來自:運營喵是怎樣煉成的(微訊號:yymzylc)
作者:蘇格蘭折耳喵
之前在八月份寫過一篇針對外部資料分析的文章,《作為一個合格的“增長駭客”,你還得重視外部資料的分析!》,一部分讀者向筆者反映,說對外部資料的分析跳出了原有的只針對企業內部資料分析(使用者資料、銷售資料、流量資料等)的窠臼,往往能給產品、運營、營銷帶來意想不到的啟迪,為資料化驅動業務增長開啟了一扇窗…
鑒於此種情況,筆者將繼續對另一個案例進行從資料採集、資料清洗、資料分析再到資料視覺化的全流程分析,力求條理清晰的展現外部資料分析的強大威力。以下是本文的寫作框架:
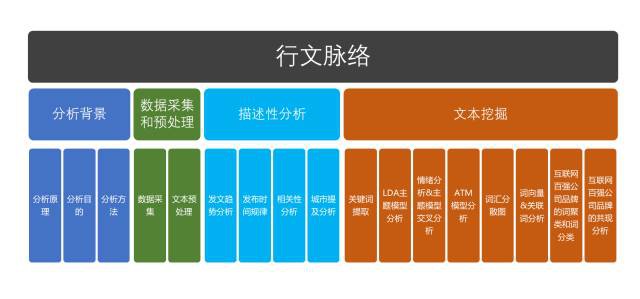
1 分析背景
1.1 分析原理—為什麼選擇分析虎嗅網
在現今資料爆炸、資訊質量良莠不齊的網際網路時代,我們無時無刻不身處在網際網路社會化媒體的“資訊洪流”之中,因而無可避免的被它上面泛濫的資訊所“裹挾”,也就是說,社會化媒體上的資訊對現實世界中的每個人都有重大影響,社會化媒體是我們間接瞭解現實客觀世界和主觀世界的一面窗戶,我們每時每刻都在受到它的影響。關於“社會化媒體”方面的內容,請參看《乾貨|如何利用Social Listening從社會化媒體中“提煉”有價值的資訊?》,以下內容也摘自該文:
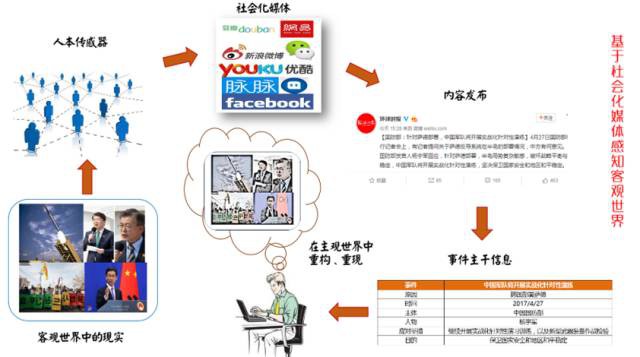

綜合上述兩類情形,可以得出這樣的結論,透過社會化媒體,我們可以觀察現實世界:

由此,社會化媒體是現實主客觀世界的一面鏡子,而它也會進一步影響人們的行為,如果我們對該領域中的優質媒體所釋出的資訊進行分析,除了可以瞭解該領域的發展行程和現狀,還可以對該領域的人群行為進行一定程度的預判。
鑒於此種情況,作為網際網路從業者的筆者想分析一下網際網路行業的一些現狀,第一步是找到在網際網路界有著重要影響力媒體,上次分析的是“人人的是產品經理”(請參看《 乾貨|作為一個合格的“增長駭客”,你還得重視外部資料的分析!》),這次筆者想到的是虎嗅網。
虎嗅網創辦於2012年5月,是一個聚合優質創新資訊與人群的新媒體平臺。該平臺專註於貢獻原創、深度、犀利優質的商業資訊,圍繞創新創業的觀點進行剖析與交流。虎嗅網的核心,是關註網際網路及傳統產業的融合、一系列明星公司(包括公眾公司與創業型企業)的起落軌跡、產業潮汐的動力與趨勢。
因此,對該平臺上的釋出內容進行分析,對於研究網際網路的發展行程和現狀有一定的實際價值。
1.2 本文的分析目的
筆者在本專案中的分析目的主要有4個:
(1)對虎嗅網內容運營方面的若干分析,主要是對發文量、收藏量、評論量等方面的描述性分析;
(2)透過文字分析,對網際網路行業的一些人、企業和細分領域進行趣味性的分析;
(3)展現文字挖掘在資料分析領域的實用價值;
(4)將雜蕪無序的結構化資料和非結構化資料進行視覺化,展現資料之美。
1.3 分析方法—分析工具和分析型別
本文中,筆者使用的資料分析工具如下:
-
Python3.5.2(程式語言)
-
Gensim(詞向量、主題模型)
-
Scikit-Learn(聚類和分類)
-
Keras(深度學習框架)
-
Tensorflow(深度學習框架)
-
Jieba(分詞和關鍵詞提取)
-
Excel(視覺化)
-
Seaborn(視覺化)
-
新浪微輿情(情緒語意分析)
-
Bokeh(視覺化)
-
Gephi(網路視覺化)
-
Plotly(視覺化)
使用上述資料分析工具,筆者將進行2類資料分析:第一類是較為傳統的、針對數值型資料的描述下統計分析,如閱讀量、收藏量等在時間維度上的分佈;另一類是本文的重頭戲—深層次的文字挖掘,包括關鍵詞提取、文章內容LDA主題模型分析、詞向量/關聯詞分析、DTM模型、ATM模型、詞彙分散圖和詞聚類分析。
2 資料採集和文字預處理
2.1 資料採集
筆者使用爬蟲採集了來自虎嗅網主頁的文章(並不是全部的文章,但展示在主頁的資訊是主編精挑細選的,很具代表性),資料採集的時間區間為2012.05~2017.11,共計41,121篇。採集的欄位為文章標題、釋出時間、收藏量、評論量、正文內容、作者名稱、作者自我簡介、作者發文量,然後筆者人工提取4個特徵,主要是時間特徵(時點和周幾)和內容長度特徵(標題字數和文章字數),最終得到的資料如下圖所示:

2.2 資料預處理
資料分析/挖掘領域有一條金科玉律:“Garbage in, Garbage out”,做好資料預處理,對於取得理想的分析結果來說是至關重要的。本文的資料規整主要是對文字資料進行清洗,處理的條目如下:
(1) 文字分詞
要進行文字挖掘,分詞是最為關鍵的一步,它直接影響後續的分析結果。筆者使用jieba來對文字進行分詞處理,它有3類分詞樣式,即全樣式、精確樣式、搜尋引擎樣式:
· 精確樣式:試圖將句子最精確地切開,適合文字分析;
· 全樣式:把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;
· 搜尋引擎樣式:在精確樣式的基礎上,對長詞再次切分,提高召回率,適合用於搜尋引擎分詞。
現以“新浪微輿情專註於社會化大資料的場景化應用”為例,3種分詞樣式的結果如下:
【全樣式】: 新浪/ 微輿情/ 新浪微輿情/ 專註/於/ 社會化/ 大資料/ 社會化大資料/ 的/ 場景化/ 應用
【精確樣式】: 新浪微輿情/ 專註/於/ 社會化大資料/ 的/ 場景化/ 應用
【搜尋引擎樣式】:新浪,微輿情,新浪微輿情,專註,於,社會化,大資料,社會化大資料,的,場景化,應用
為了避免歧義和切出符合預期效果的詞彙,筆者採取的是精確(分詞)樣式。
(2) 去停用詞
這裡的去停用詞包括以下三類:
-
標點符號:, 。! /、*+-
-
特殊符號:❤❥웃유♋☮✌☏☢☠✔☑♚▲♪等
-
無意義的虛詞:“the”、“a”、“an”、“that”、“你”、“我”、“他們”、“想要”、“開啟”、“可以”等
(3) 去掉高頻詞、稀有詞和計算Bigrams
去掉高頻詞、稀有詞是針對後續的主題模型(LDA、ATM)時使用的,主要是為了排除對區隔主題意義不大的詞彙,最終得到類似於停用詞的效果。
Bigrams是為了自動探測出文本中的新詞,基於詞彙之間的共現關係—如果兩個詞經常一起毗鄰出現,那麼這兩個詞可以結合成一個新詞,比如“資料”、“產品經理”經常一起出現在不同的段落裡,那麼,“資料_產品經理”則是二者合成出來的新詞,只不過二者之間包含著下劃線。
3 描述性分析
該部分中,筆者主要對數值型資料進行描述性的統計分析,它屬於較為常規的資料分析,能揭示出一些問題,做到知其然,關於資料分析的4種型別,詳情請參看《乾貨|作為一個合格的“增長駭客”,你還得重視外部資料的分析!》的第一部分。
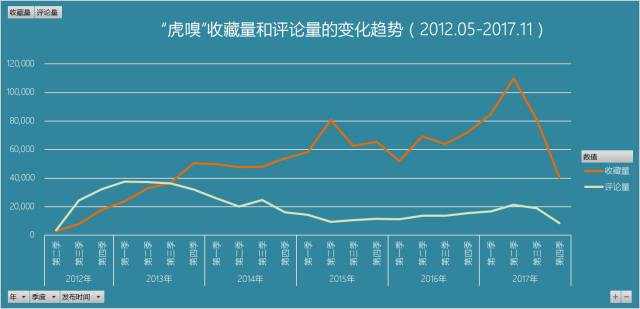
3.1 發文數量、評論量和收藏量的變化走勢
從下圖可以看出,在2012.05~2017.11期間,以季度為單位,主頁的發文數量起伏波動不大,在均值1800上下波動,進入2016年後,發文數量有明顯提升。
此外,一頭(2012年第二季)一尾(2017年第四季)因為沒有統計完全,所以發文數量較小。

下圖則是該時間段內收藏量和評論量的變化情況,評論量的變化不慍不火,起伏不大,但收藏量一直在攀升中,尤其是在2017年的第二季達到峰值。收藏量在一定程度上反映了文章的乾貨程度和價值性,讀者認為有價值的文章才會去保留和收藏,反覆閱讀,含英咀華,這說明虎嗅的文章質量在不斷提高,或讀者的數量在增長。
3.2 發文時間規律分析
筆者從時間維度裡提取出“周”和“時段”的資訊,也就是開題提到的“人工特徵”的提取,現在做文章分佈數量的在“周”和“時”上的交叉分析,得到下圖:

上圖是一個熱力圖,色塊顏色上的由暖到冷表徵數值的由大變小。很明顯的可以看到,中間有一個顏色很明顯的區域,即由“6時~19時”和“週一~週五”圍成的矩形,也就是說,發文時間主要集中在工作日的白天。另外,週一到週五期間,6時~7時這個時間段是發文的高峰,說明虎嗅的內容運營人員傾向於在工作日的清晨釋出文章,這也符合它的人群定位—TMT領域從業、創業者、投資人,他們中的許多人有晨讀的習慣,喜歡在趕地鐵、坐公交的過程中閱讀虎嗅訊息。發文高峰還有9時-11時這個高峰,是為了提前應對讀者午休時間的閱讀,還有17時~18時,提前應對讀者下班時間的閱讀。
3.3 相關性分析
筆者一直很好奇,文章的評論量、收藏量和標題字數、文章字數是否存在統計學意義上的相關性關係。基於此,筆者繪製出能反映上述變數關係的兩張圖。
首先,筆者做出了標題字數、文章字數和評論量之間的氣泡圖(圓形的氣泡被六角星替代,但本質上還是氣泡圖)。

