
apiVersion: v1
kind: Service
metadata:
name: k8s-hadoop-master
spec:
type: NodePort
selector:
app: k8s-hadoop-master
ports:
- name: rpc
port: 9000
targetPort: 9000
- name: http
port: 50070
targetPort: 50070
nodePort: 32007
-
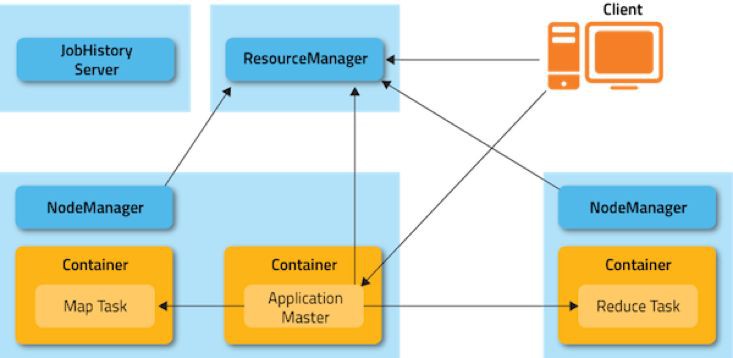
9000埠用於內部IPC通訊,主要用於獲取檔案的元資料
-
50070埠用於HTTP服務,為Hadoop 的Web管理使用
#!/usr/bin/env bash
sed -i "s/@HDFS_MASTER_SERVICE@/$HDFS_MASTER_SERVICE/g" $HADOOP_HOME/etc/hadoop/core-site.xml
sed -i "s/@HDOOP_YARN_MASTER@/$HDOOP_YARN_MASTER/g" $HADOOP_HOME/etc/hadoop/yarn-site.xml
yarn-master
HADOOP_NODE="${HADOOP_NODE_TYPE}"
if [ $HADOOP_NODE = "datanode" ]; then
echo "Start DataNode ..."
hdfs datanode -regular
else
if [ $HADOOP_NODE = "namenode" ]; then
echo "Start NameNode ..."
hdfs namenode
else
if [ $HADOOP_NODE = "resourceman" ]; then
echo "Start Yarn Resource Manager ..."
yarn resourcemanager
else
if [ $HADOOP_NODE = "yarnnode" ]; then
echo "Start Yarn Resource Node ..."
yarn nodemanager
else
echo "not recoginized nodetype "
fi
fi
fi
fi

dfs.namenode.datanode.registration.ip-hostname-check=false
apiVersion: v1
kind: Pod
metadata:
name: k8s-hadoop-master
labels:
app: k8s-hadoop-master
spec:
containers:
- name: k8s-hadoop-master
image: kubeguide/hadoop
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9000
- containerPort: 50070
env:
- name: HADOOP_NODE_TYPE
value: namenode
- name: HDFS_MASTER_SERVICE
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDFS_MASTER_SERVICE
- name: HDOOP_YARN_MASTER
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDOOP_YARN_MASTER
restartPolicy: AlwaysapiVersion: v1
kind: Pod
metadata:
name: hadoop-datanode-1
labels:
app: hadoop-datanode-1
spec:
containers:
- name: hadoop-datanode-1
image: kubeguide/hadoop
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9000
- containerPort: 50070
env:
- name: HADOOP_NODE_TYPE
value: datanode
- name: HDFS_MASTER_SERVICE
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDFS_MASTER_SERVICE
- name: HDOOP_YARN_MASTER
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDOOP_YARN_MASTER
restartPolicy: Always

apiVersion: v1
kind: Service
metadata:
name: yarn-node-1
spec:
clusterIP: None
selector:
app: yarn-node-1
ports:
- port: 8040
apiVersion: v1
kind: Pod
metadata:
name: yarn-node-1
labels:
app: yarn-node-1
spec:
containers:
- name: yarn-node-1
image: kubeguide/hadoop
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8040
- containerPort: 8041
- containerPort: 8042
env:
- name: HADOOP_NODE_TYPE
value: yarnnode
- name: HDFS_MASTER_SERVICE
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDFS_MASTER_SERVICE
- name: HDOOP_YARN_MASTER
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDOOP_YARN_MASTER
restartPolicy: Always
apiVersion: v1
kind: Service
metadata:
name: ku8-yarn-master
spec:
type: NodePort
selector:
app: yarn-master
ports:
- name: "8030"
port: 8030
- name: "8031"
port: 8031
- name: "8032"
port: 8032
- name: http
port: 8088
targetPort: 8088
nodePort: 32088
apiVersion: v1
kind: Pod
metadata:
name: yarn-master
labels:
app: yarn-master
spec:
containers:
- name: yarn-master
image: kubeguide/hadoop
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9000
- containerPort: 50070
env:
- name: HADOOP_NODE_TYPE
value: resourceman
- name: HDFS_MASTER_SERVICE
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDFS_MASTER_SERVICE
- name: HDOOP_YARN_MASTER
valueFrom:
configMapKeyRef:
name: ku8-hadoop-conf
key: HDOOP_YARN_MASTER
restartPolicy: Always
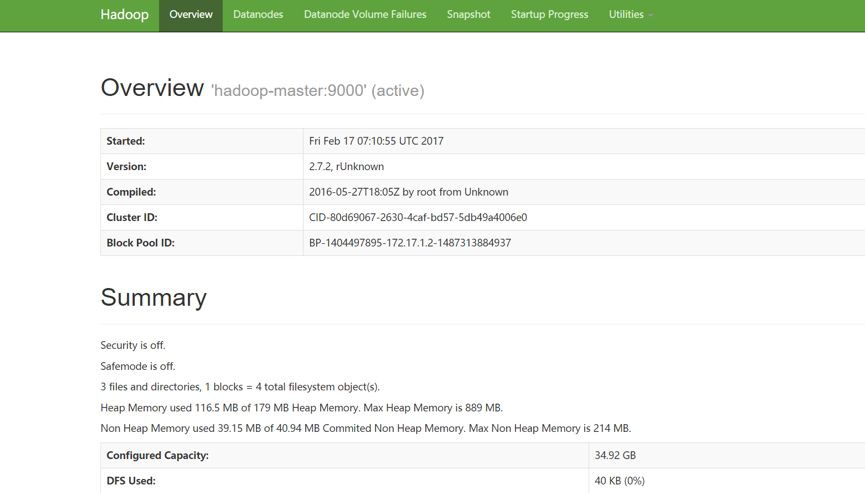

