小編邀請您,先思考:
1 你熟悉那些機器學習演演算法?
2 你如何應用機器學習演演算法?
前言
谷歌董事長施密特曾說過:雖然谷歌的無人駕駛汽車和機器人受到了許多媒體關註,但是這家公司真正的未來在於機器學習,一種讓計算機更聰明、更個性化的技術。
也許我們生活在人類歷史上最關鍵的時期:從使用大型計算機,到個人電腦,再到現在的雲端計算。關鍵的不是過去發生了什麼,而是將來會有什麼發生。
工具和技術的民主化,讓像我這樣的人對這個時期興奮不已。計算的蓬勃發展也是一樣。如今,作為一名資料科學家,用複雜的演演算法建立資料處理機器一小時能賺到好幾美金。但能做到這個程度可並不簡單!我也曾有過無數黑暗的日日夜夜。
誰能從這篇指南里受益最多?
我今天所給出的,也許是我這輩子寫下的最有價值的指南。
這篇指南的目的,是為那些有追求的資料科學家和機器學習狂熱者們,簡化學習旅途。這篇指南會讓你動手解決機器學習的問題,並從實踐中獲得真知。我提供的是幾個機器學習演演算法的高水平理解,以及執行這些演演算法的 R 和 Python 程式碼。這些應該足以讓你親自試一試了。

我特地跳過了這些技術背後的資料,因為一開始你並不需要理解這些。如果你想從資料層面上理解這些演演算法,你應該去別處找找。但如果你想要在開始一個機器學習專案之前做些準備,你會喜歡這篇文章的。
廣義來說,有三種機器學習演演算法
1、 監督式學習
工作機制:這個演演算法由一個標的變數或結果變數(或因變數)組成。這些變數由已知的一系列預示變數(自變數)預測而來。利用這一系列變數,我們生成一個將輸入值對映到期望輸出值的函式。這個訓練過程會一直持續,直到模型在訓練資料上獲得期望的精確度。監督式學習的例子有:回歸、決策樹、隨機森林、K – 近鄰演演算法、邏輯回歸等。
2、非監督式學習
工作機制:在這個演演算法中,沒有任何標的變數或結果變數要預測或估計。這個演演算法用在不同的組內聚類分析。這種分析方式被廣泛地用來細分客戶,根據幹預的方式分為不同的使用者組。非監督式學習的例子有:關聯演演算法和 K – 均值演演算法。
3、強化學習
工作機制:這個演演算法訓練機器進行決策。它是這樣工作的:機器被放在一個能讓它透過反覆試錯來訓練自己的環境中。機器從過去的經驗中進行學習,並且嘗試利用瞭解最透徹的知識作出精確的商業判斷。 強化學習的例子有馬爾可夫決策過程。
常見機器學習演演算法名單
這裡是一個常用的機器學習演演算法名單。這些演演算法幾乎可以用在所有的資料問題上:
-
線性回歸
-
邏輯回歸
-
決策樹
-
SVM
-
樸素貝葉斯
-
K最近鄰演演算法
-
K均值演演算法
-
隨機森林演演算法
-
降維演演算法
-
Gradient Boost 和 Adaboost 演演算法
1、線性回歸
線性回歸通常用於根據連續變數估計實際數值(房價、呼叫次數、總銷售額等)。我們透過擬合最佳直線來建立自變數和因變數的關係。這條最佳直線叫做回歸線,並且用 Y= a *X + b 這條線性等式來表示。
理解線性回歸的最好辦法是回顧一下童年。假設在不問對方體重的情況下,讓一個五年級的孩子按體重從輕到重的順序對班上的同學排序,你覺得這個孩子會怎麼做?他(她)很可能會目測人們的身高和體型,綜合這些可見的引數來排列他們。這是現實生活中使用線性回歸的例子。實際上,這個孩子發現了身高和體型與體重有一定的關係,這個關係看起來很像上面的等式。
在這個等式中:
-
Y:因變數
-
a:斜率
-
x:自變數
-
b :截距
繫數 a 和 b 可以透過最小二乘法獲得。
參見下例。我們找出最佳擬合直線 y=0.2811x+13.9。已知人的身高,我們可以透過這條等式求出體重。