上圖中,橫軸是文章字數,縱軸是標題字數,評論數大小由六角星的大小和顏色所反映,顏色越暖,數值越大,五角星越大,數值越大。從這張圖可以看出,文章評論量較大的文章,絕大部分分佈於由文章字數6000字、標題字數20字所構成的區域內。虎嗅網上的商業資訊文章大都具有原創、深度的特點,文章篇幅中長,意味著能把事情背後的來龍去脈論述清楚,而且標題要能夠吸引人,引發讀者的大量閱讀,合適長度標題和正文篇幅才能做到這一點。
接下來,筆者將收藏量、評論量和標題字數、文章字數繪製成一張3D立體圖,X軸和Y軸分別為標題字數和正文字數,Z軸為收藏量和評論量所構成的平面,透過旋轉這個3維的Surface圖,我們可以發現收藏量、評論量和標題字數、文章字數之間的相關關係。

註意,上圖的數值表示和前面幾張圖一樣,顏色上的由暖到冷表示數值的由大到小,透過旋轉各維度的截面,可以看到在正文字數5000字以內、標題字數15字左右的收藏量和評論量形成的截面出現“華山式”陡峰,因而這裡的收藏量和評論量最大。
3.4 城市提及分析
在這裡,筆者透過構建一個包含全國1~5線城市的詞表,提取出經過預處理後的文字中的城市名稱,根據提及頻次的大小,繪製出一張反映城市提及頻次的地理分佈地圖,進而間接地瞭解各個城市網際網路的發展狀況(一般城市的提及跟網際網路產業、產品和職位資訊掛鉤,能在一定程度上反映該城市網際網路行業的發展態勢)。
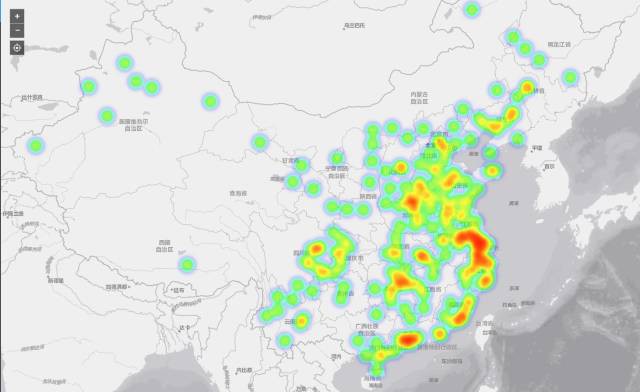
上圖反映的結果比較符合常識,北上深廣杭這些一線城市的提及次數最多,它們是網際網路行業發展的重鎮。值得註意的是,長三角地區的大塊區域(長江三角洲城市群,它包含上海,江蘇省的南京、無錫、常州、蘇州、南通、鹽城、揚州、鎮江、泰州,浙江省的杭州、寧波、嘉興、湖州、紹興、金華、舟山、台州,安徽省的合肥、蕪湖、馬鞍山、銅陵、安慶、滁州、池州、宣城)呈現出較高的熱度值,直接說明這些城市在虎嗅網各類資訊文章中的提及次數較多,結合國家政策和地區因素,可以這樣理解地圖中反映的這個事實:
長三角城市群是“一帶一路”與長江經濟帶的重要交匯地帶,在中國國家現代化建設大局和全方位開放格局中具有舉足輕重的戰略地位。中國參與國際競爭的重要平臺、經濟社會發展的重要引擎,是長江經濟帶的引領發展區,是中國城鎮化基礎最好的地區之一。
接下來,筆者將抽取文字中城市之間的共現關係,也就是城市之間兩兩同時出現的頻率,在一定程度上反映出城市間經濟、文化、政策等方面的相關關係,共現頻次越高,說明二者之間的聯絡緊密程度越高,抽取出的結果如下表所示:
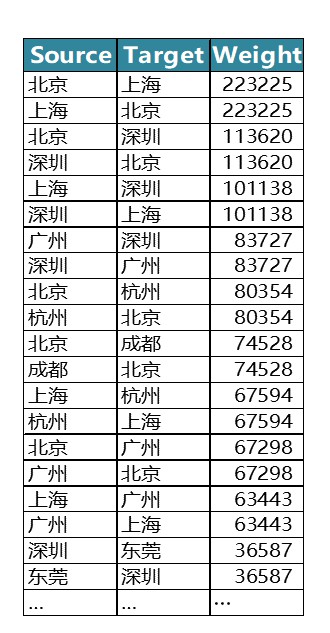
將上述結果繪製成如下動態的流向圖:

