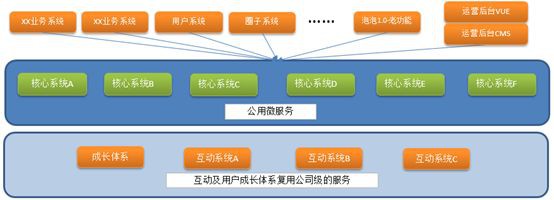
微服務不是萬能的,也不要為了微服務而微服務。能夠支援業務在各個階段的成長是第一位的,就好比泡泡平臺從最開始定位的的社交(聊天、發帖),到目前的明星、興趣社群和運營推廣,再到未來的不同業務的基礎平臺,每一步的業務成長都是促使我們技術演進的最強動力。
對於一個6千萬日活的系統,任何架構改變都務求謹慎,本文講述了愛奇藝泡泡系統微服務實施過程中的思考和經驗。
愛奇藝移動App的右下角常駐著一個泡泡的圖示,點選即可進入一個精彩的世界。泡泡定位的發展戰略是融合內容、播出、宣發、粉絲四大平臺為一體,目前更通用的產品的說法是娛樂粉絲社群,在此平臺上可以聚攏相似愛好的使用者群體,並組織內容。熟悉微博和貼吧等產品的讀者相信對此一定不會陌生。該系統目前高峰DAU超過6千萬,算是一個體量比較大的平臺。在一些大咖位的明星來線上做互動(明星翻牌)活動時,單單一條Feed(可以理解成是一條微博)內容一小時內評論樓數超過60萬。系統整體QPS超過100K/s。
每一個社群在泡泡產品形態中就是一個”圈子”,圈子的型別有多種(明星圈、影片圈、興趣圈、遊戲圈、漫畫圈、圖書圈、等等),不同型別的圈子也有不同的玩法,比如明星圈可以做積分任務、為喜歡的愛豆打榜、發起對應明星的應援活動(眾籌)、追蹤明星的行程資訊等等;影片圈裡面可以直接看影片等。每個圈子下麵彙集了使用者自發、編輯運營的相關內容(我們叫做Feed流),以及相關圈子的周邊資訊(比如明星圈可以查明星資料,影片圈可以查同一個導演的相關影片等)。
技術上與一般的頁面服務不同的是,泡泡系統的讀寫操作同樣重要,對於明星圈甚至是寫操作更重要,使用者非常在意自己做任務的積分、打榜貢獻是否正確的加上了。所以寫操作要有一定程度的事務支援。
由於歷史原因,最初時候,泡泡後臺、運營後臺和feed系統,這三個系統程式碼在一個工程當中,共用底層的儲存資源,只是在程式碼層面透過不同的model來區分。每當有一個模組有改動的時候,很容易相互幹擾。
隨著使用者量的增長和業務的發展,這種結構遠遠不能滿足需求。在這種矛盾的情況下,我們進行了拆分,由單一專案拆分成了泡泡後臺、運營後臺、feed後臺三個專案。 同時,將儲存也剝離開來。大大降低程式碼改動和上線的風險。這種方式,也帶來了其他的問題,資源佔用集中(db、cb、redis等),運維成本增加。
運營層面,最開始的重點是明星圈子,泡泡平臺的定位即是明星業務,打造粉絲社群,這是一個單一的平臺,業務也相對單一。後續,運營層面增加了影片、遊戲、漫畫等業務。未來,將向著平臺化的方向發展。
綜合這些問題,加上分析和調研的結果,我們打算引入微服務。

首先說拆分的目的:永遠都是為業務服務,實現公司業務的不斷增長和演進是我們的終極標的。
泡泡後臺從2016年上半年上線初始的幾百萬日活,到現在的接近7千萬日活,後臺系統的技術棧也需要不斷地迭代。形象點的例子是最初的泡泡系統是一棵小樹,不斷長大到一定程度就需要不斷的剪枝,栽培更多的小樹。在當初幾百萬日活的情況下完全沒有微服務化的必要,當時一切都是以功能快速上線為標的的;但是經過一年多的發展,以現在的視角來看,之前的架構慢慢顯得臃腫,開發效率逐漸降低,維護的成本卻在不斷攀高,微服務化能夠給我們帶來未來一段時間更好的發展。
另外一個方面是泡泡後臺的定位也從最初的明星圈+影片圈,演進到了未來平臺級的系統,可以更好地支援細分的各類興趣圈以及公司其他的垂直業務。所以泡泡要做面向業務到面向平臺+業務的轉變。
從技術角度講,泡泡系統的微服務化主要為了達到幾個目的:
-
系統和人員可以分而治之,獲得更高的開發和維護效率(DevOps)
-
持續最佳化(ownership)、更專業的人員做更專業的事情
松耦合很好理解,服務彼此獨立,修改一個服務不要影響其使用方。比如使用者相關的功能全部由使用者微服務實現、圈子相關的功能全部由圈子微服務實現,彼此之間如需互動則透過通用(最好還是統一的)介面來實現。內聚性還包括資料的內聚,使用者的資訊只存在使用者微服務中,其他服務需要的時候透過介面去獲取。
