(點選上方公眾號,可快速關註)
英文:Gojko Adzic,翻譯:伯樂線上 – 精算狗
http://blog.jobbole.com/113609/

2017年11月 BBC 報道了一個假冒 WhatsApp 的新聞。假應用似乎與官方應用屬於同一個開發者名下。原來這些騙子透過在開發者名字中加入 Unicode 的非列印空格(nonprintable space),繞開驗證。在 Google Play 維護人員發現之前,下載假應用超過 100 萬人。
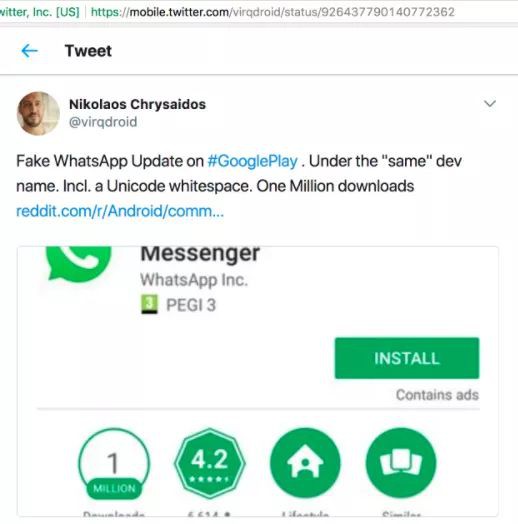
Unicode 是極其有價值的標準,使得電腦、智慧手機和手錶,在全球範圍內以同樣的方式顯示同樣的訊息。不幸的是,它的複雜性使其成為了騙子和惡作劇者的金礦。如果像 Google 這樣的巨頭都不能抵禦 Unicode 造成的基本問題,那對小一點的公司來說,這可能就像是必輸的戰役了。然而,大多數這些問題都是圍繞著幾個漏洞利用的。以下是關於 Unicode 所有開發者都應該知道的前五件事,並用來防止欺詐。
1. 很多 Unicode 程式碼點是不可見的
Unicode 中有一些零寬度程式碼點,例如零寬度聯結器(U+200D)和零寬度非聯結器(U+200C),它們都暗示了連字元工具。零寬度程式碼點對螢幕顯示沒有可見的影響,但是它們仍會影響字串比較。這也是假 WhatApp 應用的騙子能這麼長時間不被髮現的原因。這些字元大多數都在一般標點符號區(從 U+2000 到 U+206F)。一般來說,沒有理由允許任何人在識別符號中使用這個區的程式碼點,所以它們是最不易過濾的。但是該區域外也有部分其他不可見的特別程式碼,比如蒙古文母音分隔符(U+180E)。
一般來說,用 Unicode 對唯一性約束做簡單的字串比較,這很危險的。有一個可能的解決方法,限制允許用作識別符號及其他任何能被騙子濫用的資料的字符集。不幸的是,這並非該問題的徹底解決方法。
2. 很多程式碼點看起來很相似
Unicode 努力改寫全世界書寫語言中的所有符號,必然有很多看起來相似的字元。人類甚至無法把它們區分開來,但是電腦能毫不費力地識別出差別。對這個問題的一種令人驚訝的濫用是擬態(Mimic)。擬態是一項有趣的應用,將軟體開發所使用的常見符號,例如冒號和分號,替換成相似的 Unicode 字元。這能在程式碼編譯工具中製造混亂,留下一臉懵逼的開發者。

相似符號帶來的問題,遠不止是簡單的惡作劇。花哨的叫法是 homomorphic attacks(同態攻擊)。利用這些漏洞,會導致嚴重的安全問題。在 2017 年 4 月,一位安全研究員透過混合不同字符集中的字母,成功地註冊了一個看起來與 apple.com 非常相似的域名,甚至為它拿到了 SSL 證書。各大瀏覽器都愉快地顯示了 SSL 掛鎖,將該域名列為安全域名。