由於虎嗅網上的文章大多涉及創業、政策、商業方面的內容,因而這種城市之間的共現關係反映出城際間在資源、人員或者行業方面的關聯關係,本動態圖中,主要反映的是北上廣深杭(網路中的樞紐節點)之間的相互流動關係和這幾個一線城市向中西部城市的單向流動情形。流動量大、交錯密集的區域無疑是中國最發達的3個城市群和其他幾個新興的城市群:
-
京津冀城市群
-
長江三角洲城市群
-
珠江三角洲城市群
-
中原城市群
-
成渝城市群
-
長江中游城市群
上面的資料分析是基於數值型資料的描述性分析,接下來,筆者將進行更為深入的文字挖掘。
4 文字挖掘
資料挖掘是從有結構的資料庫中鑒別出有效的、新穎的、可能有用的並最終可理解的樣式;而文字挖掘(在文字資料庫也稱為文字資料挖掘或者知識發現)是從大量非結構的資料中提煉出樣式,也就是有用的資訊或知識的半自動化過程。關於文字挖掘方面的相關知識,請參看《資料運營|資料分析中,文字分析遠比數值型分析重要!(上)》、《在運營中,為什麼文字分析遠比數值型分析重要?一個實際案例,五點分析(下)》。
本文的文字挖掘部分主要涉及高頻詞統計/關鍵詞提取/關鍵詞雲、文章標題聚類、文章內容聚類、文章內容LDA主題模型分析、詞向量/關聯詞分析、ATM模型、詞彙分散圖和詞聚類分析。
4.1 關鍵詞提取
對於關鍵詞提取,筆者沒有採取詞頻統計的方法,因為詞頻統計的邏輯是:一個詞在文章中出現的次數越多,則它就越重要。因而,筆者採用的是TF-IDF(termfrequency–inverse document frequency)的關鍵詞提取方法:
它用以評估一字/詞對於一個檔案集或一個語料庫中的其中一份檔案的重要程度,字/詞的重要性會隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。
由此可見,在提取某段文字的關鍵資訊時,關鍵詞提取較詞頻統計更為可取,能提取出對某段文字具有重要意義的關鍵詞。
下麵是筆者利用jieba在經預處理後的、近400MB的語料中抽取出的TOP100關鍵詞。
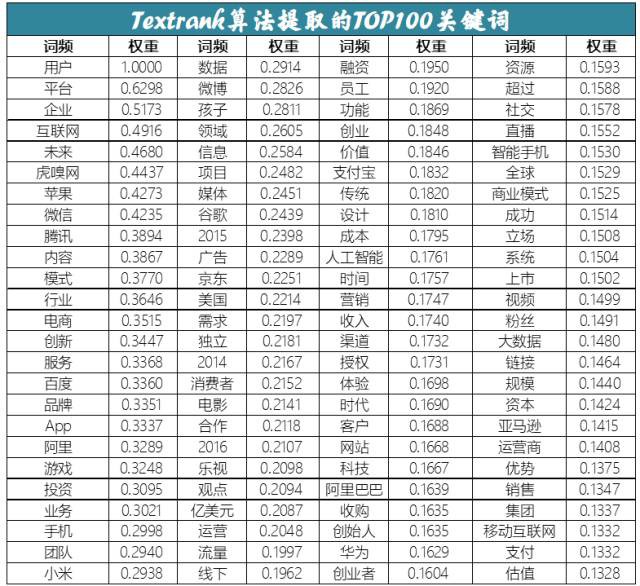
從宏觀角度來看,從上面可以明顯的識別出3類關鍵詞:
公司品牌類:虎嗅網、蘋果、騰訊、蘋果、小米等;
行業領域類:行業、電商、遊戲、投資、廣告、人工智慧、智慧手機等;
創業、商業樣式類:樣式、創新、業務、運營、流量、員工等。
從微觀角度來看,居於首要位置的是“使用者”,網際網路從業者放在嘴邊的是“使用者為王”、“使用者至上”和“以使用者為中心”,然後是“平臺”和“企業”。
筆者選取TOP500關鍵詞來繪製關鍵詞雲。因為虎嗅的名字來源於英國當代詩人Siegfried Sassoon的著名詩句“In me the tigersniffs the rose(心有猛虎,細嗅薔薇),所以詞雲以“虎嗅薔薇”為背景,找不到合適的虎嗅薔薇的畫面,於是用它的近親貓作為替代,詞雲如下:

4.2 LDA主題模型分析
剛才針對關鍵詞的分類較為粗略,且人為劃分,難免有失偏頗,達不到全面的效果。因此,筆者採用LDA主題模型來發現該語料中的潛在主題。關於LDA主題模型的相關原理,請參看《【乾貨】用大資料文字挖掘,來洞察“共享單車”的行業現狀及走勢》的第4部分。
一般情況下,筆者將主題的數量設定為10個,經過數小時的執行,得到如下結果:

可以看出,經過文字預處理後的語料比較純凈,透過每個主題下的“主題詞”,可以很容易的從這10個簇群中辨析出若干主題,不過,其中3個主題存在雜糅的情況(每個topic下包含2個主題),但這不影響筆者的後續分析,主題分類如下表所示:

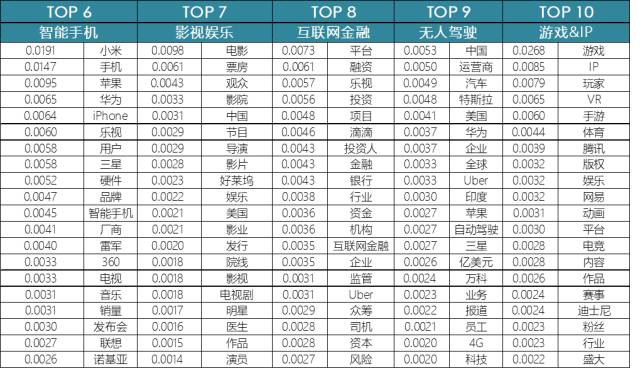
電商&O2O;: 該主題包含2個部分,即各大電商平臺(淘寶、京東等)上的零售;O2O(Online線上網店Offline線下消費),商家透過免費開網店將商家資訊、商品資訊等展現給消費者,消費者線上上進行篩選服務,並支付,線下進行消費驗證和消費體驗。
巨頭戰略:主要是國內BAT三家的營收、融資、併購,以及涉足網際網路新領域方面的資訊。
使用者&社交:主要涉及使用者和社會化媒體(微博、QQ、微信、直播平臺等)方面的資訊。
創業:涉及創業人、創新樣式、創業公司等一切關於創業的話題,令筆者印象最為深刻的是創業維艱。
人工智慧:進入移動網際網路時代,各類線上資料的不斷積累和硬體技術的突飛猛進,大資料時代已然來臨,隨之而來的還有人工智慧,該領域是時下國內外IT巨頭角逐的焦點。
智慧手機:智慧手機的普及是移動網際網路時代興起的催化劑之一,2012年以來,“東風(國內智慧手機企業)”逐漸壓倒“西風(國外智慧手機企業)”,國產智慧手機品牌整體崛起,蘋果、小米和鎚子的每一次手機釋出會總能在網際網路界引起一片熱議。
影視娛樂:影視文化產業作為政策力挺、利潤巨大的行業,吸引著無數資本的目光。在金融資本與電影產業碰撞出“火花”的背後,是中國影視消費市場的快速崛起。國外好萊塢大片的不斷引進和票房屢創新高,直接刺激著國內影視從業者提升自身的編劇和製片水平,由此誕生了一大批影視佳作,如近三年來的《夏洛特煩惱》、《湄公河行動》、《戰狼2》。
網際網路金融:網際網路金融(ITFIN)是指傳統金融機構與網際網路企業利用網際網路技術和資訊通訊技術實現資金融通、支付、投資和資訊中介服務的新型金融業務樣式。2011年以來至今,網際網路金融所經歷的是突飛猛進的實質性的金融業務發展階段,在這個過程中,國內網際網路金融呈現出多種多樣的業務樣式和執行機制。該主題下,第三個主題詞“樂視”赫然在目,從2014年年底賈躍亭宣佈樂視“SEE計劃“到2017年10月中旬,樂視網巨虧16億,賈躍亭財富縮水400億也不到3年,“眼看他起朱樓,眼看他宴賓客…“
無人駕駛:無人駕駛是透過人工智慧系統實現無人駕駛的智慧汽車,它在本世紀尤其是近5年呈現出接近實用化的趨勢,比如,谷歌自動駕駛汽車於2012年5月獲得了美國首個自動駕駛車輛許可證,現在特斯拉的無人駕駛汽車已經在市場上在銷售。隨著技術上和硬體上的不斷進步,它日趨成熟,成為國內網際網路巨頭的都想要摘得的桂冠。
遊戲&IP;:網路遊戲被指是除了網際網路金融之外撈金指數最強勁的網際網路行業,從最近”王者榮耀”成都主創團隊年終獎事件的引爆就能看出端倪,更不用說時下的流行語“吃雞”了;同時,隨著網際網路IP產業的不斷深化發展,體育、娛樂、文學等領域對版權和IP的重視程度越來越高,當下的網際網路+時代,IP更是呈現了多元化的發展形勢。
以下是上述各個話題在這4W多篇文章中的佔比情況,可以明顯的看出,虎嗅首頁上的文章對網際網路行業各大巨頭的行業動向報道較多,其次是不斷崛起的影視娛樂,除了無人駕駛方面的報道偏少以外,其他主題方面的文章的報道量差異不大,比較均衡。