線性回歸的兩種主要型別是一元線性回歸和多元線性回歸。一元線性回歸的特點是隻有一個自變數。多元線性回歸的特點正如其名,存在多個自變數。找最佳擬合直線的時候,你可以擬合到多項或者曲線回歸。這些就被叫做多項或曲線回歸。
Python 程式碼
#Import Library
#Import other necessary libraries like pandas, numpy…
from sklearn import linear_model
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train=input_variables_values_training_datasets
y_train=target_variables_values_training_datasets
x_test=input_variables_values_test_datasets
# Create linear regression object
linear = linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#Equation coefficient and Intercept
print(‘Coefficient: n’, linear.coef_)
print(‘Intercept: n’, linear.intercept_)
#Predict Output
predicted= linear.predict(x_test)
R程式碼
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train input_variables_values_training_datasets
y_train target_variables_values_training_datasets
x_test input_variables_values_test_datasets
x cbind(x_train,y_train)
# Train the model using the training sets and check score
linear lm(y_train ~ ., data = x)
summary(linear)
#Predict Output
predicted= predict(linear,x_test)
2、邏輯回歸
別被它的名字迷惑了!這是一個分類演演算法而不是一個回歸演演算法。該演演算法可根據已知的一系列因變數估計離散數值(比方說二進位制數值 0 或 1 ,是或否,真或假)。簡單來說,它透過將資料擬合進一個邏輯函式來預估一個事件出現的機率。因此,它也被叫做邏輯回歸。因為它預估的是機率,所以它的輸出值大小在 0 和 1 之間(正如所預計的一樣)。
讓我們再次透過一個簡單的例子來理解這個演演算法。
假設你的朋友讓你解開一個謎題。這隻會有兩個結果:你解開了或是你沒有解開。想象你要解答很多道題來找出你所擅長的主題。這個研究的結果就會像是這樣:假設題目是一道十年級的三角函式題,你有 70%的可能會解開這道題。然而,若題目是個五年級的歷史題,你只有30%的可能性回答正確。這就是邏輯回歸能提供給你的資訊。
從數學上看,在結果中,機率的對數使用的是預測變數的線性組合模型。
odds= p/ (1–p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1–p))
logit(p) = ln(p/(1–p)) = b0+b1X1+b2X2+b3X3….+bkXk
在上面的式子裡,p 是我們感興趣的特徵出現的機率。它選用使觀察樣本值的可能性最大化的值作為引數,而不是透過計算誤差平方和的最小值(就如一般的回歸分析用到的一樣)。
現在你也許要問了,為什麼我們要求出對數呢?簡而言之,這種方法是複製一個階梯函式的最佳方法之一。我本可以更詳細地講述,但那就違背本篇指南的主旨了。

Python程式碼
#Import Library
from sklearn.linear_model import LogisticRegression
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create logistic regression object
model = LogisticRegression()
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Equation coefficient and Intercept
print(‘Coefficient: n’, model.coef_)
print(‘Intercept: n’, model.intercept_)
#Predict Output
predicted= model.predict(x_test)
R程式碼
x cbind(x_train,y_train)
# Train the model using the training sets and check score
logistic glm(y_train ~ ., data = x,family=‘binomial’)
summary(logistic)
#Predict Output
predicted= predict(logistic,x_test)
更進一步:
你可以嘗試更多的方法來改進這個模型:
-
加入互動項
-
精簡模型特性
-
使用正則化方法
-
使用非線性模型
3、決策樹
這是我最喜愛也是最頻繁使用的演演算法之一。這個監督式學習演演算法通常被用於分類問題。令人驚奇的是,它同時適用於分類變數和連續因變數。在這個演演算法中,我們將總體分成兩個或更多的同類群。這是根據最重要的屬性或者自變數來分成盡可能不同的組別。想要知道更多,可以閱讀:簡化決策樹。
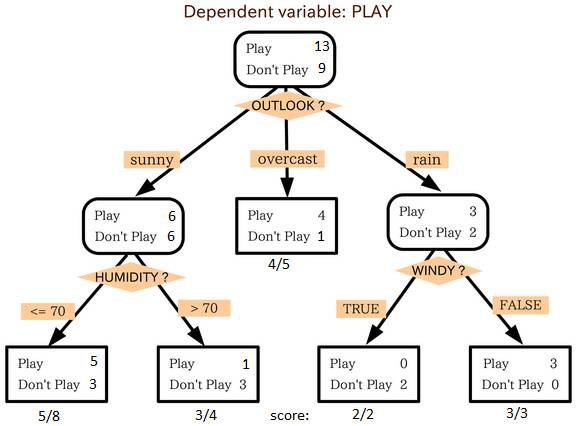
來源: statsexchange
在上圖中你可以看到,根據多種屬性,人群被分成了不同的四個小組,來判斷 “他們會不會去玩”。為了把總體分成不同組別,需要用到許多技術,比如說 Gini、Information Gain、Chi-square、entropy。
理解決策樹工作機制的最好方式是玩Jezzball,一個微軟的經典遊戲(見下圖)。這個遊戲的最終目的,是在一個可以移動牆壁的房間裡,透過造牆來分割出沒有小球的、儘量大的空間。

