀取中,核心必須複製頁面快取中的內容到使用者緩衝區中,它不僅花費 CPU 時間和影響 CPU 快取[4],在複製資料時也浪費物理記憶體。如前面的圖示,scene.dat 的記憶體被儲存了兩次,並且,程式中的每個實體都用另外的時間去儲存內容。我們雖然解決了從磁碟中讀取檔案緩慢的問題,但是在其它的方面帶來了更痛苦的問題。記憶體對映檔案是解決這種痛苦的一個方法:

Mapped file read
當你使用檔案對映時,核心直接在頁面快取上對映你的程式的虛擬頁面。這樣可以顯著提升效能:Windows 系統程式設計[5] 報告指出,在相關的普通檔案讀取上執行時效能提升多達 30% ,在 Unix 環境中的高階程式設計[6] 的報告中,檔案對映在 Linux 和 Solaris 也有類似的效果。這取決於你的應用程式型別的不同,透過使用檔案對映,可以節約大量的物理記憶體。
對高效能的追求是永恆不變的標的,測量是很重要的事情[7],記憶體對映應該是程式員始終要使用的工具。這個 API 提供了非常好用的實現方式,它允許你在記憶體中按位元組去訪問一個檔案,而不需要為了這種好處而犧牲程式碼可讀性。在一個類 Unix 的系統中,可以使用 mmap[8] 檢視你的 地址空間[9],在 Windows 中,可以使用 CreateFileMapping[10],或者在高階程式語言中還有更多的可用封裝。當你對映一個檔案內容時,它並不是一次性將全部內容都對映到記憶體中,而是透過 頁面故障[11] 來按需對映的。在 獲取[12] 需要的檔案內容的頁面幀後,頁面故障控制代碼 對映你的虛擬頁面[13] 到頁面快取上。如果一開始檔案內容沒有快取,這還將涉及到磁碟 I/O。
現在出現一個突發的狀況,假設我們的 render 程式的最後一個實體退出了。在頁面快取中儲存著 scene.dat 內容的頁面要立刻釋放掉嗎?人們通常會如此考慮,但是,那樣做並不是個好主意。你應該想到,我們經常在一個程式中建立一個檔案,退出程式,然後,在第二個程式去使用這個檔案。頁面快取正好可以處理這種情況。如果考慮更多的情況,核心為什麼要清除頁面快取的內容?請記住,磁碟讀取的速度要慢於記憶體 5 個數量級,因此,命中一個頁面快取是一件有非常大收益的事情。因此,只要有足夠大的物理記憶體,快取就應該保持全滿。並且,這一原則適用於所有的行程。如果你現在執行 render 一週後, scene.dat 的內容還在快取中,那麼應該恭喜你!這就是什麼核心快取越來越大,直至達到最大限制的原因。它並不是因為作業系統設計的太“垃圾”而浪費你的記憶體,其實這是一個非常好的行為,因為,釋放物理記憶體才是一種“浪費”。(LCTT 譯註:釋放物理記憶體會導致頁面快取被清除,下次執行程式需要的相關資料,需要再次從磁碟上進行讀取,會“浪費” CPU 和 I/O 資源)最好的做法是盡可能多的使用快取。
