
什麼是爬蟲
一段自動抓取網際網路資訊的程式,可以從一個URL出發,訪問它所關聯的URL,提取我們所需要的資料。也就是說爬蟲是自動訪問網際網路並提取資料的程式。

爬蟲的價值
將網際網路上的資料為我所用,開發出屬於自己的網站或APP
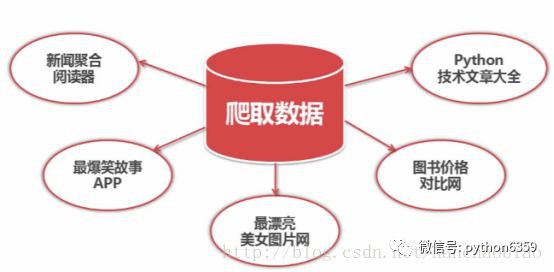
爬蟲框架
爬蟲排程端:用來啟動、執行、停止爬蟲,或者監視爬蟲中的執行情況
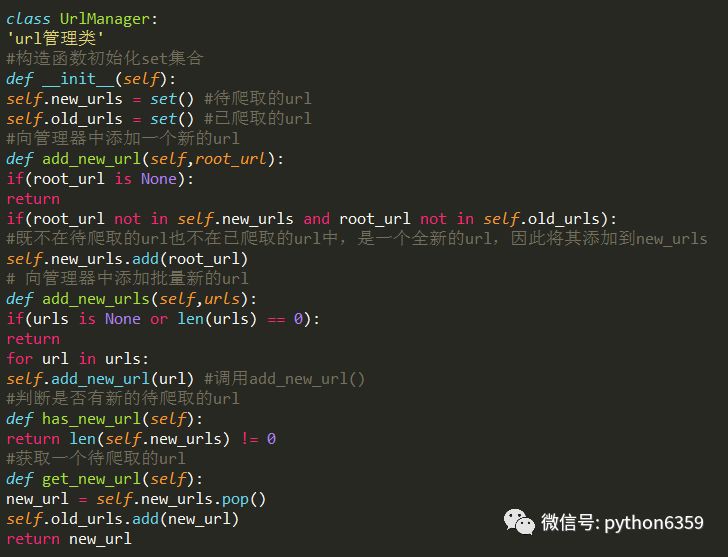
在爬蟲程式中有三個模組URL管理器:對將要爬取的URL和已經爬取過的URL這兩個資料的管理
網頁下載器:將URL管理器裡提供的一個URL對應的網頁下載下來,儲存為一個字串,這個字串會傳送給網頁解析器進行解析
網頁解析器:一方面會解析出有價值的資料,另一方面,由於每一個頁面都有很多指向其它頁面的網頁,這些URL被解析出來之後,可以補充進URL管理器
這三部門就組成了一個簡單的爬蟲架構,這個架構就能將網際網路中所有的網頁抓取下來

