(點選上方公眾號,可快速關註)
來源:笨狐狸 ,
blog.csdn.net/liweisnake/article/details/70045164
上一章討論了paxos演演算法,把paxos推到一個很高的位置。但是,paxos有沒有什麼問題呢?實際上,paxos還是有其自身的缺點的:
1. 活鎖問題。在base-paxos演演算法中,不存在leader這樣的角色,於是存在這樣一種情況,即P1提交了一個proposal n1並且透過了prepare階段;此時P2提交了一個proposal n2(n2>n1)並且也透過了prepare階段;P1在commit時因為已經透過了n2而被拒絕;於是P1繼續提交一個proposal n3並且透過prepare階段;巧的是此時P2開始commit了,由於n2
2. 複雜度問題。base-paxos協議中還存在這樣那樣的問題,於是各種變種paxos出現了,比如為瞭解決活鎖問題,出現了multi-paxos;為瞭解決通訊次數較多的問題,出現了fast-paxos;為了儘量減少衝突,出現了epaxos。可以看到,工業級實現需要考慮更多的方面,諸如效能,異常等等。這也是為啥許多分散式的一致性框架並非真正基於paxos來實現的原因。
3. 全序問題。對於paxos演演算法來說,不能保證兩次提交最終的順序,而zookeeper需要做到這點,可以參考文獻1。
For high-performance, it is important that
ZooKeeper can handle multiple outstanding state changes requested by the client and
that a prefix of operations submitted concurrently are committed according to FIFO
order.
基於以上這些原因,zookeeper並沒有用paxos作為自己實現的協議,取而代之採用了一種稱為zab的協議,全稱是zookeeper atomic broadcast。下麵簡單介紹一下zab協議。
上面說過了,paxos存在活鎖問題,為瞭解決活鎖問題,zab引入了leader,但是單leader就是赤裸裸的單點問題,如何解決這個單點呢?
paxos採用的方法是leader選舉(沒有採用主備,因為主備過於固定,不夠分散式)。leader選舉就必然出現狀態不一致的情況,於是就有著同步這樣的過程。
zab協議分為4個階段,即階段0為leader選舉,階段1為發現,階段2為同步,階段3為廣播。而實際實現時將發現及同步階段合併為一個恢復階段。
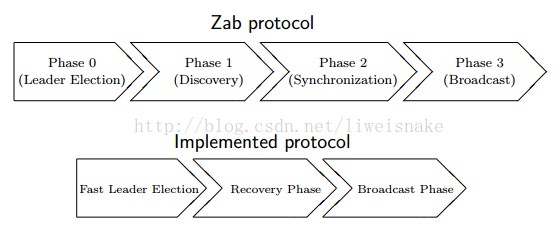
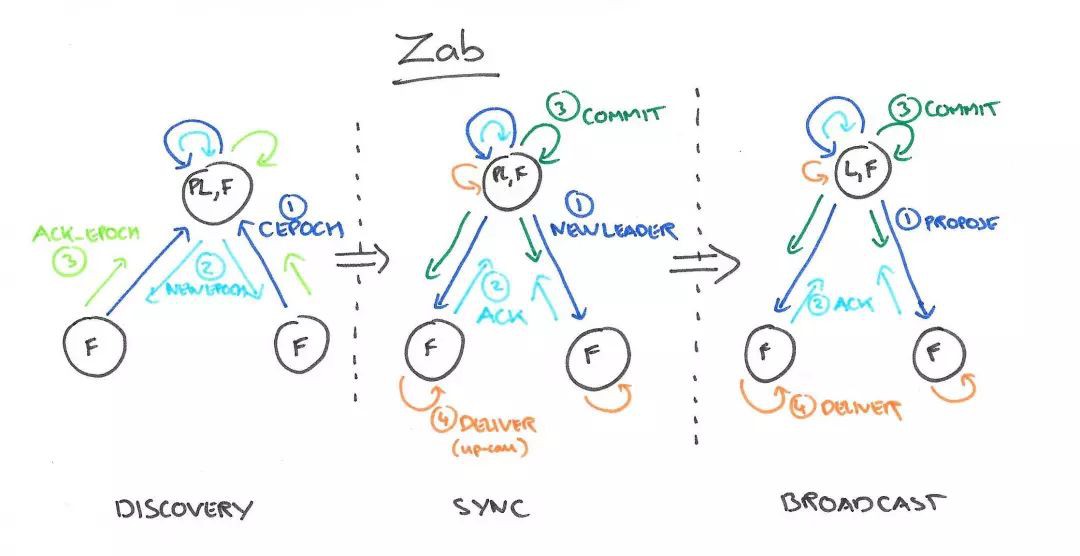
0. leader選舉階段。當叢集中沒有leader或者其他人感受不到leader時會進入這一階段,這一階段的主要目的是選出zxid最大的節點作為準leader。
1. recovery階段。本階段的主要目的是根據準leader的情況將資料同步到其他節點。同步完成後準leader變為leader。
2. broadcast階段。本階段的主要目的是leader收到請求,並將請求轉為proposal,其他節點根據協議進行批准或透過。broadcast階段事實上就是一個兩階段提交的簡化版。其所有過程都跟兩階段提交一致,唯一不一致的是不能做事務的回滾。
廣播的過程實際上類似於二階段提交,但是如果實現完整的兩階段提交,那就解決了一致性問題,沒必要發明新協議了,所以zab實際上拋棄了兩階段提交的事務回滾,於是一臺follower只能回覆ACK或者乾脆就不回覆了,leader只要收到過半的機器回覆即透過proposal。但是這樣的設計就存在很多問題,比如如果一個follower因為網路問題從頭到尾一直沒收到過leader的proposal,後續的詢問剛好落到這臺follower上該如何處理?比如leader第一階段收到了所有follower的ACK後提交,然後通知其他follower提交,這時自己掛了該如何處理?於是誕生了崩潰恢復階段,旨在對各種不一致情況做出恢復和處理。
