(點選上方公眾號,可快速關註)
來源:笨狐狸,
blog.csdn.net/liweisnake/article/details/68942165
上一章我們瞭解了zookeeper到底是什麼,這一章重點來看zookeeper當初到底面臨什麼問題?而zookeeper又是如何解決這些問題的?
實際上zookeeper主要就是解決分散式環境下的一致性問題。那麼解決這個問題到底有哪些難點呢?我們一步一步來闡述和推理這個過程。
分散式事務
我們首先考慮一致性的特殊情況,即分散式事務的情況。分散式事務對於一致性的要求是強一致性,因此對於我們後續討論有一定的借鑒意義。這裡我們用到一個經典的例子:bob給smith轉賬,強一致性的要求一定是需要對外來說bob減錢的同時smith加錢。見文獻1(圖片也來源於文獻1)
單機環境下是這樣的
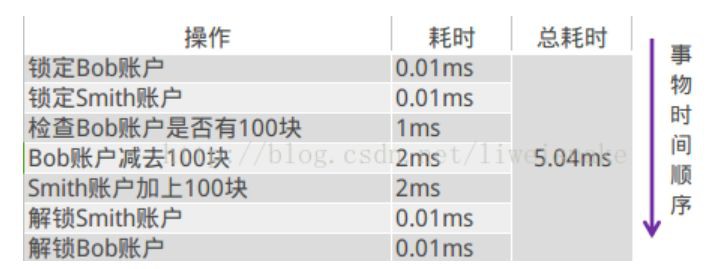
簡單講就是有關bob的減錢和smith的加錢都轉同一個庫來做,可以採用資料庫的事務特性輕鬆支援。保證bob給smith轉賬的安全性。
而分散式環境就變這樣了
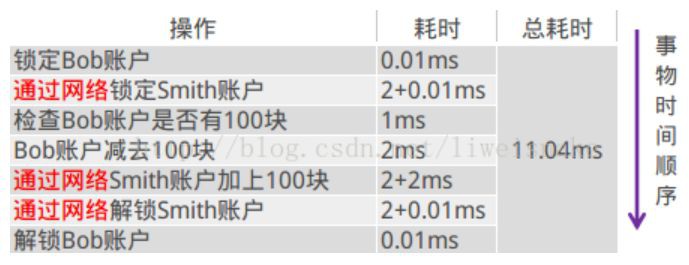
假設應用伺服器是A,bob端的資料庫是B,smith端的資料是C,那麼A做成一個轉賬,需要B事務成功提交,並且C事務成功提交。然而因為網路的影響,可能出現兩種情況
1. 如果bob扣款成功,而網路通知smith失敗了,則會出現bob的錢減了,smith的錢沒加
2. 如果bob扣款不成功,而smith加錢成功了,則會出現smith錢增加了,但是bob的錢也沒減少
2PC
這種不一致的問題困擾著大家。任意一邊出錯想要回滾另一邊都不是簡單的資料庫回滾的事情( 因為此時已經成功提交),而是需要做業務的逆向操作,而不同業務的逆操作都不同,導致複雜性增加。考慮資料庫事務的執行實際上是先將執行操作寫入binlog,等到最後透過一個commit指令將binlog的內容一次更新到表中,或者寫到一半透過一個rollback指令將binlog中的內容回滾。於是乎,可以想到使用2個階段來執行這個過程,第一階段,寫入binlog;第二階段執行commit或者rollback。這就是著名的兩階段提交協議(2PC)。如果仔細考慮,會發現兩階段協議並沒有解決問題,只不過降低了出錯的機率而已,因為第二階段同樣存在上面的兩種情況。註意最終狀態是多臺機器的狀態&&的 結果。以下是兩階段協議的時序圖:
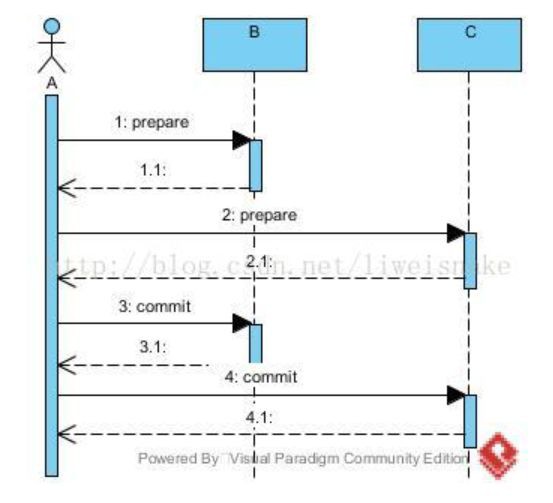
1. 考慮prepare階段的響應(因為請求階段和執行階段都可以在最後響應中體現出來),對於分散式環境中,任意時刻考慮3種狀態:成功、失敗、超時。