與混合可見字元和不可見字元相似,沒有道理允許識別符號,尤其是域名,使用混合字符集名。大多數瀏覽器已經採取了行動,將混合字符集域名顯示為十六進位制的 unicode 值以對其進行處罰,這樣使用者就不會輕易地被迷惑。如果你向用戶顯示識別符號,比如說在搜尋結果中,考慮類似的方法來避免混淆。但是,這也不是完美的解決方法。某些域名可以輕易地用一個非拉丁字符集中的單單一個區來構建,比如 ap.com 或者 chase.com。
Unicode 協會出版了一張易混淆字元表,可能作為自動檢查潛在詐騙的好參考。另一方面,如果你想找一個快速創造疑惑的方法,看看 Shapecatcher 吧。它是一個奇妙工具,列舉了視覺上像圖畫的 Unicode 符號。
3. 規範化並不那麼規範
規範化對像使用者名稱這樣的識別符號來說非常重要,幫助人們用不同的方法輸入值,但是用一致的方法來處理。規範識別符號的一個常見方法是把所有字元都轉變成小寫,確保 JamesBond 和 jamesbond 是一樣的。
因為有如此多的相似字元和交叉集,不同的語言或者 unicode 處理庫,可能應用不同的規範化策略。如果在若干地方進行了規範化,會潛在地帶來安全風險。簡單來說,不要假設小寫轉換在應用軟體中的不同部分是一樣的。來自 Spotify 的 Mikael Goldmann 在他們的一名使用者發現了一個盜用賬戶的方法後,於 2013 年針對這個問題寫了一份事件分析。攻擊者可以註冊其他人使用者名稱的變體,比如 BIGBIRD,會轉換成標準的賬戶名 bigbird。該應用軟體的不同層對單詞的規範化不同,使得人們能夠註冊模仿賬號,而重置標的賬戶的密碼。
4. 螢幕顯示長度和記憶體大小無關
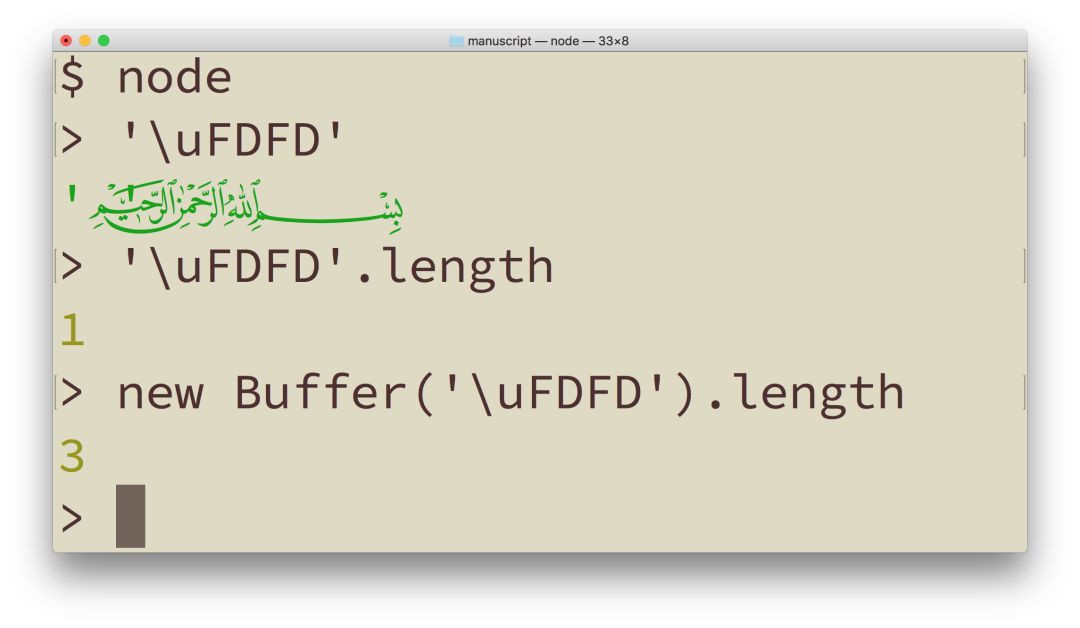
使用基礎拉丁字符集和大多數歐洲字符集時,一段文字在螢幕或者紙上所佔的空間大致與符號數成比例,大致與文字的記憶體大小成比例。這也是 EM 和 EN 成為流行長度單位的原因。但使用 Unicode 時,像這樣任何種類的假設都會變得危險。有像 Bismallah Ar-Rahman Ar-Raheem (U+FDFD)這樣可愛的字元,單單一個字元就比大多數英文單詞都要長,能夠輕易地超過網頁上假定的視覺外框。這意味著基於字串字元長度的任何種類的自動換行,或者文字中斷演演算法都能輕易被愚弄。大多數終端程式要求固定寬度的字型,所以在這些程式中顯示的話,你會看到右引號完全標在了錯誤的位置上。
該問題一種濫用是 zalgo 文字生成器,它在一段文本週圍加上垃圾,讓這些東西佔據了更多的垂直空間。
當然了,整個不可見程式碼點的問題導致螢幕長度和記憶體大小無關。所以與輸入區恰好合適的東西可能長到能摧毀一個資料庫區。過濾不可見字元來規避問題還不夠,因為還有很多不佔用它們自己空間的其他例子。
