作者丨楊敏
單位丨中國科學院深圳先進技術研究院助理研究員
研究方向丨自然語言處理
文字建模方法大致可以分為兩類:(1)忽略詞序、對文字進行淺層語意建模(代表模型包括 LDA,EarthMover’s distance等); (2)考慮詞序、對文字進行深層語意建模(深度學習演演算法,代表模型包括 LSTM,CNN 等)。
在深度學習模型中,空間樣式(spatial patterns)彙總在較低層,有助於表示更高層的概念(concepts)。例如,CNN 建立摺積特徵檢測器提取來自區域性序列視窗的樣式,並使用 max-pooling 來選擇最明顯的特徵。然後,CNN 分層地提取不同層次的特徵樣式。
然而,CNN 在對空間資訊進行建模時,需要對特徵檢測器進行複製,降低了模型的效率。正如(Sabouret al, 2017)所論證的那樣,這類方法所需複製的特徵檢測器的個數或所需的有標簽訓練資料的數量隨資料維度呈指數增長。
另一方面,空間不敏感的方法不可避免地受限於豐富的文字結構(比如儲存單詞的位置資訊、語意資訊、語法結構等),難以有效地進行編碼且缺乏文字表達能力。
最近,Hinton 老師等提出了膠囊網路(Capsule Network), 用神經元向量代替傳統神經網路的單個神經元節點,以 Dynamic Routing 的方式去訓練這種全新的神經網路,有效地改善了上述兩類方法的缺點。
正如在人類的視覺系統的推理過程中,可以智慧地對區域性和整體(part-whole)的關係進行建模,自動地將學到的知識推廣到不同的新場景中。
到目前為止,並沒用工作將 Capsule Network 應用於自然語言處理中(e.g., 文字分類)。
我們針對 Capsule Network 在文字分類任務上的應用做了深入研究。對於傳統的分類問題,Capsule Network 取得了較好效能,我們在 6 個 benchmarks 上進行了實驗,Capsule Network 在其中 4 個中取得了最好結果。
更重要的是,在多標簽遷移的任務上(fromsingle-label to multi-label text classification),Capsule Network 的效能遠遠地超過了 CNN 和 LSTM。
我們的工作已經發表在 arXiv上,論文名為 Investigating Capsule Networks with Dynamic Routing for Text Classificationm,更多細節可以點選閱讀原文進行參考。我們會在論文發表後公開原始碼。
論文模型
文字主要研究膠囊網路在文字分類任務上的應用,模型的結構圖如下:

其中,連續兩個摺積層採用動態路由替換池化操作。動態路由的具體細節如下:

在路由過程中,許多膠囊屬於背景膠囊,它們和最終的類別膠囊沒有關係,比如文本里的停用詞、類別無關詞等等。因此,我們提出三種策略有減少背景或者噪音膠囊對網路的影響。
1. Orphan 類別:在膠囊網路的最後一層,我們引入 Orphan 類別,它可以捕捉一些背景知識,比如停用詞。在視覺任務加入 Orphan 類別效果比較有限,因為圖片的背景在訓練和測試集裡往往是多變的。然而,在文字任務,停用詞比較一致,比如謂詞和代詞等。
2. Leaky-Softmax:除了在最後一層引入 Orphan 類別,中間的連續摺積層也需要引入去噪機制。對比 Orphan 類別,Leaky-Softmax 是一種輕量的去噪方法,它不需要額外的引數和計算量。
3. 路由引數修正:傳統的路由引數,通常用均與分佈進行初始化,忽略了下層膠囊的機率。相反,我們把下層膠囊的機率當成路由引數的先驗,改進路由過程。 在 ablation test 中,我們對改進的路由和原始路由方法進行對比,如下:
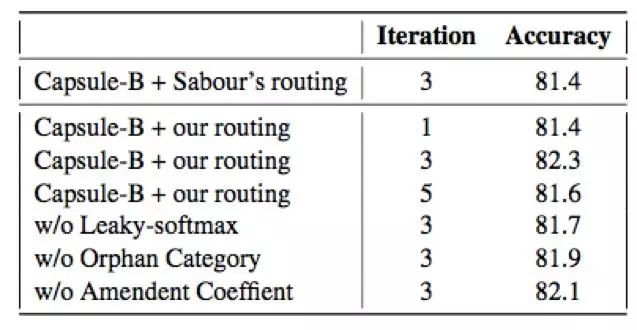
此外,為了提升文字效能,我們引入了兩種網路結構,具體如下:

實驗
資料集:為了驗證模型的有效性,我們在 6 個文字資料集上做測試,細節如下:
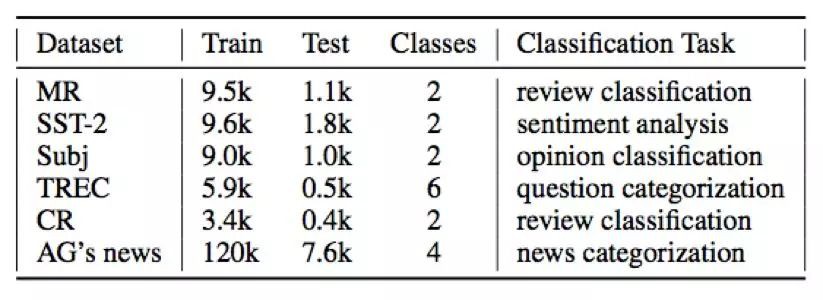
在實驗中,我們和一些效果較好的文字分類演演算法進行了對比。由於本文的重點是研究 Capsule Network 相對已有分類演演算法(e.g.,LSTM, CNN)是否有提升,我們並沒有與網路結構太過複雜的模型進行對比。實驗結果如下:

此外,我們重點進行了多標簽遷移實驗。我們將 Rueter-21578 資料集中的單標簽樣本作為訓練資料,分別在只包含多標簽樣本的測試資料集和標準測試資料集上進行測試。詳細的資料統計以及實驗結果如下圖所示。
從表中我們可以看出,當我們用單標簽資料對模型進行訓練,併在多標簽資料上進行測試時,Capsule Network 的效能遠遠高於 LSTM、CNN 等。


此外,我們還做了 case study 分析,發現路由引數可以表示膠囊的重要性,並對膠囊進行視覺化(此處我們主要視覺化 3-gram 的結果)。
具體來說,我們刪除摺積膠囊層,將 Primary Capsule Layer 直接連結到 Fully-connected Capsule Layer,其中 Primary Capsule 代表了 N-gram 短語在 Capsule 裡的形式,Capsule 之間的連結強度代表了每個 Primary Capsule 在本文類別中的重要性(比較類似並行註意力機制)。
由圖我們可以看出,對於 Interest Rate 類別,months-interbank-rate 等 3-grams 起著重要作用。

致謝
感謝 jhui 和蘇劍林,他們的文章啟發了我們的工作。感謝 naturomics 和 gyang274 的開原始碼,讓我們的開發過程變得高效。
[1] https://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/
[2] https://spaces.ac.cn/archives/4819
[3] https://github.com/bojone/Capsule
[4] https://github.com/naturomics/CapsNet-Tensorflow
主要參考文獻
[1] Dynamic Routing Between Capsules
[2] Matrix Capsules with Em Routing

點選以下標題檢視相關文章:

 #投 稿 通 道#
#投 稿 通 道#
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot02)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視論文