那麼問題來了,使用方是否需要快取使用者資訊呢?——我們的答案是,唯一需要快取的場景是使用方不信任服務提供方的服務級別(萬一服務宕機了怎麼辦,萬一網路故障了怎麼辦)。這種情況在公司內部普遍存在,如果大家自由發揮那麼到最後一定變成了呼叫鏈上每一步都加一道快取,對資源是一定的浪費,且容易引起資料不一致的情況。
那麼我們的原則是:關鍵資料(獲取不到會較大範圍地影響使用者體驗或資料異常)和使用量大的資料(使用方不快取的話就會對服務提供方帶來超高的QPS)需要快取,其餘的資料儘量透過微服務層面直接獲取。松耦合和內聚性還有另外一點,就是服務之間大家建立好契約(往往是介面規範),只要介面不改內部實現隨你去折騰吧,結果就是介面層面的更改大家會更加謹慎,減少了很多聯調成本。
服務化相比元件化,由行程內部的呼叫改為了服務間的呼叫,引入了網路IO等額外的效能損耗,所以拆分服務的過程中通常會遇到的一個難題就是如何保證效能。
目前市面上實現起來比較靈活的方案是以RESTful風格的的介面來界定各個子系統的切麵,但是這種基於http的協議犧牲了效能來達到這個靈活,每次請求的http握手無形中浪費了大量的系統資源。與之對比的是各種RPC方案,採用長連線+壓縮過的序列化資料傳輸,可以一定程度地減少網路開銷,也就提高了效能。對比一下單機http服務和RPC服務的壓測結果就可以看出來,兩種協議至少在能夠支撐的QPS上相差了10倍以上。但是RPC的缺點也比較明顯,對客戶端是有侵入的,增加了系統耦合性,且排除故障時也相對困難。
最終鑒於泡泡系統較高的QPS要求,我們在多數對內服務的微服務系統上使用了RPC框架、少量QPS要求不高的系統保留http服務,對App端統一由mixer層實現http服務。以使用者RPC服務為例,高峰時段整體QPS為40K,單臺QPS保持在2500左右(壓測單臺QPS可支撐10K+)。介面響應時間在5ms以下。同http服務對比RPC效能優勢明顯。
這裡拿RPC框架選型為例:市面上存在大量的RPC框架(Solar、gRPC、Dubbo、甚至Spring Cloud等),但是我們最終選擇了愛奇藝移動後端團隊基於thrift實現的RPCHUB框架。
原因就是這個框架在移動後臺線上執行超過1年的時間,泡泡期望可以少踩些坑,並且在出現問題時可以直接找到最熟悉框架程式碼的開發人員來支援。而使用開源框架的話,雖然團隊中的過半數成員在之前其他公司的工作經歷中都或多或少地使用過一兩種開源框架,但是統計了一下真正讀過框架原始碼的同學並不多,即使讀過原始碼萬一遇到冷門點的問題也很可能抓瞎。
兩相權衡我們最後還是選擇了內部使用經驗豐富的框架RPCHUB,即使這樣我們在使用的過程中也遇到了一些問題,花了些時間來解決(框架升級了2個小版本來解決這些bug)。
我們的理論是隻要拆分合理,各自為戰是可以的。目前泡泡系統已經做到了誰構建、誰執行,我們發現大家的主人翁意識(內部我們通常說ownership)更強了,上線前開發自己把關更嚴格了,線上問題處理也更加積極。但架構以及服務實現的程式語言,還是儘量做到統一,主要也是為了少踩坑。
我們團隊目前都是Java背景,即使需要實現一個多執行緒的微服務聽起來用Go比Java簡單很多,但是把大部門第一個Go語言的服務推上線,需要做的相關測試工作聽聽就頭大。
那麼多小的服務算微服務呢?——沒有拆分的動力就可以了!說明沒有痛點了,也就沒有拆分的必要了,目前我們根據自身的業務情況選擇了以業務物體和業務功能兩種拆分方式。
在泡泡業務上,我們把物體劃分為圈子、使用者、事件、資源位等。在拆分前,泡泡API和運營後臺會共同維護這些物體,經常會出現資料不一致的情況,所以我們決定對這些物體進行拆分,按照物體型別拆分出多個微服務,每個微服務只負責該物體的功能,併在泡泡API和運營後臺及其他使用方中接入對應的微服務。
當然,拆分是一個緩慢的過程,在拆分時,我們優先選擇了業務較為單一的事件物體進行了拆分,為該物體申請了獨立的儲存資源,並採用統一的RPCHUP框架完成了事件微服務的拆分。之後針對事件物體相關的新需求,在不需要修改RPC介面協議的情況下,我們只需要在事件微服務中增加功能即可。
