小編邀請您,先思考:
1 關聯演演算法有什麼應用?
2 關聯演演算法如何實現?
溫馨提示:加入圈子或者商務合作,請加微信:luqin360
關聯規則挖掘是一種基於規則的機器學習演演算法,該演演算法可以在大資料庫中發現感興趣的關係。它的目的是利用一些度量指標來分辨資料庫中存在的強規則。也即是說關聯規則挖掘是用於知識發現,而非預測,所以是屬於無監督的機器學習方法。

“尿布與啤酒”是一個典型的關聯規則挖掘的例子,沃爾瑪為了能夠準確瞭解顧客在其門店的購買習慣,對其顧客的購物行為進行購物籃分析,想知道顧客經常一起購買的商品有哪些。沃爾瑪利用所有使用者的歷史購物資訊來進行挖掘分析,一個意外的發現是:”跟尿布一起購買最多的商品竟是啤酒!
關聯規則挖掘演演算法不僅被應用於購物籃分析,還被廣泛的應用於網頁瀏覽偏好挖掘,入侵檢測,連續生產和生物資訊學領域。
與序列挖掘演演算法不同的是,傳統的關聯規則挖掘演演算法通常不考慮事務內或者事件之間的順序。
支援度和置信度
那麼我們如何能夠從所有可能規則的集合中選擇感興趣的規則呢?需要利用一些度量方法來篩選和過濾,比較有名的度量方法是最小支援度(minimum support)和最小置信度(minimum confidence)。
假定我們一個資料庫包含5條事務,每行表示一個購物記錄,1 表示購買,0 表示沒有購買,如下圖表格所示:
ID | milk | bread | butter | beer | diapers
—-|——|——|——|—-
1 | 1| 1 | 0 | 0 | 0
2| 0| 0| 1| 0| 0
3| 0| 0| 0| 1| 1
4| 1| 1| 1| 0| 0
5| 0| 1| 0| 0| 0
讓 X,Y 各表示為一個 item-set, X ⇒ Y 表示為一條規則(尿布 ⇒ 啤酒 就是一條規則),用 T 表示為事務資料庫(並不是說只侷限於事務資料庫)。
支援度(Support)
支援度表示 item-set 在整個 T 中出現的頻率。假定 T 中含有 N 條資料,那麼支援度的計算公式為:

譬如在上面的示例資料庫中,{beer, diaper} 的支援度為 1/5 = 0.2。5 條事務中只有一條事務同事包含 beer和 diaper ,實際使用中我們會設定一個最低的支援度(minimum support),那些大於或等於最低支援度的 X 稱之為頻繁的 item-set 。
置信度(Confidence)
置信度表示為規則 X ⇒ Y 在整個 T 中出現的頻率。而置信度的值表示的意思是在包含了 X 的條件下,還含有 Y 的事務佔總事務的比例。同樣假定 T 中含有 N 條資料,那麼置信度的計算公式為:

譬如再上面的示例資料庫中,{beer, diaper} 的置信度為 0.2/0.2 = 1。錶面在所有包含 beer 的事務中都會一定包含 diaper。同樣的,在實際使用中我們會設定一個最低置信度,那些大於或等於最小置信度的規則我們稱之為是有意義的規則。
相關性度量
有時候使用支援度和置信度挖掘到的規則可能是無效的。
舉個例子:
10000 個事務中, 6000 個事務包含計算機遊戲, 7500 個包含遊戲機遊戲, 4000 個事務同時包含兩者。關聯規則(計算機遊戲 ⇒ 遊戲機遊戲) 支援度為 0.4 ,看似很高,但其實這個關聯規則是一個誤導。在使用者購買了計算機遊戲後有 (4000÷6000) = 0.667 的機率的去購買遊戲機遊戲,而在沒有任何前提條件時,使用者反而有 (7500÷10000) = 0.75的機率去購買遊戲機遊戲,也就是說設定了購買計算機遊戲這樣的前置條件反而會降低使用者去購買遊戲機遊戲的機率,所以計算機遊戲和遊戲機遊戲是相斥的,也即表明是獨立的。
因此我們可以透過下麵的一些相關性度量方法來篩選挖掘到的規則。
提升度(Lift)
提升度可以用來判斷規則 X ⇒ Y 中的 X 和 Y 是否獨立,如果獨立,那麼這個規則是無效的。
計算提升度的公式如下:

如果該值等於 1 ,說明兩個條件沒有任何關聯。如果小於 1 ,說明 X 與 Y 是負相關的關係,意味著一個出現可能導致另外一個不出現。大於 1 才表示具有正相關的關係。一般在資料挖掘中當提升度大於 3 時,我們才承認挖掘出的關聯規則是有價值的。
他可以用來評估一個出現提升另外一個出現的程度。
提升度是一種比較簡單的判斷手法,實際中受零事務(也即不包含 X 也不包含 Y 的事務)的影響比較大。所以如果資料中含有的零事務數量較大,該度量則不合適使用。
全置信度 和 最大置信度
給定兩個項集 X 和 Y ,其全置信度為

不難知道,最大置信度為

全置信度和最大置信度的取值都是從 0 ~ 1 ,值越大,聯絡越大。
該度量是不受零事務影響的。
KULC 度量 + 不平衡比(IR)
給定兩個項集 X 和 Y,其 Kulczynski(Kulc) 度量定義為:

可以看做是兩個置信度的平均值,同樣取值也是從 0 ~ 1,值越大,聯絡越大,關係越大。
該度量同樣也是不受零事務影響的。
Apriori 演演算法
在執行演演算法之前,使用者需要先給定最小的支援度和最小的置信度。
生成關聯規則一般被劃分為如下兩個步驟:
1、利用最小支援度從資料庫中找到頻繁項集。
給定一個資料庫 D ,尋找頻繁項集流程如下圖所示
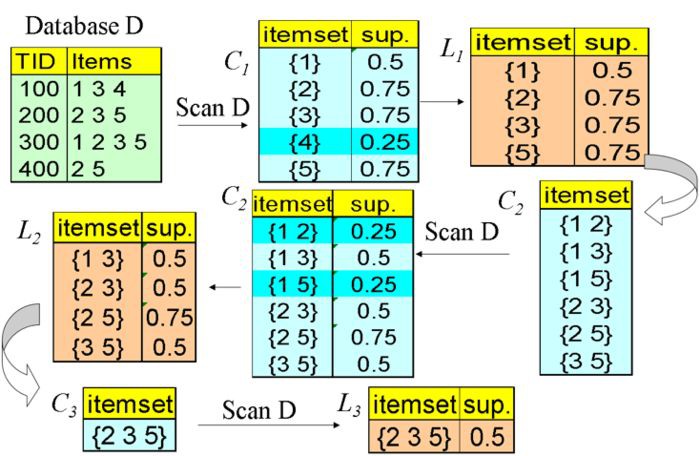
頻繁項集的流程示意圖
C1 中 {1} 的支援度為 2/4 = 0.5 表示在 D 中的 4 條事務中,{1} 出現在其中的兩條事務中,以後幾個步驟的支援度計算方式也是類似的。假定給定的最小支援度為 0.5,那麼最後我們可以得到一個包含 3 個項的頻繁項集 {2 3 5}。
另外,從圖中我們可以看到 itemset 中所包含的 item 是從 1 增長到 3 的。並且每次增長都是利用上一個 itemset 中滿足支援度的 item 來生成的,這個過程稱之為候選集生成(candidate generation)。譬如說 C2 裡就不包含 C1 中的 4 。
2、利用最小置信度從頻繁項集中找到關聯規則。
同樣假定最小的置信度為 0.5 ,從頻繁項集 {2 3 5} 中我們可以發現規則 {2 3} ⇒ {5} 的置信度為 1 > 0.5 ,所以我們可以說 {2 3} ⇒ {5} 是一個可能感興趣的規則。
從第一步中我們看出每次計算支援度都需要掃描資料庫,這會造成很大的 I/O 開銷,所以有很多變種的演演算法都會在該問題上進行最佳化(FP-Growth)。此外如何有效的生成候選集也是很多變種演演算法最佳化的問題之一(Apriori-all)。
總結
-
關聯規則是無監督的學習演演算法,能夠很好的用於知識的發現。
-
缺點是很難嚴重演演算法的有效性,一般只能夠透過肉眼觀察結果是否合理。
參考資料
-
Association Rule Learning
-
Data mining: Concepts and Technique
-
Fast Algorithm For Mining Association Rule (Apriori-all 演演算法)
-
Mining frequent patterns without candidate generation: a frequent-pattern tree approach (FP-Growth演演算法)
連結:https://www.jianshu.com/p/7d459ace31ab
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