混合佔據前一個字母上的空間的拉丁字元(比如 U+036B 和 U+036C),這樣你能在一行文字行中寫多行文字(Nu036BOu036C 產生 NͫOͬ)。吟誦標記是用來示意吟唱希伯來聖經經文的語調的。這些吟誦標記能夠在同樣的視覺空間中無限堆疊,意味著他們能被輕易地濫用,將大量資訊編寫進螢幕上的一個字元空間。Martin Kleppe 用吟誦標記為瀏覽器編碼了 Conway’s Game of Life 的實現。看看該頁面的原始碼吧,你會感到震驚的。
5. Unicode 遠不止是被動資料
有些程式碼點是用來影響輸出字元的顯示方式的,意味著使用者不僅可以複製貼上資料,也能鍵入處理指令。一個常見惡作劇是,使用右到左改寫(U+202E)來轉變文字方向。例如,用谷歌地圖搜尋 Ninjas。該查詢字串實際上轉換了搜尋單詞的方向,儘管頁面上的搜尋區域顯示著“ninjas”,但是實際上搜索的是“sajnin”。
這種漏洞利用非常流行,XKCD 漫畫網站上有一張相應漫畫。

混合資料和處理指令——可有效執行的程式碼——不是個好主意,尤其是如果使用者可以直接鍵入。這對任何在頁面顯示中包括的使用者鍵入來說都是大問題。大多數網頁開發者知道透過移除 HTML 標簽來清理使用者鍵入,但是也需要註意鍵入中的 Unicode 控制字元。這是個應對任何髒話或者內容過濾器的簡單方法——只要把單詞倒轉過來,在開始加上右到左改寫。
右到左(Right-to-left)hack 可能無法嵌入惡意程式碼,但是如果你不小心的話,它能擾亂內容或者翻轉整個頁面。抵禦這個問題,常見方法是把使用者提供的內容放進一個輸入區域或者文字區域,這樣處理指令不會影響頁面。
處理指令對顯示的另一個特別問題是字型變換選取器。為了避免為每種顏色的 emoji 創造單獨的程式碼,Unicode 允許使用字型變換選取器來混合基本符號和顏色。白旗,字型變換選取器和彩虹正常會產生彩虹顏色的旗。但是並不是所有變換都可行。在 2017 年 1 月,iOS unicode 處理中的一個 bug 允許惡作劇者,僅僅傳送一條特製資訊就遠端導致 iPhone 癱瘓。該資訊包括白旗,字型變換選取器和一個零。iOS CoreText 陷入了恐慌樣式,想要挑出正確的變換,導致了 OS 的癱瘓。這個惡作劇在直接資訊,群聊甚至分享聯絡人名片中都奏效。這個問題也影響了 iPad,甚至部分 MacBook。該惡作劇針對的標的人群,面對系統崩潰,無能為力。
相似的 bug 每幾年就發生一次。在 2013 年,出現了一個阿拉伯字元處理 bug,它能使 OSX 和 iOS 崩潰。所有這些 bug 都深深埋藏在 OS 文字處理模組裡,所以典型客戶端應用開發者根本無法躲開它們。
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功