再次是各主題的文章數量在時間上的變化情況:
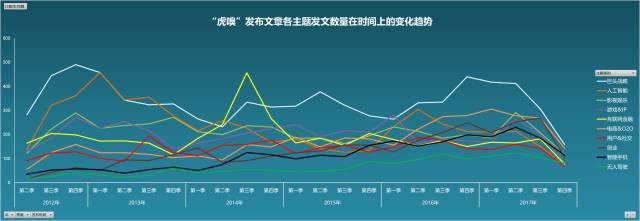
上圖中,我們可以明顯的看出“巨頭戰略”這一話題的首頁發文量始終維持在一個較高的水平,其次是“人工智慧”的話題,它在虎嗅網主頁2013年第一季度出現一個報道小高潮。值得註意的是,“網際網路金融”在2014年第3個季度的報道量較大,從中可以獲悉這個階段的網際網路金融正處於一個爆發的階段,這個時段互金行業的重大事件有:小米投資積木盒子進軍網際網路金融(9.10)、京東釋出消費金融戰略(9.24)、螞蟻金服集團成立(10.16),以及整個2014年是“眾籌元年”,P2P步入洗牌季、以及央行密集令直指監管網際網路金融,這些事件或政策都足以引發網際網路界人士的熱議,造成這一時段聲量的驟然升起。
4.3 情緒分析&LDA;主題模型交叉分析
結合上述LDA主題模型分析的結果,筆者使用新浪微輿情的情緒語意分析模型(該模型有6類情緒,即喜悅、憤怒、悲傷、驚奇、恐懼和中性),對這些文章的標題進行情緒分析,得出各個文章的情緒標簽,處理結果如下表所示:

將主題和情緒維度進行交叉分析,得出下圖:

從上圖中可以看出,各個主題下的標題的情緒以中性為主,凸顯作者和官方的客觀和中立態度,但是在現今標題黨橫行和全民重口味的時代,擬標題上的過分中立也意味著平淡無奇,難以觸發讀者的閱讀行為,正所謂“有性格的品牌,有情緒的營銷”,能成功挑起讀者情緒的作者絕對是高手,所以,在上圖中除了中性情緒外,居於第二位的是憤怒,狂撕狂懟,點燃讀者的情緒;再次是悲傷,在現實生活中,傷感總能引起同情與共鳴。
4.4 ATM模型
在這個部分,筆者想瞭解“虎嗅網上各個作家的寫作主題,分析某些牛X作家喜歡寫哪方面的文章(比如“行業洞察”、“爆品營銷”、“新媒體運營”等),以及寫作主題類似的作者有哪些。
為此,筆者採用了ATM模型進行分析,註意,這不是自動取款機的縮寫,而是author-topicmodel:
ATM模型(author-topic model)也是“機率主題模型”家族的一員,是LDA主題模型(Latent Dirichlet Allocation )的拓展,它能對某個語料庫中作者的寫作主題進行分析,找出某個作家的寫作主題傾向,以及找到具有同樣寫作傾向的作家,它是一種新穎的主題探索方式。
首先,筆者去除若干釋出文章數為1的作者,再從文字中“析出”若干主題,因為文字數量有刪減,所以跟之前的主題劃分不太一致。根據各個主題下的主題詞特徵,筆者將這10個主題歸納為 :“行業新聞”、“智慧手機”、“創業&投融資”、“網際網路金融”、“新媒體&營銷”、“影視娛樂”、“人工智慧”、“社會化媒體”、“投融資&併購”和“電商零售”。

接下來,筆者將會對一些自己感興趣的作者的寫作主題及其相關作者進行一定的分析。
首先是鎚子科技的創始人羅永浩,筆者一直認為他是一個奇人,之前看到他在虎嗅網上有署名文章,所以想看他在虎嗅網上寫了啥:
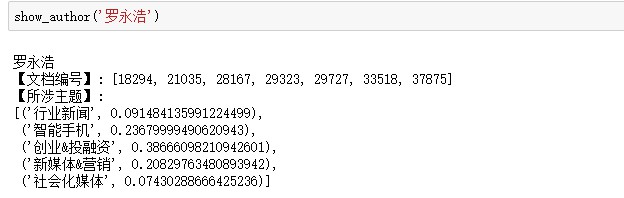
從老羅的寫作主題及其機率分佈來看,他比較傾向於寫創業、融資、智慧手機和新媒體營銷方面的文章,這個比較符合大眾認知,因為善打情懷牌的老羅喜歡談創業、談自己對於手機的理解,而且由於自己鮮明的個性和犀利的語言,他常常在為自己的鎚子品牌代言。
根據檔案ID,筆者找到了他釋出的這幾篇文章:
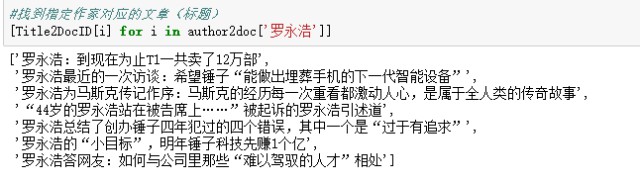
單看標題,ATM模型還是蠻聰明的,能從老羅的文章中學習到了他的寫作主題。
接下來是寫作主題與老羅相近的虎嗅網作家,他們的釋出文章數大於3篇:

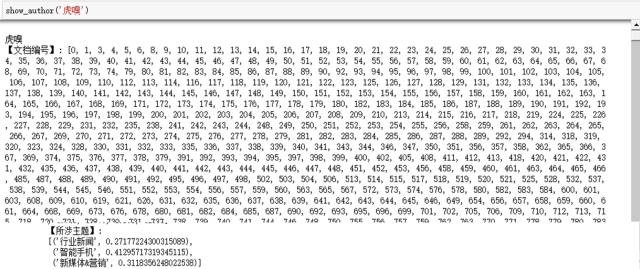
接下來是虎嗅自己的媒體,主頁上發文量破萬,所涉及的寫作主題集中在“行業新聞”、“智慧手機”和“新媒體&營銷”:
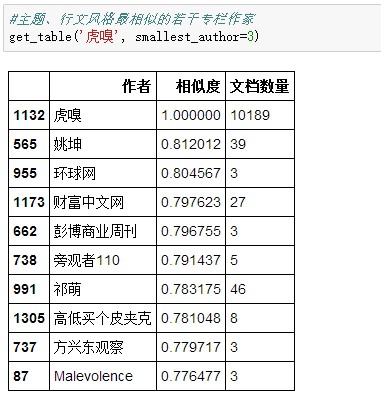
與其寫作主題類似的作者除了一些個人自媒體人,還包括一些媒體,如環球網、財富中文網、彭博商業週刊等。從前面的分析中可以推測出,他們在上述3個話題上的發文量也比較大。
在這10,189篇文章裡,筆者按檔案ID隨機抽取出其中的若干篇文章的標題,粗略驗證下。然後,把這些標題繪製成獨角獸形狀的詞雲。

由上面的標題及其關鍵詞雲,預測的主題還是比較合理的。
再看看另外兩個筆者比較感興趣的自媒體—混沌大學和21世紀經濟報道。


從上面2個圖可以看出,混沌大學關註的領域主要是“創業&投融資”、“新媒體&營銷”方面的話題,偏向於為創業者提供創業相關的技能;而21世紀經濟報道則更青睞“投融資&併購”、“行業新聞”和“智慧手機”方面的話題,這比較符合該媒體的報道風格—分析國際形式、透視中國經濟、觀察行業動態和引導良性發展,有效地反映世界經濟格局及變化,跟蹤報道中國企業界的動態與發展。
4.5 詞彙分散圖
接下來,筆者想瞭解虎嗅網主頁這4W+文章中的某些詞彙在2012.05~2017.11之間的數量分佈和他們的位置資訊(the locationof a word in the text),這時可以利用Lexical dispersion plot(詞彙分散圖)進行分析,它可以揭示某個詞彙在一段文字中的分佈情況(Producea plot showing the distribution of the words through the text)。
筆者先將待分析的文字按時間順序進行排列,分詞後再進行Lexical DispersionPlot分析。因此,文字字數的累積增長方向與時間正向推移的方向一致。圖中縱軸表示詞彙,橫軸是文字字數,是累加的;藍色豎線表示該詞彙在文字中被提及一次,對應橫軸能看到它所處的位置資訊,空白則表示無提及。藍色豎線的密集程度及起位置代表了該詞彙在某一階段的提及頻次和所在年月。
從上面的關鍵詞和主題詞中,筆者挑揀出14個詞彙進行分析,結果如下:

從上圖中可以看出,“智慧手機”、“移動支付”、“O2O”和“雲端計算”這4個詞在近6年的熱度居高不下,提及頻次很高,在條柱上幾近飽和。相較之下,“網際網路教育”、“3D列印”、“線上直播”這些在虎嗅網上的報道量不大,從始至終只是零零星星的有些提及。
值得註意的是,“共享單車”在後期提及次數顯著增加,而且是爆髮式的出現,這與共享單車出現比較吻合,關於共享單車方面的資料分析,請參看《【乾貨】用大資料文字挖掘,來洞察“共享單車”的行業現狀及走勢》。
4.6 詞向量/關聯詞分析—當我們談論XX時 我們在談論什麼
基於深度神經網路的詞向量能從大量未標註的普通文字資料中無監督地學習出詞向量,這些詞向量包含了詞彙與詞彙之間的語意關係,正如現實世界中的“物以類聚,類以群分”一樣,詞彙可以由它們身邊的詞彙來定義(Words can be defined by the company they keep)。
從原理上講,基於詞嵌入的Word2vec是指把一個維數為所有詞的數量的高維空間嵌入到一個維數低得多的連續向量空間中,每個單詞或片語被對映為實數域上的向量。把每個單詞變成一個向量,目的還是為了方便計算,比如“求單詞A的同義詞”,就可以透過“求與單詞A在cos距離下最相似的向量”來做到。
接下來,透過Word2vec,筆者查找出自己感興趣的若干詞彙的關聯詞,從而在虎嗅網的這個獨特語境下去解讀它們。
由此,筆者依次對“百度”、“人工智慧”、“褚時健”和“羅振宇”這幾個關鍵詞進行關聯詞分析。