由於頁面快取架構的原因,當程式呼叫 write()[14] 時,位元組只是被簡單地複製到頁面快取中,並將這個頁面標記為“臟”頁面。磁碟 I/O 通常並不會立即發生,因此,你的程式並不會被阻塞在等待磁碟寫入上。副作用是,如果這時候發生了電腦宕機,你的寫入將不會完成,因此,對於至關重要的檔案,像資料庫事務日誌,要求必須進行 fsync()[15](仍然還需要去擔心磁碟控制器的快取失敗問題),另一方面,讀取將被你的程式阻塞,直到資料可用為止。核心採取預載入的方式來緩解這個矛盾,它一般提前預讀取幾個頁面並將它載入到頁面快取中,以備你後來的讀取。在你計劃進行一個順序或者隨機讀取時(請檢視 madvise()[16]、readahead()[17]、Windows 快取提示[18] ),你可以透過提示幫助核心去調整這個預載入行為。Linux 會對記憶體對映的檔案進行 預讀取[12],但是我不確定 Windows 的行為。當然,在 Linux 中它可能會使用 O_DIRECT[19] 跳過預讀取,或者,在 Windows 中使用 NO_BUFFERING[20] 去跳過預讀,一些資料庫軟體就經常這麼做。
一個檔案對映可以是私有的,也可以是共享的。當然,這隻是針對記憶體中內容的更新而言:在一個私有的記憶體對映上,更新並不會提交到磁碟或者被其它行程可見,然而,共享的記憶體對映,則正好相反,它的任何更新都會提交到磁碟上,並且對其它的行程可見。核心使用寫時複製(CoW)機制,這是透過頁面表條目(PTE)來實現這種私有的對映。在下麵的例子中,render 和另一個被稱為 render3d 的程式都私有對映到 scene.dat上。然後 render 去寫入對映的檔案的虛擬記憶體區域:

The Copy-On-Write mechanism
scene.dat,核心誤導它們並將它們對映到頁面快取,但是使該頁面表條目只讀。render 試圖寫入到對映 scene.dat 的虛擬頁面,處理器發生頁面故障。scene.dat 的第二塊內容到其中,並對映故障的頁面到新的頁面幀。上面展示的只讀頁面表條目並不意味著對映是隻讀的,它只是內核的一個用於共享物理記憶體的技巧,直到盡可能的最後一刻之前。你可以認為“私有”一詞用的有點不太恰當,你只需要記住,這個“私有”僅用於更新的情況。這種設計的重要性在於,要想看到被對映的檔案的變化,其它程式只能讀取它的虛擬頁面。一旦“寫時複製”發生,從其它地方是看不到這種變化的。但是,核心並不能保證這種行為,因為它是在 x86 中實現的,從 API 的角度來看,這是有意義的。相比之下,一個共享的對映只是將它簡單地對映到頁面快取上。更新會被所有的行程看到並被寫入到磁碟上。最終,如果上面的對映是隻讀的,頁面故障將觸發一個記憶體段失敗而不是寫到一個副本。
動態載入庫是透過檔案對映融入到你的程式的地址空間中的。這沒有什麼可奇怪的,它透過普通的 API 為你提供與私有檔案對映相同的效果。下麵的示例展示了對映檔案的 render 程式的兩個實體執行的地址空間的一部分,以及物理記憶體,嘗試將我們看到的許多概念綜合到一起。
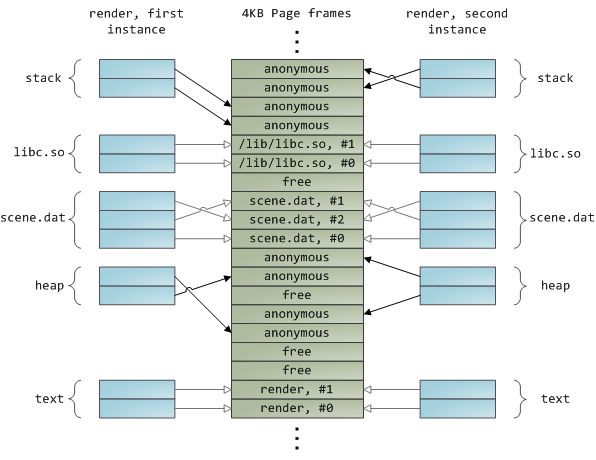
Mapping virtual memory to physical memory
這是記憶體架構系列的第三部分的結論。我希望這個系列文章對你有幫助,對理解作業系統的這些主題提供一個很好的思維模型。
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
作者:Gustavo Duarte[22] 譯者:qhwdw 校對:wxy
本文由 LCTT 原創編譯,Linux中國 榮譽推出
