來自:程式員小灰(微訊號:chengxuyuanxiaohui)
https://mp.weixin.qq.com/s/g9cXT0dlcmbkQRj6lX6zbw


————— 第二天 —————






————————————




什麼是MapReduce?
MapReduce是一種程式設計模型,其理論來自Google公司發表的三篇論文(MapReduce,BigTable,GFS)之一,主要應用於海量資料的平行計算。
MapReduce可以分成Map和Reduce兩部分理解。
1.Map:對映過程,把一組資料按照某種Map函式對映成新的資料。
2.Reduce:歸約過程,把若干組對映結果進行彙總並輸出。
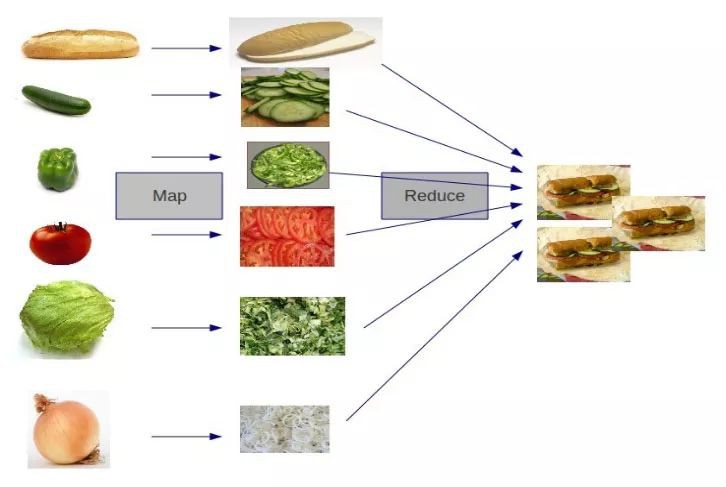
讓我們來看一個實際應用的慄子,如何高效地統計出全國所有姓氏的人數?
我們可以利用MapReduce的思想,針對每個省的人口做並行對映,統計出若干個區域性結果,再把這些區域性結果進行整理和彙總:

這張圖是什麼意思呢?我們來分別解釋一下步驟:
1.Map:
以各個省為單位,多個執行緒並行讀取不同省的人口資料,每一條記錄生成一個Key-Value鍵值對。圖中僅僅是簡化了的資料。
2.Shuffle
Shuffle這個概念在前文並未提及,它的中文意思是“洗牌”。Shuffle的過程是對資料對映的排序、分組、複製。
3.Reduce
執行之前分組的結果,併進行彙總和輸出。
需要註意的是,這裡描述的Shuffle只是抽象的概念,在實際執行過程中Shuffle被分成了兩部分,一部分在Map任務中完成,一部分在Reduce任務中完成。


Hadoop如何實現MapReduce?

Hadoop是Apache基金會開發的一套分散式系統框架,包含多個元件,其核心就是HDFS和MapReduce。
由於篇幅原因,文字不會對Hadoop做完整的介紹,只是簡單介紹一下Haddoop框架當中如何實現MapReduce。
下麵這張圖是Hadoop框架執行一個MapReduce Job的全過程:

這裡需要對幾種物體進行解釋:
HDFS:
Hadoop的分散式檔案系統,為MapReduce提供資料源和Job資訊儲存。
Client Node:
執行MapReduce程式的行程,用來提交MapReduce Job。
JobTracker Node:
把完整的Job拆分成若干Task,負責排程協調所有Task,相當於Master的角色。
TaskTracker Node:
負責執行由JobTracker指派的Task,相當於Worker的角色。這其中的Task分為MapTask和ReduceTask。


●編號308,輸入編號直達本文
●輸入m獲取文章目錄

大資料與人工智慧
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
