
導語:視覺化不只是畫畫那麼簡單,它或許是我們理解神經網路的世界的方法。PS:標題是作者說的,不是我說的,要打,就打他(逃
昨天,Google Brain 推了一篇十分有趣的 paper ——《The building blocks of interpretability》(中譯:畫出黑盒子裡的風景)。本文在此簡單介紹一下這篇有趣的 paper ,以及人們在“開箱”過程中做出的努力,為什麼我們迫切需要把深度學習的黑箱拆開,這個工作有怎樣的應用?

01 鬼畜的視覺化——萬裡長徵第一步
被論文嚇跑準備左上角的別動!論文無非就是說了:
“我終於知道我訓練出來的神經元它是乾啥的,怎麼乾的”
ヾ(。`Д´。)我擦,乾凈利落!
大家知道機器學習是喂資料,然後吐答案,中間是我們的模型。整個過程就是將我們需要的特徵 (feature) 匯入模型(比如我們用房子面積、房子離市中心的距離等,來得到一個房價)。
然而在影象識別裡,比如說你要識別一隻貓,按照傳統機器學習的思路就是把貓耳朵貓腦袋貓肚子貓毛毛貓的特徵等一堆東西給全部做出來——這特麼不累死你?機器學習的本意並非如此的【機械化運動】,而摺積神經網路正好可以自動抓。於是乎貓耳朵貓腦袋貓啥啥就全部的不用做了——然後丟進模型中訓練走起就好了。然而問題就是,
我用摺積神經網路提出來的特徵究竟是個什麼鬼?
在大名鼎鼎的 CS231n 中,Justin Johnson 將模型得到的權重矩陣的行向量視覺化,得到了一串很鬼畜的圖片。這特麼什麼鬼?在不遠的過去,就有大佬對每個神經元進行視覺化,希望得到究竟是哪些輸入讓這些神經元得到相對較高的響應。(所謂的啟用函式不就是這樣的一個篩選響應的東西嗎?)[2][3]

但是結果第一層是長這樣的(這啥玩意?):

第一層神經網路
第二層是長這樣的(這不是高中的時候觀察的洋蔥上表皮細胞的排列嗎?):

感覺還是不大對勁,我們看第四層好了,哎呀挺好看的——可是為什麼長這樣!!

02 神級的視覺化:.讓你聽懂神級網路做決定的原因
然而論文的工作就很厲害了,它是怎麼做的呢?它們將神經元組合起來,得到一個雖然這個影象猙獰,但是我還是可以勉強看得懂你是個啥玩意的結果。
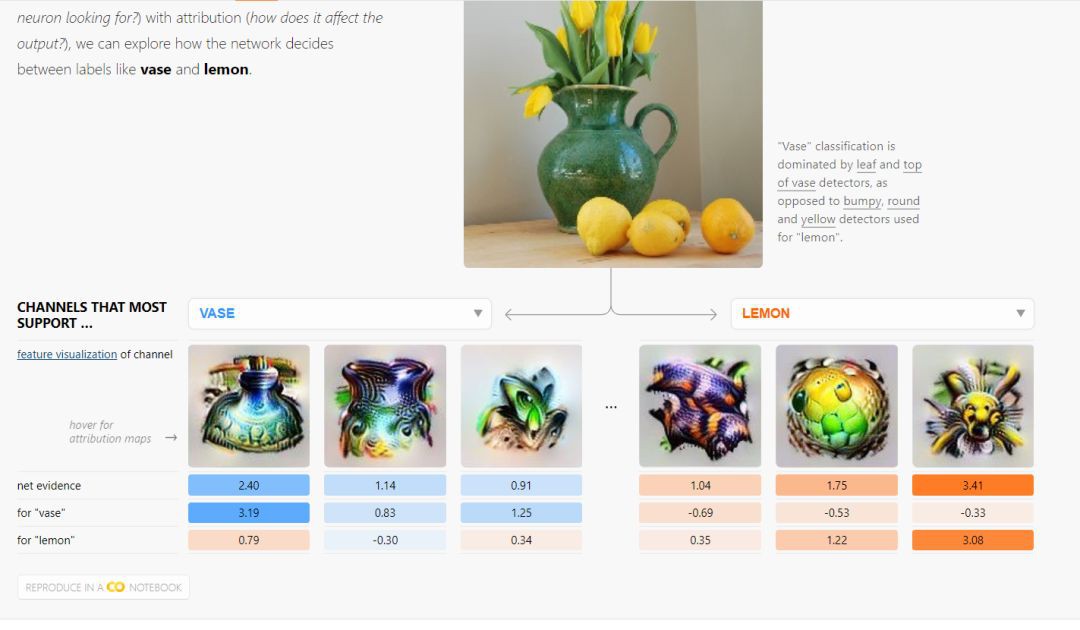
論文給出了摺積神經網路提取出來的人能看得懂的特徵(與之相對的是上面宛如洋蔥表皮細胞的視覺化),就相當於我們在之前提到的手工提出花瓶是個啥特徵(比如圓圓的,肚子胖胖的等等),哎呀這個你看,我們透過得到的花瓶的幾個特徵裡,最像花瓶的可不是那一個嗎?而那一個特徵,還真的是置信機率最高的。