對於選舉和恢復階段。zab演演算法需要確保兩件事。
1. 已經處理過的proposal不能被丟棄。
發生場景:leader發送了proposal,follower1和follower2回覆了ACK給leader,leader向所有follower傳送commit請求並commit自身,此時leader掛了。leader已經提交,但是follower尚未提交,這會存在不一致的情況。
確保方式:
a. 重新選舉leader時只挑選zxid最大的follower。因為至少半數的follower曾今回覆ACK,意味著重新選舉時zxid最大的follower應該是當初回覆ACK但尚未提交的其中一臺。
b. 該follower即準leader,將自身收到prepare但尚未提交的proposal提交
c. 在選舉階段準leader已經能拿到其餘follower的所有事務集合,於是準leader根據各個follower的事務執行情況,分別建立佇列,先傳送prepare請求,再傳送commit請求,讓所有follower都同步到與leader一樣的狀態。
透過以上方式,能夠確保提交過的proposal不會出現丟棄的情況。
2. 已經丟棄的proposal不能被重覆處理。
發生場景:leader收到請求,包裝為proposal,此時網路掛了或者leader掛了導致其他follower沒收到請求,此時進入崩潰恢復階段,此時其他follower選主併成功之後這個掛了 的leader以follower的身份加入,此時它有一個多餘的proposal,與其他節點不一致。
確保方式:
透過zxid的大小能夠直接確定。zxid的編碼方式為高32位為epoch(即紀元,可以理解為代),低32位為每個proposal順序遞增的數字。每次變換一個leader,則epoch加一,可以理解為改朝換代了,這樣,新朝代的zxid必然比舊朝代的zxid大,新代的leader可以要求將舊朝代的proposal清除。
可以考慮一下,如果leader在崩潰恢復階段就滿血複活了,此時叢集的情況是什麼樣的。
參考
-
ZooKeeper’s atomic broadcast protocol:Theory and practice http://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf
-
Zab:Zookeeper 中的分散式一致性協議介紹 http://www.jianshu.com/p/fb527a64deee
-
Zookeeper ZAB 協議分析 http://blog.xiaohansong.com/2016/08/25/zab/
-
Zab協議 http://www.cnblogs.com/sunddenly/articles/4073157.html
-
ZAB協議和Paxos演演算法 http://codingo.xyz/index.php/2016/12/27/zab_paxos/
-
ZooKeeper之ZAB協議 http://www.solinx.co/archives/435
-
Zab vs. Paxos https://cwiki.apache.org/confluence/display/ZooKeeper/Zab+vs.+Paxos
-
ZooKeeper學習第七期–ZooKeeper一致性原理 http://www.cnblogs.com/sunddenly/p/4138580.html
-
分散式系統理論進階 – Raft、Zab http://www.cnblogs.com/bangerlee/p/5991417.html
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

