作者丨崔權
學校丨早稻田大學碩士生
研究方向丨深度學習,計算機視覺
知乎專欄丨サイ桑的煉丹爐
前言
最近讀了 Xception [1] 和 DeepLab V3+ [2] 的論文,覺得有必要總結一下這個網路裡用到的思想,學習的過程不能只是一個學習網路結構這麼簡單的過程,網路設計背後的思想其實是最重要的但是也是最容易被忽略的一點。
Xception (Extreme Inception)
摺積層的學習方式
在一層摺積中我們嘗試訓練的是一個 3-D 的 kernel,kernel 有兩個 spatial dimension,H 和 W,一個 channel dimension,也就是 C。
這樣一來,一個 kernel 就需要同時學習 spatial correlations 和 cross-channel correlations,我把這裡理解為,spatial correlations 學習的是某個特徵在空間中的分佈,cross-channel correlations 學習的是這些不同特徵的組合方式。
Inception的理念
首先透過一系列的 1×1 摺積來學習 cross-channel correlations,同時將輸入的維度降下來;再透過常規的 3×3 和 5×5 摺積來學習 spatial correlations。這樣一來,兩個摺積模組分工明確。Inception V3 中的 module 如下圖。

Inception的假設
corss-channels correlations 和 spatial correlations 是分開學習的,而不是在某一個操作中共同學習的。
Inception到Xception的轉變
首先考慮一個簡版的 Inception module,拿掉所有的 pooling,並且只用一層 3×3 的摺積來提取 spatial correlations,如 Figure2。
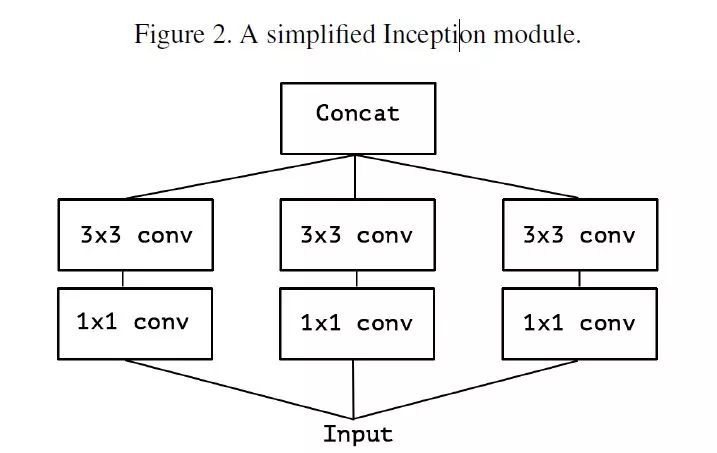
▲ 簡版Inception
可以將這些 1×1 的摺積用一個較大的 1×1 摺積來替代(也就是在 channel 上進行 triple),再在這個較大卷積產生的 feature map 上分出三個不重疊的部分,進行 separable convolution,如 Figure3。

這樣一來就自然而然地引出:為什麼不是分出多個不重疊的部分,而是分出三個部分來進行 separable convolution 呢?如果加強一下 Inception 的假設,假設 cross-channel correlations 和 spatial correlations 是完全無關的呢?
沿著上面的思路,一種極端的情況就是,在每個 channel 上進行 separable convolution,假設 1×1 摺積輸出的 feature map 的 channel 有 128 個,那麼極端版本的 Inception 就是在每個 channel 上進行 3×3 的摺積,而不是學習一個 3x3x128 的 kernel,取而代之的是學習 128 個 3×3 的kernel。
將 spatial correlations 的學習細化到每一個 channel,完全假設 spatial correlations 的學習與 cross-channel correlations 的學習無關,如 Figure4 所示。