動態執行流程

URL管理器
防止重覆抓取和迴圈抓取,最嚴重情況兩個URL相互指向就會形成死迴圈

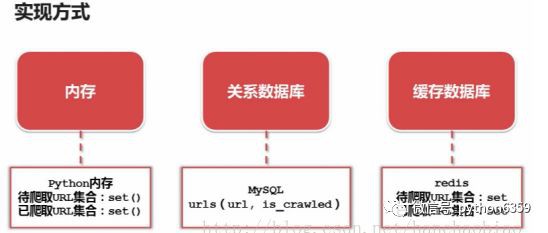
三種實現方式
Python記憶體set集合:set集合支援去重的作用
Mysql:url(訪問路徑)is_crawled(是否訪問)
Redis:使用Redis效能最好,且Redis中也有set型別,可以去重。不懂得同學可以看下Redis的介紹
urllib模組
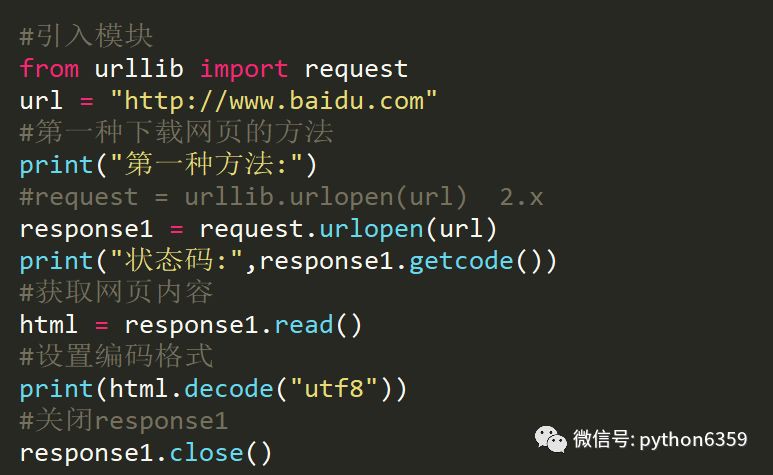
本文使用urllib實現
urllib2是python自帶的模組,不需要下載。
urllib2在python3.x中被改為urllib.request
1
方式一
2
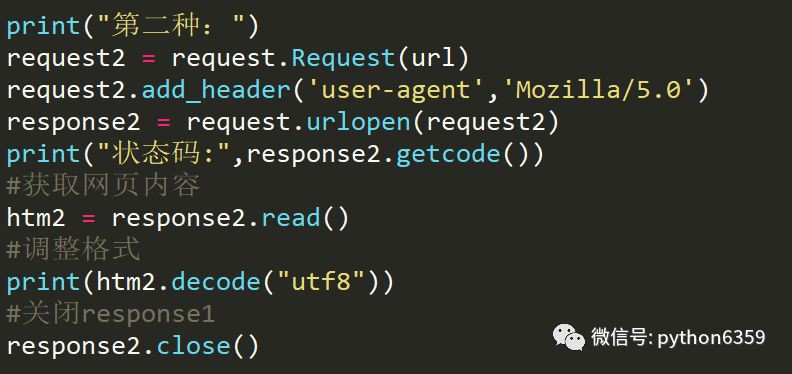
方式二
3
使用cookie

網頁解析器和BeautifulSoup第三方模組


測試是否安裝bs4


方法介紹



實體測試
html採用官方案例

獲取所有的連結

爬蟲開發實體(標的爬蟲百度百科)

入口:http://baike.baidu.com/item/Python
分析URL格式:防止訪問無用路徑 http://baike.baidu.com/item/{標題}
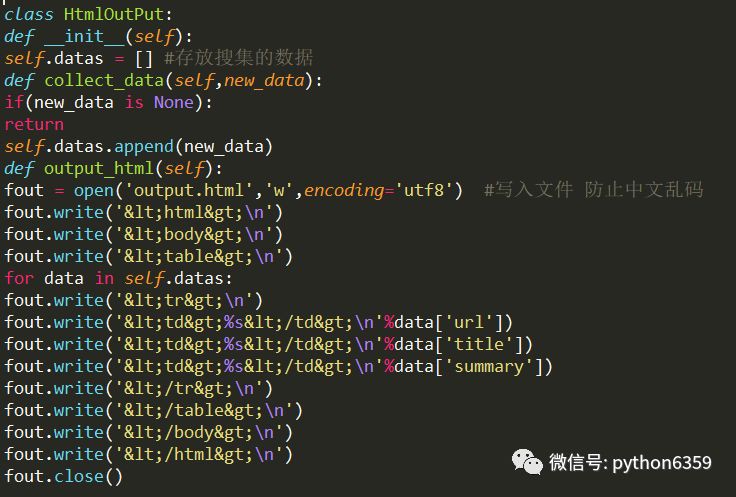
資料:抓取百度百科相關Python詞條網頁的標題和簡介
透過審查元素得標題元素為 :class=”lemmaWgt-lemmaTitle-title”
簡介元素為:class=”lemma-summary”
頁面編碼:UTF-8
作為定向爬蟲網站要根據爬蟲的內容升級而升級如執行出錯可能為百度百科升級,此時則需要重新分析標的
建立spider_main.py

建立url_manager.py
建立html_downloader.py

建立html_parser.py

建立html_output.py
作者:loading
源自:www.androidchina.net/8417.html
宣告:文章著作權歸作者所有,如有侵權,請聯絡小編刪除