a.成功。不必處理,執行後續行為commit。
b.失敗。這是執行階段出錯,執行後續行為rollback。
c.超時。這可能是執行階段太慢,也可能是網路階段太慢或丟包,但是保守處理,超時可以當做出錯。
可以看出,prepare階段的問題能夠完全避免。
2. 考慮commit階段,同樣考慮成功失敗超時3種狀態。
a. 成功。整個事務成功執行
b. 失敗。提交出錯,假設此時前面的B已經提交成功了,則同樣面臨需要回滾B卻無法回滾的問題,因為B已經提交成功了。
c. 超時。同上。
還有一種例外情況,即prepare階段完成後A掛了,則B,C即進入不知所措的狀態。
可以看出,在2PC中事務無法做到像單機一樣安全,只不過降低了出問題的機率。
3PC
針對如何解決2PC中的例外情況,出現了3階段提交協議。3階段的主要改進是把2階段的prepare再分為canCommit和preCommit兩個階段。
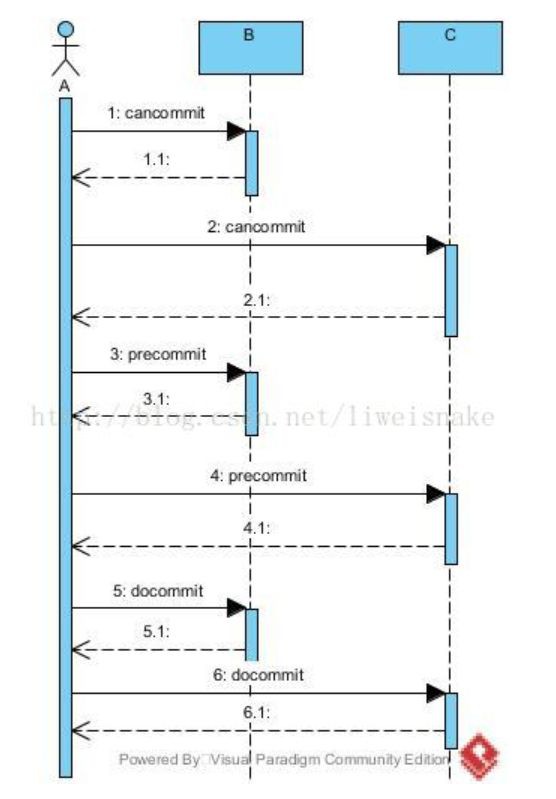
1. 考慮cancommit階段的響應。
a.成功。不必處理,執行後續行為precommit。
b.失敗。說明無法執行,無須後續提交或回滾行為。
c.超時。保守處理,超時可以當做失敗。
2. 考慮precommit階段的響應。
a.成功。不必處理,執行後續行為docommit。
b.失敗。執行階段出錯,執行後續行為rollback。
c.超時。執行階段太慢,也可能是網路階段太慢或丟包,但是保守處理,超時可以當做出錯。
3. 考慮cancommit階段的響應。
a.成功。整個事務成功執行。
b.失敗。提交出錯,假設此時前面的B已經提交成功了,則同樣面臨無法回滾的問題。
c.超時。保守處理,超時可以當做失敗。
例外情況,即自cancommit傳回成功後的任意階段A掛掉了,那麼BC同樣能夠知道這個事務正在發生(因為cancommit已經提交了足夠資訊讓BC知曉此事),於是BC可以在無A的情況下繼續執行後續的階段(比如BC投票啟動新的A’,並提供A’足夠資訊)。於是3PC正好解決了2PC的例外情況。
但是3PC仍然存在類似2PC的問題,即最後階段失敗或超時同樣有可能出現資料不一致的問題。所以3PC仍然只是降低了發生機率,並沒有真正解決問題。
XTS
工業界的對分散式事務的應用是如何呢?可以參考某寶的知名分散式框架XTS。
