
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @kaitoron。本文首次提出用端到端的方案來解決從少量相同風格的字型中合成其他藝術字型,例如 A-Z 26 個相同風格的藝術字母,已知其中 A-D 的藝術字母,生成剩餘 E-Z 的藝術字母。
本文研究的問題看上去沒啥亮點,但在實際應用中,很多設計師在設計海報或者電影標題的字型時,只會創作用到的字母,但想將風格遷移到其他設計上時,其他的一些沒設計字母需要自己轉化,造成了不必要的麻煩。
如何從少量(5 個左右)的任意型別的藝術字中泛化至全部 26 個字母是本文的難點。本文透過對傳統 Condition GAN 做擴充套件,提出了 Stack GAN 的兩段式架構,首先透過 Conditional GAN #1 根據已知的字型生成出所有 A-Z 的字型,之後透過 Conditional GAN #2 加上顏色和藝術點綴。
如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
關於作者:黃亢,卡耐基梅隆大學碩士,研究方向為資訊抽取和手寫識別,現為波音公司資料科學家。
■ 論文 | Multi-Content GAN for Few-Shot Font Style Transfer
■ 連結 | https://www.paperweekly.site/papers/1781
■ 原始碼 | https://github.com/azadis/MC-GAN
論文動機
在很多 2D 宣傳海報設計中,藝術家們花了很多時間去研究風格相容的藝術字,也因此只去設計當前作品中所需要的少部分字母,之後若是作品成功想要將藝術字的風格轉移到其他專案中時,難免會出現新的字母,這時候得花更多的時間去補充和完善。
本文希望在只看到少量已有藝術字母的劣勢下,透過 GAN 來自動生成那些我們需要但又缺失的相同風格的字母。
模型介紹
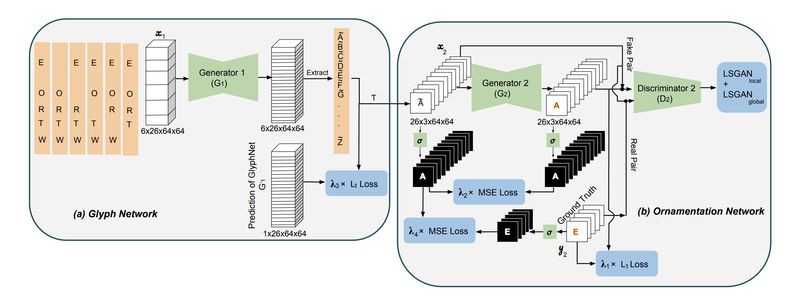
本文的模型建立在許多已有的工作基礎之上。先從宏觀角度來看,整個網路分為兩個個階段:第一階段先根據不同字母之間的相互聯絡產生出基本的灰度字形,第二階段給字母上色以及合成相應的裝飾效果。
GAN 本來就難訓練,作為 Stack GAN 我們有必要把第一階段網路給預訓練一下。那就讓我們把 Stack GAN 拆成 Glyph(字形)網路和 Ornamentation(修飾)網路單獨來看。
Glyph 網路其實是 Conditional GAN [1] 的衍生,只不過中間網路更複雜,損失函式更加豐富。
我們知道傳統 GAN 的輸入是 Random Noise,這裡它採用了和 Conditional GAN 一樣的做法,只把要模仿的字母作為輸入而忽略了 Random Noise。輸入維度是B X 26 X 64 X 64,B 是 Batch Size,26 指的是 A-Z,64X64 指的是每個字母圖片的長寬大小。

▲ 圖1:Glyph Network輸入示例
Glyph 網路中 Generator 延續了 Image Transformation Network [2] 中相同的架構,即多層 ResNet Block 抽取隱含特徵再透過 transpose convolution 上取樣輸出和原來大小一致的圖片,即輸出也是 B X 26 X 64 X 64。
這裡值得註意的是,作者沒有直接將圖 1 作為輸入,否則二維摺積由於橫向的感受野太小很難捕捉到相鄰較遠字元之間(例如 A 和 Z)的特徵。因此作者巧妙的增加了一個維度——輸入字母的數目,即將平鋪開來的輸入圖片給垂直壘起來。
作者在程式碼中第一層還用了三維摺積去模擬了用獨立不相關的 filter 去二維摺積每個字母圖片的效果,經過 Image Transformation Network 的輸出也為 B X 26 X 64 X 64,也就是 64 X 64 的 fake A-Z 26 個字母。
Discriminator 取用了 PatchGAN [1] 的思想,即在公共網路加了 3 層摺積層採用了 21 × 21 Local Discriminator 去衡量區域性真假,然後又在公共網路上平行加了 2 層作為 Global Discriminator 去衡量整個圖片的真假。
最後,Glyph 網路有 3 個 loss:Local & Global Discrimnator 的 least squares GAN ( LSGAN ) loss [3],以及 Generator 的 L1 loss。loss 之間的權重作為網路的 hyperparameter。
整個網路的示意圖如下圖:

▲ 圖2
Ornamentation 網路架構本質上和 Glyph 網路是一樣的,但不同的在於 GlyphNet 從大量的訓練字型中學得字形聯絡,而 OrnaNet 是從少量已觀察到的藝術字元中,學習如何把已觀察到的字母顏色或修飾遷移到其他未觀察到字母上。
▲ 圖3
最後要 end2end training 兩個網路,此時 GlyphNet 已經有了 pretrained model。最後的訓練只是 finetune,所以理所當然地拆掉了 Discriminator 只保留了 Generator。
真正需要訓練的是 random initialized 的 OrnaNet,整個網路的輸入換成了圖 3 所示左圖,採用 leave one out 透過 GlyphNet 生成 OrnaNet 的輸入。
例如圖 4 原本觀察到字元是 water 的藝術字,GlyphNet 的輸入是便是 water 這 5 個字母依次輪流抽出一個後的其中 4 個作為輸入(wate),抽出的那一個作為要 predict 的字母(r),最後是 5 個字母全部在場的情況下預測其餘 22 個字母。

▲ 圖4
換句話說就是 GlyphNet 的輸出仍然是 6 X 26 X 64 X 64,但我們拿對應想要的維度拼接成 1 X 26 X 64 X 64,即 26 個灰度字形作為 OrnaNet 的輸入。也就是說,OraNet 最後的輸出就是最後完整的 26 個藝術字了。
為了穩定訓練,OrnaNet 除了具備和 Glyph 一樣的 3 個 loss,又額外增加了兩個二值化掩碼損失(sigmoid),分別是 Generator 的輸入和輸出的 mean square error,以及 Generator 的輸入和 ground truth 的 mean square error,共計 6 個loss function。各個 loss 之間的權重仍是網路的超參。
實驗結果
本文以 Image to Image Translation Network [5] 為 baseline,做了幾個小實驗:
1. Ablation Study(控制變數實驗),透過是否預訓練模型,去除某些模組的 loss 來體驗網路各個部分對整體字型效果做出的貢獻。
2. A-Z 不同字型之間的關係,Structural Similarity 是一種測量字型相似程度的標準,我們可以透過大量的 test 畫出已知 A 字型,預測出的 B 字型和真實 B 字型之間的 Structural Similarity 的分佈,由此我們可以定性地分析出各個字元對於任意字元預測的資訊貢獻量。
3. 研究關於輸入字元的數量對於 GlyphNet 預測質量的影響,發現當輸入字元為 6 時,Structural Similarity 的分佈已經趨於穩定。
4. 主觀評價:由於 task 特殊無法定量的用 metric 去衡量,找了 11 個人在 MC-GAN 和 Patch Synthesis Model [4] 產生的結果之間做選擇,80% 勝出。
總結心得
文字融合已有的大量 GAN 的成果,本文將字型風格遷移的工作分為兩個階段逐個擊破,首先生成字型,其次新增顏色和修飾。此外,利用字母之間相互的聯絡,只用少量字母就能將風格遷移到所有字母,也是本文的一大特色。
小小的不足是實驗只包括了 26 個字型,實際中我們可能還需要包括數字或小寫字母。雖然生成的質量和 baseline 相比有很大提高,但和 Ground Truth 比起來仍有差距。
最後,雖然文章著眼於 2D deisgn 中藝術字的風格遷移,不過把第一個網路單獨拿出來用於生成 handwriting 的 data 也是值得研究的。
參考文獻
[1] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. arXiv preprint arXiv:1611.07004, 2016.
[2] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision, pages 694–711. Springer.
[3] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. P. Smolley. Least squares generative adversarial networks.
[4] Yang, J. Liu, Z. Lian, and Z. Guo. Awesome typography: Statistics-based text effects transfer. arXiv preprint arXiv:1611.09026, 2016.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選以下標題檢視相關內容:

 #作 者 招 募#
#作 者 招 募#
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot02)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文