同時,別的業務系統若需要獲取某種物體資訊,直接接入對應的微服務即可。基於此思路,我們後續又完成了圈子、使用者、資源位等其它單獨物體的拆分。
在業務功能上,我們從泡泡API中優先選擇了簽到和圈友關係兩個模組作為微服務,用於服務各種型別的圈子。以簽到模組為例,在拆分前,經常會有使用者報障說簽到不成功,在定位問題時發現,快取的寫操作偶爾會出現操作成功,但是資料未更新的情況,懷疑是快取QPS太高導致(當然還有其他問題,包括資料庫壓力大、表結構設計缺陷、快取結構的設計缺陷等)。剛開始我們打算透過拆資源的方式解決,但又鑒於簽到功能的相對獨立以及泡泡後期的平臺化,我們最終決定申請新資源並將簽到功能拆分為一個獨立的服務。
從實施效果來看,拆分出的微服務功能還是非常穩定的,未再出現過類似報障。
目前主流的思想並未把SOA算作真正的微服務,因為SOA方案往往有個ESB彙總了所有資料流和業務流,即將單行程大服務的複雜度轉移到了ESB上,問題並沒有解決。而我們真正期望做的事情可以參考第一條原則,即松耦合和高內聚,所以我們期望的是,各個微服務之間自己維護自己的呼叫關係,按需互動。(順便說一下,筆者之前就做了很長時間的訊息中介軟體和ESB產品的開發,對這個領域可以說是充滿了感情,目前在銀行業中他們其實還算是主流方案)
另外,這裡提一個經典的誤區:有些人認為把一個單行程系統改造為若干微服務,可以簡單地實現為把行程內的方法呼叫改為RPC呼叫。這就大錯特錯了,這樣會導致微服務之間產生繁瑣的通訊(單行程間的方法呼叫是沒問題的,所以大家很容易忽略其中的問題,可是RPC呼叫要考慮網路開銷),這個也是必須要避免的,微服務一定要考慮通訊機制,好在微服務一旦實現了松耦合和高內聚,這個問題就可以很大程度避免。
服務之間的呼叫不比行程內的方法呼叫,出錯的機率大大加強了,所以我們考慮了幾個容錯的機制:非同步化、熔斷機制、寫操作的資料最終一致性。
方法呼叫基本都是同步的,行程內的呼叫沒問題,但是服務間很多同步呼叫就需要使用非同步化了,否則同步等待的時間過長服務可能會被拖死,我們大量地使用了MQ機制。
萬一網路故障了10分鐘怎麼辦?這時熔斷機制(我們使用了Hystrix熔斷框架)就大顯身手了。
以前同一個行程寫兩張表很容易做到事務一致性,現在兩張表拆到了兩個不同的服務中了怎麼辦?考慮到成本和真實的需要,我們使用了重試和最終一致的方案。
受限於CAP原則(感興趣的讀者可以在網上自行學習相關內容),一致性、可用性和分割槽容忍性已經多次被證明只能滿足其中的兩個,對於泡泡這樣的大併發分散式後臺系統來說分割槽容忍性是基本需求,那麼只能在一致性和可用性之間取一個權衡。我們分析了自己的業務,很多敏感的資料其實不見得需要強一致性,比如使用者的積分資料,HBase和快取之間就不需要強一致性,保證最終一致就可以了,所以我們取的是可用性舍的是強一致性。
舉個例子,使用者在獲得了新積分後我們在介面層面就更新了快取以保證使用者儘快能看到變更,但是寫HBase和ElasticSearch等持久化儲存是一個相對較慢的過程,沒必要與寫快取捆綁在一個全域性事務中(而且也不支援)。我們採用了非同步(透過MQ)的方式寫這些持久化儲存。但是寫HBase和ElasticSearch有可能因為各種原因失敗,使用者的快取失效後看到的資料不對就尷尬了。所以需要保證快取和持久化儲存裡面的資料最終一致。
TCC(每個業務方實現try、confirm、cancel介面,出現事務不一致時由中心協調器來統一排程事務恢復,感興趣的讀者可以自行學習一下相關概念)是一種比較常見的最終一致性方案,但是改造的成本不小,涉及到的各個子系統均需要改造。針對積分的場景,泡泡使用了簡單的重試的方式,即寫快取失敗的話介面就傳回失敗,任何資料都保持在寫介面被呼叫前的狀態,由業務來重新提交(其實深究起來這一步也可能有不一致的情況,比如寫快取超時,但是其實是成功了,這個需要業務能夠有一定的去重能力,在這裡咱們先不追求一步到位);如果寫持久化儲存失敗了,我們引入了一個任務表,寫失敗了就記錄在這個任務表中,由後臺task定期地重試寫入,直到超過了一定的時間或次數還一直寫不成功,那麼我們把這樣的臟資料報出來單獨處理(上線以來一直沒遇到過)。