出來的都是與百度相關的詞彙,不是百度的產品、公司,就是百度的CEO和管理者,“搜尋”二字變相的出現了很多次,它是百度起家的一大法寶。
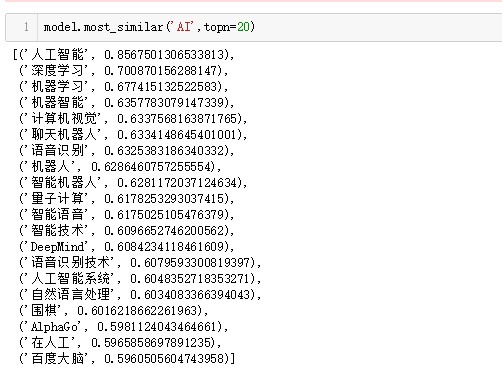
與“AI”相關的詞彙也是很好的解釋了人工智慧的細分領域和目前比較火的幾個應用場景。

與褚時健一樣,相關詞中前幾位名人(牛根生、胡雪巖、魯冠球、王永慶和宗慶後)也是名噪一時的商業精英,“老爺子”、“褚老”、“橙王”是外界對其的尊稱。有意思的是,褚老也有一些政治人物(毛主席和蔣委員長)那樣的英雄氣概,其人其事大有“東隅已逝,桑榆非晚”、“待從頭,收拾舊山河”的豁達精神和樂觀主義!

再就是資深媒體人和傳播專家羅振宇了,“知識變現”的踐行者,他的許多見解都能顛覆群眾原有的觀念。與羅胖相類似的人還有申音(網際網路真人秀《怪傑》的創始人和策劃人,羅振宇的創業夥伴)、吳曉波(吳曉波頻道和社群的創始人)、Papi醬(知名搞笑網紅)、馬東(現“奇葩說”主持人)、李翔(得到APP上《李翔商業內參》的推出者)、姬十三(果殼網創始人)、李笑來(財務自由知名佈道者)、吳伯凡(詞沒切全,《21世紀商業評論》發行人,作品有《冬吳相對論》和《伯凡日知錄》)…
4.7 對網際網路百強公司旗下品牌的詞聚類與詞分類
2016年網際網路百強企業的網際網路業務收入總規模達到1.07萬億元,首次突破萬億大關,同比增長46.8%,帶動資訊消費增長8.73%。資料顯示,網際網路領域龍頭企業效應越來越明顯,對他們的研究分析能幫助我們更好的瞭解中國網際網路行業的發展概況和未來方向。
筆者在這裡選取2016年入選的網際網路百強企業,名單如下:

對於上述百強網際網路公司的旗下品牌名錄,筆者利用上面訓練出來的詞向量模型,用來進行下麵的詞聚類和詞分類。
4.7.1 詞聚類
運用基於Word2Vec(詞向量)的K-Means聚類,充分考慮了詞彙之間的語意關係,將餘弦夾角值較小的詞彙聚集在一起,形成簇群。下圖是高維詞向量壓縮到2維空間的視覺化呈現:

筆者將詞向量模型中所包含的所有詞彙劃定為300個類別,看看這種設定下的品牌聚類效果如何。分析結果和規整如下所示:


從上述結果來看,有些分類是比較好理解的,如途風(網)和驢媽媽旅遊網,都是做旅遊的,人人貸、陸金所和拍拍貸是搞互金的,這些詞彙是在“行業的語境”裡出現的次數較多,基於同義關係聚類在一起,同屬一個行業。但其中大多數的聚類不是按行業來的,而是其他的語境中出現,且看下麵這兩段話:
第一波人口紅利是從2011年開始的,這波人口是原來核心的三億重度網際網路網民,或者簡單地說,是那個年代去買小米手機和iPhone的這波使用者,當然也包括三星。他們是一二線城市裡邊比較偏年輕的這些人口。所以你看包括我們自己投資的美圖、知乎、今日頭條、小米都是跟著這波人口起來的。
第二波人口是從2013年、2014年開始發生的,這波人口是什麼?這波人口實際上是移動網際網路往三四線城市下沉造成的人口紅利,是二三四線城市裡面比較年輕的人口。大家簡單想一下買OPPO、ViVO手機的人。這波紅利帶來了包括快手、映客等一系列的興起,包括微博的二次崛起。
上面加粗加黑的品牌雖然不同屬一個行業,但都出現在“移動網際網路的人口紅利”的語境中,所以單從這個語境來說,它們可以聚為一類。
所以,上述的聚類可能是由於各類詞彙出現在不同的語境中,深挖的話,或許能發現到若干有趣的線索。篇幅所限,這個就留給有好奇心的讀者來完成吧。
4.7.2 詞分類
在這裡,筆者還是利用之前訓練得出的詞向量,透過基於CNN( ConvolutionalNeural Networks,摺積神經網路)做文字分類,用來預測。CNN的具體原理太過複雜,筆者在這裡不做贅述,感興趣的小夥伴可以查閱後面的參考資料。

由於文字分類(Text Classification)跟上面的文字聚類(Text Cluster)在機器學習中分屬不同的任務,前者是有監督的學習(所有訓練資料都有標簽),後者是無監督的學習(資料沒有標簽),因而,筆者在正式的文字分類任務開始前,先用有標註的語料訓練模型,再來預測後續的未知的文字。
在這裡,筆者根據網際網路企業所屬細分領域的不同,劃分為17個類別,每個類別隻有很少的標註語料參與訓練,也就是幾個詞罷了。對,你沒看錯,藉助外部語意資訊(之前訓練好的詞向量模型,已經包含有大量的語意資訊),你只需要少許的標註語料就可以完成分類模型的訓練。

接著,筆者用之前未出現在訓練語料中的詞來檢驗效果,出來的結果是類別標簽及其對應的機率,機率值大的類別是品牌最有可能從屬的細分領域。結果如下圖所示:

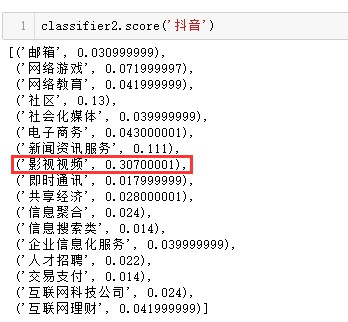


上述的結果都符合大家的基本認知,小規模測試下,準確率尚可,最後來一個難度大一點的,國外一家筆者從未知曉的網際網路公司:
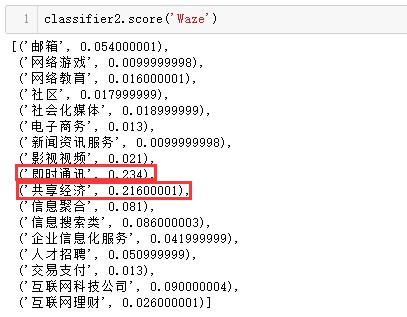
透過Google,筆者瞭解到Waze是以色列一家做眾包導航地圖的科技公司。前一段時間火了一把,被Google 10億美元收購了。其產品雖然沒有Google地圖那樣強大的衛星圖片作支撐,但是可以向用戶社群提供有關交通狀況、交通事故以及測速區等實時資訊(地圖彈幕即視感)。“眾包”和“實時資訊”分別對應“共享經濟”和“即時通訊”,比較符合預測標簽所表徵的內涵,能在一定程度上預測出該企業的業務屬性。
4.8 網際網路百強公司的共現分析
上面所做的關於網際網路百強公司的聚類分析和分類分析,看起來是“黑匣子”,其內在的機理,我們不太容易理解。接下來,筆者將基於“圖論”來做品牌共現分析,從網路的角度來分析百強企業品牌之間的關聯關係。
提取出上述百強企業品牌的相互共現關係,形成如下的社交網路圖:

上圖中,每個節點代表一個人物,線條粗細代表品牌與品牌之間的強弱連結關係,相同顏色的節點表示它們(在某種條件下)同屬於一類。節點及字型的大小表示品牌在網路中的影響力大小,也就是“Betweenness Centrality(中介核心性),”學術的說法是“兩個非鄰接的成員間的相互作用依賴於網路中的其他成員,特別是位於兩成員之間路徑上的那些成員,他們對這兩個非鄰接成員的相互作用具有某種控制和制約作用”。說人話就是,更大的影響力就意味著該品牌連結了更多的合作機會和資源,以及涉足更多的網際網路領域。
先看裡面影響力TOP10,依次是騰訊、微信、百度、QQ、阿裡巴巴、淘寶、京東、小米、網易和新浪微博,“騰訊系”在10強裡佔據了3個席位,實力強大,可見一斑。
再看由顏色區分出的6個簇群:
淡藍系:騰訊、微信、百度、QQ、網易、搜狐…
洋紅系:阿裡巴巴、淘寶、京東、新浪微博、天貓…
深綠系:小米、多看、MIUI、天翼閱讀…
淺綠系:樂居、房天下
明黃系:人人貸、拍拍貸
黃橙系:汽車之家、易車網、易湃
上述的分類,大部分是好理解的, 淺綠系(樂居、房天下)是做房產的,明黃系(人人貸、拍拍貸)是搞網際網路P2P金融的,而黃橙系(汽車之家、易車網、易湃)是網際網路汽車領域的品牌。
值得註意的是,深綠系的小米、多看、MIUI、天翼閱讀,以小米為中心MIUI是小米的產品,多看(閱讀)已經被小米收購,天翼閱讀一度是小米捆綁的閱讀軟體,然而,蝸牛遊戲就跟前幾個不同,有一篇文章的標題是這樣的:“蝸牛釋出移動戰略,石海:不做小米第二”,它是小米在移動遊戲領域的對手…
此外,淡藍系(騰訊、微信、百度、QQ、網易、搜狐等)和洋紅系(阿裡巴巴、淘寶、京東、新浪微博、天貓等)這兩個簇群中,品牌與品牌之間的關係就比較複雜了,子母公司、兄弟品牌、跨界合作、競對關係、跨界競爭、融資及兼併,上述情況,在這兩類簇群中或可兼而有之。
結語
在本文的文字挖掘部分,涉及到人工智慧/AI這塊的內容—關鍵詞提取、LDA主題模型、ATM模型屬於機器學習,情緒分析、詞向量、詞聚類和詞分類涉及到深度學習方面的知識,這些都是AI 在資料分析中的真實運用。
此外,本文是探索性質的資料分析乾貨文,不是資料分析報告,重在啟迪思路,授人以漁,得出具體的結論不是本文的目的,對結果的分析分散在各個部分,“文末結論控”不喜勿噴。
參考資料:
1.資料來源:虎嗅網主頁,2012.05-2017.11
2.蘇格蘭折耳喵,《資料運營|資料分析中,文字分析遠比數值型分析重要!(上)》
3.蘇格蘭折耳喵,《在運營中,為什麼文字分析遠比數值型分析重要?一個實際案例,五點分析(下)》
4.蘇格蘭折耳喵,《乾貨|如何利用Social Listening從社會化媒體中“提煉”有價值的資訊?》
5.蘇格蘭折耳喵,《乾貨|作為一個合格的“增長駭客”,你還得重視外部資料的分析!》
6.蘇格蘭折耳喵,《以《大秦帝國之崛起》為例,來談大資料輿情分析和文字挖掘》
7.蘇格蘭折耳喵,《【乾貨】用大資料文字挖掘,來洞察“共享單車”的行業現狀及走勢》
8.Word2vec維基百科詞條,https://en.wikipedia.org/wiki/Word2vec
9.“工信部發2016年中國網際網路企業100強名單”,http://tech.163.com/16/0712/18/BRPTFD6E00097U7R.html
10.宗成慶,《自然語言理解:(06)詞法分析與詞性標註》,中科院
11.UnderstandingConvolutional Neural Networks for NLP ,http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp
12.Yoon Kim,Convolutional Neural Networks for Sentence Classification
13. Hoffman, Blei, Bach. 2010. Online learning for LatentDirichlet Allocation
14.TomasMikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of WordRepresentations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
15.TomasMikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. DistributedRepresentations of Words and Phrases and their Compositionality. In Proceedingsof NIPS, 2013.
●編號379,輸入編號直達本文
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦:《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
