
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @jsh0123。本文來自牛津大學 VGG 組,論文模型結構比較有特點,改變了以往的階段性引數獲取樣式,採用壓縮方式適應性獲取,對預訓練的模型引數有記憶性,保留先前的領域知識。
如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
關於作者:薑松浩,中國科學院計算技術研究所碩士生,研究方向為機器學習和資料挖掘。
■ 論文 | Efficient Parametrization of Multi-domain Deep Neural Networks
■ 連結 | https://www.paperweekly.site/papers/1800
■ 原始碼 | http://github.com/srebuffi/residual_adapters
論文亮點
這篇論文來自於牛津大學 VGG 組,該研究小組在機器視覺和遷移學習領域發表多篇重磅論文並且都被各類頂會錄用,作者之一的 Andrea Vedaldi 就是輕量級視覺開源框架 VLFeat 的主要作者。
平常工程中或者參加過 Kaggle 比賽的都知道遷移學習對模型效果提升、訓練效率提升的好處。這篇文章認為人類可以很快地處理大量不同的影象進行不同的任務分析,所以模型也能夠經過簡單的調整適應不同的場景。
本文提出了一種適合多領域、多工、可擴充套件的學習樣式,儘管當前階段多領域學習有很大突破,但效果相比於專有模型略有差距。
作者提出一種引數獲取樣式——Parametric Family(圖a),這種樣式改變了以往的階段性的引數提取(圖b),需適應的引數更少,並且在引數較少的基礎上使用了引數壓縮方法依然可以保證模型的效果。
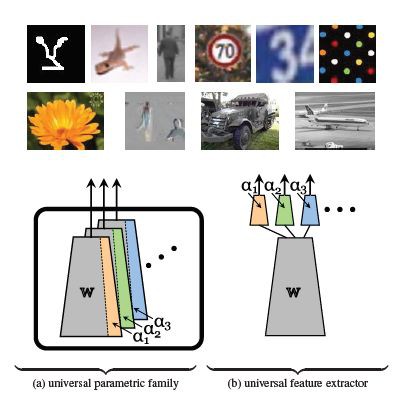
模型介紹
論文中提出了兩種殘差配接器,順序殘差適應器(Series Residual Adapters)和平行殘差適應器(Parallel Residual Adapters)。兩種模型的結構如下所示。

本文作者在 2017 年的 NIPS 上發表了一篇關於殘差適應器(Residual Adapters)的論文 Learning multiple visual domains with residual adapters [1],這篇論文中將殘差適應器定義為:

公式中 α 為適應引數,這樣做法的好處是當 α 為 0 時,f 就恢復到曾經的狀態,這樣就保證了記憶性。當引數 α 進行強正則項時, α 會接近於 0(L1 正則和 L2 正則都會令引數接近於 0)。
這裡作者們利用一種操作將 C×D 維的矩陣 A 進行重塑(Reshape)。

1. 順序殘差適應器(Series Residual Adapters)在前殘差適應器(Residual Adapters)進行了改進。

公式中 f 是標準的 filter,新的 filter g 可以看作是用 f 做為標準的低質的矩陣組合。

這樣適應器相當於對摺積層 filter 加入了“保險”機制。並且適應引數 α 維度較小是 filter f 的 1/L^2 大小。
2. 平行殘差適應器(Parallel Residual Adapters)和它的名字一樣適應引數 α 採用一種平行的方式。
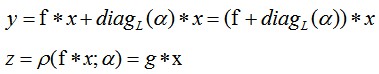
新的 filter g 可以按照如下公式定義:
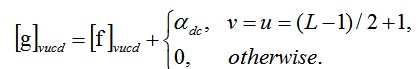
論文選擇 RestNet [2] 作為兩種殘差適應器(Residual Adapters)的應用網路結構。論文中利用 SVD 矩陣分解將適應引數進行降維處理使得儲存的引數變得更加低維。
模型實驗效果
模型透過不同資料集,取 RestNet 的不同階段應用殘差適應器(Residual Adapters),並同常見的 Finetuning 以及兩種不同的多領域學習模型 [1,3] 進行比較,得出實驗結果如下所示。

平行殘差適應器(Parallel Residual Adapters)進行引數壓縮後的平均結果最佳,相較於 Finetuning 以及兩種不同的多領域學習模型 [1,3] 都有很好的提升。
論文還驗證了不同規模的資料集的效果和 fine-tuning 進行比較,得出小規模資料和中等規模資料上兩種殘差適應器的效果都比較好,特別是小規模資料集中表現總是優於 fine-tuning,但是在大量資料集中 fine-tuning 效果就要領先了。
論文評價
這篇論文的模型結構比較有特點,改變了以往的階段性引數獲取樣式,採用壓縮方式適應性獲取,對預訓練的模型引數有記憶性,保留先前的領域知識。
本文在效果上也相對不錯,開拓了新的遷移學習模型結構,是多領域學習的一大突破,同時也是遷移學習領域的一個較為突出的進展。
參考文獻
[1] S. Rebuffi, H. Bilen, and A. Vedaldi. Learning multiple visual domains with residual adapters. In Proc. NIPS, 2017.
[2] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In Proc. ECCV, pages 630–645. Springer, 2016.
[3] A. Rosenfeld and J. K. Tsotsos. Incremental learning through deep adaptation. arXiv preprint arXiv:1705.04228, 2017.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:

 #投 稿 通 道#
#投 稿 通 道#
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot02)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文