我們可以有很長的時間視窗去非同步寫入以及重試寫入持久化的資料,這個方案的改造成本非常小,沒有任何阻力就在團隊內部推廣到位了(當然,這個方案也不是100%完善的,比如寫持久化儲存和寫任務表有可能都失敗了,那麼快取中和持久化儲存中的資料還是會不一樣。但是這種場景出現的機率實在太小了,所以我們沒有再花額外的精力去處理)。
第一個微服務上線,監控報警、持續交付(部署、自動化測試)、資料統計等等工具還屬於空白。在移動後端運維團隊(其實也只有兩個人)的幫助下這些工具完成了從東拼西湊到整齊劃一,保證了後續微服務的快速上線。未來也會考慮在技術積累的前提下輸出方案。
微服務拆分始終是個動態的過程,今天看似合理的架構或系統邊界,隨著業務的增長和需求的迭代,半年以後可能就跟不上業務了,那麼到時候再繼續拆分工作和演進。泡泡系統一路走來,也是邊實現需求邊思考架構演進的狀態。
-
為了相容歷史版本App,原來的服務還繼續保留(泡泡1.0老功能)。
-
新的服務以及比較獨立成塊的功能(比如圈子服務、使用者服務、群聊服務等)都相繼拆分成了獨立的服務(對App服務,http介面)。
-
公用的元件由元件化改為了公共微服務(RPC介面,比如圈子物體、使用者物體、使用者加圈關係、事件話題、資源位、簽到等)。
-
之前拆分的運營後臺還是基於JSP的,使用VUE做了前後分離,前後端開發人員可以更專註自己擅長的工作。
-
此外,泡泡後臺組還維護了一些全公司級別的服務,比如評論、點贊、投票、積分(使用者成長體系)等,這些也都重新規劃了系統邊界,該拆的拆該合的合,使每一個系統的維護更加容易。
拆分過程中也遇到了一些問題,比如是由上向下拆還是由下向上拆。通常的做法是為了避免重覆勞動,肯定是先拆最下層(DB)再逐步拓展到上層。但是泡泡後臺組日常還在不斷迭代新功能的開發(也是我們團隊最重點的工作),愛奇藝移動端統一採用雙周發版後開發同學的時間被嚴重碎片化,導致投入到微服務化的精力和資源都非常有限,整個進度進展較慢。好在老闆們都支援,大家做起來也比較有動力,我們花了比預計長一些的時間,收穫了比較穩定的結果,也算是功德圓滿。
此外還有一個問題,是RPC服務上線初期,由於QPS較大,我們發現系統在運行了一段時間後就會出現不穩定的情況,RPC client請求RPC server拋大量異常導致觸發了熔斷。經過對Client端連線池和Server端記憶體最佳化,修複了Client呼叫失敗及服務端Full GC等導致服務不穩定問題。
做到目前大家對系統的拆分算是比較滿意了,當然後續還有一些欠缺的東西可以慢慢補全,比如呼叫鏈路分析和全鏈路監控(壓測)系統,如過有了這個我們對每一次新功能的迭代和問題的排查都會更加得心應手。此外還有更好地整合各階段測試和監控的CI系統、全域性事務一致性系統、全域性任務統一排程系統等等。相信這些隨著未來我們在演進過程中不斷細化具體的需求點,以及在公司各個內部團隊的大力支援下,都會慢慢實現的。
能夠支援業務在各個階段的成長是第一位的,就好比泡泡平臺從最開始定位的社交(聊天、發帖),到目前的明星、興趣社群和運營推廣,再到未來的不同業務的基礎平臺,每一步的業務成長都是促使我們技術演進的最強動力。此外,也希望我們的團隊不斷成長,鍛煉出我們過得硬的技術,在未來可以應對公司不斷變化的業務挑戰。服務根據業務領域,而不是技術進行建模。
本次培訓內容包括:容器原理、Docker架構及工作原理、Docker網路與儲存方案、Harbor、Kubernetes架構、元件、核心機制、外掛、核心模組、Kubernetes網路與儲存、監控、日誌、二次開發以及實踐經驗等,點選瞭解具體培訓內容。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。