更有意思的是你會發現其所甄別的特徵對應的位置。哎呀這下不就懂了嗎?
03 兩種解釋
這種可解釋性與丘成桐先生的工作不同[4],幾何大佬丘成桐先生試圖找到一個幾何學觀點下的對 GAN 的解釋,將成果以及凸幾何類比[5]。認為 Discriminator 就是 WGAN 中判別器中計算 Wasserstein 距離,而 Generator 用來計算 Brenier 勢能。認為 Brenier 勢能可以用計算Wasserstein 距離來得到[6]。
而這個東西在低維下是根本不需要一個 GANs 的過程的(即 Generator VS Discriminator 得 Nash 均衡),是有一個解析解的。所以說丘成桐先生不一般,他們的想法是透過最優傳輸理論及其各種降維近似,直接取代神經網路,從而使得黑箱透明。
以上的解釋是你別來了,我用一堆東西來 Duang 的一下做的比你更好了,整個過程——嚴謹數學證明。然而我們不能指望現階段這樣的工作一個個爆發然後瘋狂運用,這是不現實。

丘成桐:獲得了數學界的諾貝爾獎(菲爾茨獎)的丘成桐先生是對近代拓撲學、代數幾何學等做出了巨大的貢獻的人。
04 演演算法權力
Google 的論文所提供的是一個權力——解釋權[7]。即解釋演演算法輸出的權力,這種權利主要是指個人權利——可以解釋為對個人有重大影響的決定,尤其是法律上或財務上。例如,你說我想上清華,然後清華拒絕了你。你有權力知道為啥被拒了。比如這個時候,清華表示我們不要高考分沒到咱們線上並且你又沒自主招生加分 blahblahblah。
在法律問題裁定上,假如在以前,我們用一個什麼演演算法,你說哇它老牛逼了。但是有人不服咋辦?那麼這個時候,這個演演算法能夠被認為是可接受作為判定憑證的嗎?俗話說的好,罵人也要名正言順的罵人。

而問題更嚴重的是你能保證你的演演算法不偏不倚,是個公正的演演算法嗎?演演算法就不能有偏見嗎?OpenAI 和 DeepMind 提出一些質疑[8][9],甚至有一些暢銷書作家也提到類似的內容。
例如我們的用來做法律裁定的演演算法中可能是輸入一大堆個人資訊,例如有種族、所住的街區等等,輸出是裁定的刑期。假如某些群體他符合某些情況,那麼是不是因為演演算法的偏好而可能被判更長的刑期?或者說,你怎麼能保證大量的輸入資料中,法官對其做出的判決是 100% 無偏見的呢?
這個時候 OpenAI 和 DeepMind 就認為,搞不定資料輸入是不是沒問題?ok啊,我如果完全無監督,用強化學習來做呢?那就沒有這個問題了對吧?另一種做法是在我們在所有的人工智慧模型中建立 “不確定性” – 基本上可以讓人類糾正未來的行為,而不是完全理解。然而即使如此,機器學習/深度學習演演算法其實還是很難作為一個裁定。
然而現在不一樣了,我們能夠給出一個看的過去的解釋了。
參考來源:
1. The building blocks ofinterpretability. https://distill.pub/2018/building-blocks/
2. Stanford University, CS231n Lecture2 study material. Offered by Justin Johnson.
3. Stanford University, CS231nLecture Slides. (http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture2.pdf)
4. Na Lei, Kehua Su, Li Cui,Shing-Tung Yau, Xianfeng Gu. A Geometric View of Optimal Transportation andGenerative Model.
5. Xianfeng Gu, Feng Luo, Jian Sunand Shing-Tung Yau, Variational Principles for Minkowski Type Problems,Discrete Optimal Transport, and Discrete Monge-Ampere Equations, Vol. 20, No.2, pp. 383-398, Asian Journal of Mathematics (AJM), April 2016.
6. Yann Brenier. Polarfactorization and monotone rearrangement of vector-valued functions. Comm. PureAppl. Math., 44(4):375–417, 1991.
7. Right to explanation, WikiPedia.https://en.wikipedia.org/wiki/Right_to_explanation
8. Jan Leike, Miljan Martic,Victoria Krakovna, Pedro A. Ortega, Tom Everitt, Andrew Lefrancq, LaurentOrseau, Shane Legg. AI Safety Gridworlds
9. Paul Christiano, Jan Leike, TomB. Brown, Miljan Martic, Shane Legg, Dario Amodei. Deep reinforcement learningfrom human preferences
來源:優達學城Udacity
精彩活動
推薦閱讀
2017年資料視覺化的七大趨勢!
全球100款大資料工具彙總(前50款)
Q: 為什麼我們迫切需要把深度學習的黑箱拆開?
歡迎留言與大家分享
請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:hzzy@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視