因此,每一次你用牆壁來分隔房間時,都是在嘗試著在同一間房裡建立兩個不同的總體。相似地,決策樹也在把總體儘量分割到不同的組裡去。
更多資訊請見:決策樹演演算法的簡化(http://www.analyticsvidhya.com/blog/2015/01/decision-tree-simplified/)
Python程式碼
#Import Library
#Import other necessary libraries like pandas, numpy…
from sklearn import tree
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create tree object
model = tree.DecisionTreeClassifier(criterion=‘gini’) # for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
R程式碼
library(rpart)
x cbind(x_train,y_train)
# grow tree
fit rpart(y_train ~ ., data = x,method=“class”)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
4、支援向量機
這是一種分類方法。在這個演演算法中,我們將每個資料在N維空間中用點標出(N是你所有的特徵總數),每個特徵的值是一個坐標的值。
舉個例子,如果我們只有身高和頭髮長度兩個特徵,我們會在二維空間中標出這兩個變數,每個點有兩個坐標(這些坐標叫做支援向量)。
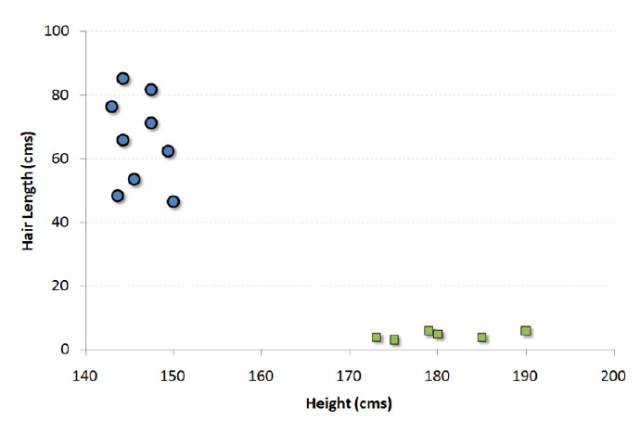
現在,我們會找到將兩組不同資料分開的一條直線。兩個分組中距離最近的兩個點到這條線的距離同時最最佳化。

上面示例中的黑線將資料分類最佳化成兩個小組,兩組中距離最近的點(圖中A、B點)到達黑線的距離滿足最優條件。這條直線就是我們的分割線。接下來,測試資料落到直線的哪一邊,我們就將它分到哪一類去。
更多請見:支援向量機的簡化(http://www.analyticsvidhya.com/blog/2014/10/support-vector-machine-simplified/)
將這個演演算法想作是在一個 N 維空間玩 JezzBall。需要對遊戲做一些小變動:
-
比起之前只能在水平方向或者豎直方向畫直線,現在你可以在任意角度畫線或平面。
-
遊戲的目的變成把不同顏色的球分割在不同的空間裡。
-
球的位置不會改變。
Python程式碼
#Import Library
from sklearn import svm
#Assumed you have, X (predic
tor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc() # there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
R程式碼
library(e1071)
x cbind(x_train,y_train)
# Fitting model
fit svm(y_train ~ ., data = x)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
5、樸素貝葉斯
在預示變數間相互獨立的前提下,根據貝葉斯定理可以得到樸素貝葉斯這個分類方法。用更簡單的話來說,一個樸素貝葉斯分類器假設一個分類的特性與該分類的其它特性不相關。舉個例子,如果一個水果又圓又紅,並且直徑大約是 3 英寸,那麼這個水果可能會是蘋果。即便這些特性互相依賴,或者依賴於別的特性的存在,樸素貝葉斯分類器還是會假設這些特性分別獨立地暗示這個水果是個蘋果。
樸素貝葉斯模型易於建造,且對於大型資料集非常有用。雖然簡單,但是樸素貝葉斯的表現卻超越了非常複雜的分類方法。
貝葉斯定理提供了一種從P(c)、P(x)和P(x|c) 計算後驗機率 P(c|x) 的方法。請看以下等式:

在這裡,
-
P(c|x) 是已知預示變數(屬性)的前提下,類(標的)的後驗機率
-
P(c) 是類的先驗機率
-
P(x|c) 是可能性,即已知類的前提下,預示變數的機率
-
P(x) 是預示變數的先驗機率
例子:讓我們用一個例子來理解這個概念。在下麵,我有一個天氣的訓練集和對應的標的變數“Play”。現在,我們需要根據天氣情況,將會“玩”和“不玩”的參與者進行分類。讓我們執行以下步驟。
步驟1:把資料集轉換成頻率表。
步驟2:利用類似“當Overcast可能性為0.29時,玩耍的可能性為0.64”這樣的機率,創造 Likelihood 表格。

步驟3:現在,使用樸素貝葉斯等式來計算每一類的後驗機率。後驗機率最大的類就是預測的結果。
問題:如果天氣晴朗,參與者就能玩耍。這個陳述正確嗎?
我們可以使用討論過的方法解決這個問題。於是 P(會玩 | 晴朗)= P(晴朗 | 會玩)* P(會玩)/ P (晴朗)
我們有 P (晴朗 |會玩)= 3/9 = 0.33,P(晴朗) = 5/14 = 0.36, P(會玩)= 9/14 = 0.64
現在,P(會玩 | 晴朗)= 0.33 * 0.64 / 0.36 = 0.60,有更大的機率。
樸素貝葉斯使用了一個相似的方法,透過不同屬性來預測不同類別的機率。這個演演算法通常被用於文字分類,以及涉及到多個類的問題。
Python程式碼
#Import Library
from sklearn.naive_bayes import GaussianNB
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
R程式碼
library(e1071)
x cbind(x_train,y_train)
# Fitting model
fit naiveBayes(y_train ~ ., data = x)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
6、KNN(K – 最近鄰演演算法)
該演演算法可用於分類問題和回歸問題。然而,在業界內,K – 最近鄰演演算法更常用於分類問題。K – 最近鄰演演算法是一個簡單的演演算法。它儲存所有的案例,透過周圍k個案例中的大多數情況劃分新的案例。根據一個距離函式,新案例會被分配到它的 K 個近鄰中最普遍的類別中去。
這些距離函式可以是歐式距離、曼哈頓距離、明式距離或者是漢明距離。前三個距離函式用於連續函式,第四個函式(漢明函式)則被用於分類變數。如果 K=1,新案例就直接被分到離其最近的案例所屬的類別中。有時候,使用 KNN 建模時,選擇 K 的取值是一個挑戰。
更多資訊:K – 最近鄰演演算法入門(簡化版)

我們可以很容易地在現實生活中應用到 KNN。如果想要瞭解一個完全陌生的人,你也許想要去找他的好朋友們或者他的圈子來獲得他的資訊。
在選擇使用 KNN 之前,你需要考慮的事情:
-
KNN 的計算成本很高。
-
變數應該先標準化(normalized),不然會被更高範圍的變數偏倚。
-
在使用KNN之前,要在野值去除和噪音去除等前期處理多花功夫。
Python程式碼
#Import Library
from sklearn.neighbors import KNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model
KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
R程式碼
library(knn)
x cbind(x_train,y_train)
# Fitting model
fit knn(y_train ~ ., data = x,k=5)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
7、K 均值演演算法
K – 均值演演算法是一種非監督式學習演演算法,它能解決聚類問題。使用 K – 均值演演算法來將一個資料歸入一定數量的叢集(假設有 k 個叢集)的過程是簡單的。一個叢集內的資料點是均勻齊次的,並且異於別的叢集。
還記得從墨水漬裡找出形狀的活動嗎?K – 均值演演算法在某方面類似於這個活動。觀察形狀,並延伸想象來找出到底有多少種叢集或者總體。

K – 均值演演算法怎樣形成叢集:
-
K – 均值演演算法給每個叢集選擇k個點。這些點稱作為質心。
-
每一個資料點與距離最近的質心形成一個叢集,也就是 k 個叢集。
-
根據現有的類別成員,找出每個類別的質心。現在我們有了新質心。
-
當我們有新質心後,重覆步驟 2 和步驟 3。找到距離每個資料點最近的質心,並與新的k叢集聯絡起來。重覆這個過程,直到資料都收斂了,也就是當質心不再改變。
如何決定 K 值:
K – 均值演演算法涉及到叢集,每個叢集有自己的質心。一個叢集內的質心和各資料點之間距離的平方和形成了這個叢集的平方值之和。同時,當所有叢集的平方值之和加起來的時候,就組成了叢集方案的平方值之和。
我們知道,當叢集的數量增加時,K值會持續下降。但是,如果你將結果用圖表來表示,你會看到距離的平方總和快速減少。到某個值 k 之後,減少的速度就大大下降了。在此,我們可以找到叢集數量的最優值。