root@hadoop-master:/usr/local/hadoop/bin# hadoop fs -ls /
root@hadoop-master:/usr/local/hadoop/bin# hadoop fs -mkdir /leader-us
root@hadoop-master:/usr/local/hadoop/bin# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2017-02-17 07:32 /leader-us
root@hadoop-master:/usr/local/hadoop/bin# hadoop fs -put hdfs.cmd /leader-us



-
CPU:2*E5-2640v3-8Core
-
記憶體:16*16G DDR4
-
網絡卡:2*10GE多模光口
-
硬碟:12*3T SATA
-
BigCloud Enterprise Linux 7(GNU/Linux 3.10.0-514.el7.x86_64 x86_64)
-
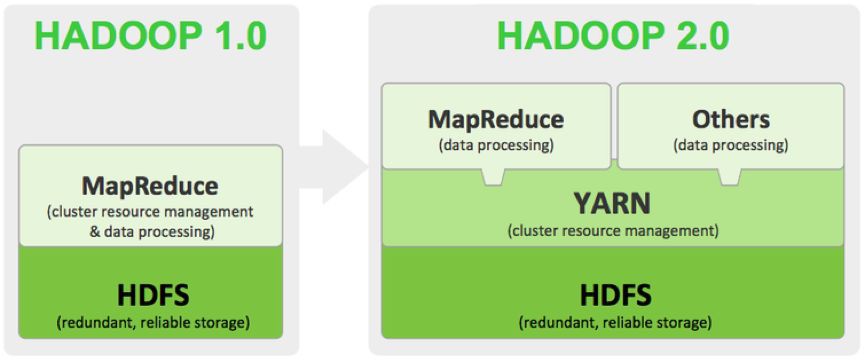
Hadoop2.7.2
-
Kubernetes 1.7.4+ Calico V3.0.1
-
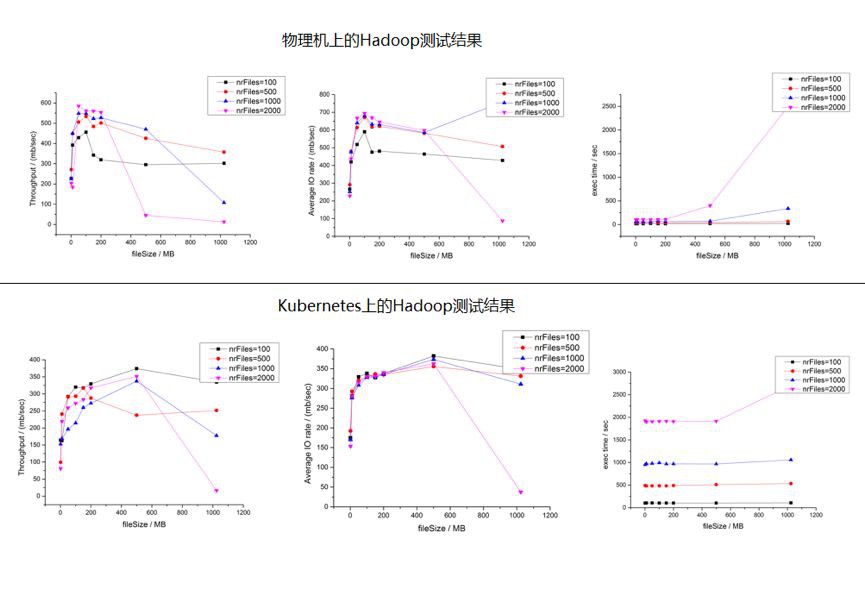
TestDFSIO:分散式系統讀寫測試
-
NNBench:NameNode測試
-
MRBench:MapReduce測試
-
WordCount:單詞頻率統計任務測試
-
TeraSort:TeraSort任務測試