XTS本質上是2PC(實際上如果引入3PC會多2n次網路互動,在量大時反而更加不安全)。XTS引入協調者A的server部分,實際上是一個大叢集,以配置的方式接入各種需要分散式事務的業務,叢集由專門的團隊維護,保證其可用性和效能;而協調者A的client部分則透過發起方呼叫,prepare階段時,先透過client將本次事務資訊傳送到server,落庫,然後即時推送prepare請求到B和C,當收到B,C的響應時把他們狀態入庫,如果正常,則做commit提交;否則會用定時任務去推送未完成的狀態直到完成。上文提到的prepare之後協調者A掛了這種情況,在server叢集的保證下,幾乎很少會發生。而上文提到的所有超時的情況,都可以透過定時任務推送拿到一個確定的狀態而不是盲目的選擇回滾或者提交。另外由於B和C都是叢集,很少會發生多次請求過去無響應的情況。直到最後一種情況就是commit時B成功了C失敗了,或者反過來B失敗C成功,這種情況成為懸掛事務,最終等待人工來解決,據說每天都有幾筆到幾十筆。
無疑XTS作為2PC在工業界的應用,是相當了不起的設計,透過各種方式規避了各種可能的不一致性,在效能,效率等方面做到了平衡。
TCC(Try/Confirm/Cancel)
業務補償型別,其基本思想是對每一個業務操作做一個逆操作,一旦成功了,就做正向業務,一旦失敗了就做業務的逆操作。通常在業務邏輯簡單並且正逆操作清晰的時候用比較好。
查詢補償
典型的場景是向銀行發送了轉賬請求未得到明確的成功失敗傳回碼,此時先做業務結果的查詢,根據結果做相應處理,比如查詢結果成功,則置狀態為成功,查詢結果失敗,則做相應的業務補償,查詢結果為未知,則繼續查詢。
訊息事務及訊息重試
事務訊息及訊息重試本質上都是將一些通用的事務交給訊息中介軟體,透過訊息中介軟體來保證訊息的最終一致性。
事實上,訊息事務解決了這類問題,即本地事務和訊息應當有一致性,解決這個一致性比較麻煩,比如訊息中介軟體和業務同時實現XA;或者採用一些更加複雜的方式,比如將訊息表與業務表放同庫,利用資料庫的事務來保證一致性,而訊息系統只需要輪訓該訊息表即可;當然,也有訊息的二階段提交+補償的方式。訊息事務解決了訊息發起方,即生產者與訊息中介軟體之間的一致性問題。
try{
//資料庫操作
//訊息投遞
}catch(Exception e){
//回滾
}
訊息中介軟體與消費者之間的一致性問題則需要透過重試+冪等來解決。訊息重試中主要考慮重試次數以及重試時間的閾值變化。
參考
-
分散式開放訊息系統(RocketMQ)的原理與實踐
http://www.jianshu.com/p/453c6e7ff81c
-
訊息中介軟體(一)分散式系統事務一致性解決方案大對比,誰最好使?
http://blog.csdn.net/lovesomnus/article/details/51785108
-
最終一致性
https://zhuanlan.zhihu.com/p/25933039
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