Xception Architecture
一種 Xception module 的線性堆疊,並且使用了 residual connection,資料依次流過 Entry flow,Middle flow 和 Exit flow。
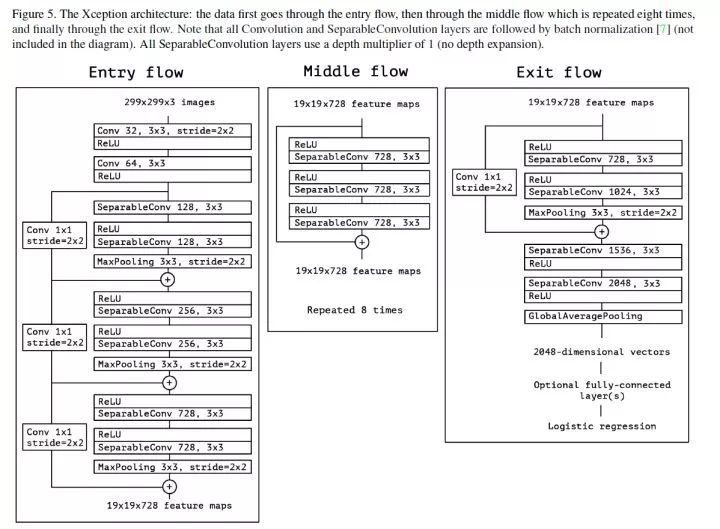
順便寫一點讀 Xception 時的小發現,Xception 的實驗有一部分是關於應不應該在 1×1 摺積後面只用啟用層的討論,實驗結果是:如果在 1×1 摺積後不加以啟用直接進行 depthwise separable convolution,無論是在收斂速度還是效果上都優於在 1×1 摺積後加以 ReLU 之類啟用函式的做法。
這可能是因為,在對很淺的 feature(比如這裡的 1-channel feature)進行啟用會導致一定的資訊損失,而對很深的 feature,比如 Inception module 提取出來的特徵,進行啟用是有益於特徵的學習的,個人理解是這一部分特徵中有大量冗餘資訊。
DeepLab V3+
論文裡,作者直言不諱該框架參考了 spatial pyramid pooling (SPP) module 和 encoder-decoder 兩種形式的分割框架。前一種就是 PSPNet 那一款,後一種更像是 SegNet 的做法。
ASPP 方法的優點是該種結構可以提取比較 dense 的特徵,因為參考了不同尺度的 feature,並且 atrous convolution 的使用加強了提取 dense 特徵的能力。但是在該種方法中由於 pooling 和有 stride 的 conv 的存在,使得分割標的的邊界資訊丟失嚴重。
Encoder-Decoder 方法的 decoder 中就可以起到修複尖銳物體邊界的作用。
關於Encoder中摺積的改進
DeepLab V3+ 效仿了 Xception 中使用的 depthwise separable convolution,在 DeepLab V3 的結構中使用了 atrous depthwise separable convolution,降低了計算量的同時保持了相同(或更好)的效果。
Decoder的設計
Encoder 提取出的特徵首先被 x4 上取樣,稱之為 F1;
Encoder 中提取出來的與 F1 同尺度的特徵 F2′ 先進行 1×1 摺積,降低通道數得到 F2,再進行 F1 和 F2 的 concatenation,得到 F3;
為什麼要進行通道降維?因為在 encoder 中這些尺度的特徵通常通道數有 256 或者 512 個,而 encoder 最後提取出來的特徵通道數沒有這麼多,如果不進行降維就進行 concate 的話,無形之中加大了 F2′ 的權重,加大了網路的訓練難度。
對 F3 進行常規的 3×3 convolution 微調特徵,最後直接 x4 upsample 得到分割結果。

還有值得關註的一點是,論文提出了 Xception 的改良版,可以用來做分割:

與 Xception 不同的幾點是:
-
層數變深了
-
所有的最大池化都被替換成了 3×3 with stride 2 的 separable convolution
-
在每個 3×3 depthwise separable convolution 的後面加了 BN 和 ReLU
作者也把 Xception 當作了 Encoder,沒有使用 DeepLab V3 中的 multi-grid 方法,得到的效果是所有模型中最好的。
在 PASCAL VOC 2012 驗證集上的表現:

在 PASCAL VOC 2012 測試集上的表現:

一點總結
縱觀語意分割的模型發展,從最初的 Encoder-Decoder 框架,到後來的 DeepLab、PSPNet 框架,到去年的 RefineNet 框架,每個框架都有其獨到之處,但是 DeepLab V3+ 綜合了 DeepLab、PSPNet 和 Encoder-Decoder,得到的效果是最好的,是思想的集大成者,或許在 RefineNet 類的框架和其他的框架之間也有可以探尋的結構。
相關連結
[1] Xception: Deep Learning with Depthwise Separable Convolutions
https://www.paperweekly.site/papers/1460
https://github.com/kwotsin/TensorFlow-Xception
[2] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
https://www.paperweekly.site/papers/1676
https://github.com/tensorflow/models/tree/master/research/deeplab

點選以下標題檢視相關內容:

 #榜 單 公 布 #
#榜 單 公 布 #
2017年度最值得讀的AI論文 | NLP篇 · 評選結果公佈
2017年度最值得讀的AI論文 | CV篇 · 評選結果公佈
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot02)進行諮詢
長按識別二維碼,使用小程式
賬號註冊 paperweek.ly
paperweek.ly

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 訪問作者知乎專欄