Python程式碼
#Import Library
from sklearn.cluster import KMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means = KMeans(n_clusters=3, random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted= model.predict(x_test)
R程式碼
library(cluster)
fit kmeans(X, 3) # 5 cluster solution
8、隨機森林
隨機森林是表示決策樹總體的一個專有名詞。在隨機森林演演算法中,我們有一系列的決策樹(因此又名“森林”)。為了根據一個新物件的屬性將其分類,每一個決策樹有一個分類,稱之為這個決策樹“投票”給該分類。這個森林選擇獲得森林裡(在所有樹中)獲得票數最多的分類。
每棵樹是像這樣種植養成的:
-
如果訓練集的案例數是 N,則從 N 個案例中用重置抽樣法隨機抽取樣本。這個樣本將作為“養育”樹的訓練集。
-
假如有 M 個輸入變數,則定義一個數字 m<
-
盡可能大地種植每一棵樹,全程不剪枝。
若想瞭解這個演演算法的更多細節,比較決策樹以及最佳化模型引數,我建議你閱讀以下文章:
-
隨機森林入門—簡化版
-
將 CART 模型與隨機森林比較(上)
-
將隨機森林與 CART 模型比較(下)
-
調整你的隨機森林模型引數
Python
#Import Library
from sklearn.ensemble import RandomForestClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Random Forest object
model= RandomForestClassifier()
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
R程式碼
library(randomForest)
x cbind(x_train,y_train)
# Fitting model
fit randomForest(Species ~ ., x,ntree=500)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
9、降維演演算法
在過去的 4 到 5 年裡,在每一個可能的階段,資訊捕捉都呈指數增長。公司、政府機構、研究組織在應對著新資源以外,還捕捉詳盡的資訊。
舉個例子:電子商務公司更詳細地捕捉關於顧客的資料:個人資訊、網路瀏覽記錄、他們的喜惡、購買記錄、反饋以及別的許多資訊,比你身邊的雜貨店售貨員更加關註你。
作為一個資料科學家,我們提供的資料包含許多特點。這聽起來給建立一個經得起考研的模型提供了很好材料,但有一個挑戰:如何從 1000 或者 2000 裡分辨出最重要的變數呢?在這種情況下,降維演演算法和別的一些演演算法(比如決策樹、隨機森林、PCA、因子分析)幫助我們根據相關矩陣,缺失的值的比例和別的要素來找出這些重要變數。
想要知道更多關於該演演算法的資訊,可以閱讀《降維演演算法的初學者指南》。
Python程式碼
#Import Library
from sklearn import decomposition
#Assumed you have training and test data set as train and test
# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)
# For Factor analysis
#fa= decomposition.FactorAnalysis()
# Reduced the dimension of training dataset using PCA
train_reduced = pca.fit_transform(train)
#Reduced the dimension of test dataset
test_reduced = pca.transform(test)
#For more detail on this, please refer this link.
R程式碼
library(stats)
pca princomp(train, cor = TRUE)
train_reduced predict(pca,train)
test_reduced predict(pca,test)
10、Gradient Boosting 和 AdaBoost 演演算法
當我們要處理很多資料來做一個有高預測能力的預測時,我們會用到 GBM 和 AdaBoost 這兩種 boosting 演演算法。boosting 演演算法是一種整合學習演演算法。它結合了建立在多個基礎估計值基礎上的預測結果,來增進單個估計值的可靠程度。這些 boosting 演演算法通常在資料科學比賽如 Kaggl、AV Hackathon、CrowdAnalytix 中很有效。
更多:詳盡瞭解 Gradient 和 AdaBoost
Python程式碼
#Import Library
from sklearn.ensemble import GradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
R程式碼
library(caret)
x cbind(x_train,y_train)
# Fitting model
fitControl trainControl( method = “repeatedcv”, number = 4, repeats = 4)
fit train(y ~ ., data = x, method = “gbm”, trControl = fitControl,verbose = FALSE)
predicted= predict(fit,x_test,type= “prob”)[,2]
GradientBoostingClassifier 和隨機森林是兩種不同的 boosting 樹分類器。人們常常問起這兩個演演算法之間的區別。
結語
現在我能確定,你對常用的機器學習演演算法應該有了大致的瞭解。寫這篇文章並提供 Python 和 R 語言程式碼的唯一目的,就是讓你立馬開始學習。如果你想要掌握機器學習,那就立刻開始吧。做做練習,理性地認識整個過程,應用這些程式碼,並感受樂趣吧!
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
