
在GitHub上有超過21000顆星,超過一千個提交者,以及一個包括Google、RedHat、Intel在內的生態系統,Kubernetes已經讓容器生態系統風靡一時。Kubernetes這麼火是因為它充當了分散式容器部署的大腦,它旨在使用分佈在宿主機叢集上的容器來管理面向服務的應用程式。Kubernetes為應用程式部署、服務發現、排程、更新、運維以及擴容提供了相關機制,但對於Kubernetes監控呢?
雖然Kubernetes能夠顯著簡化在容器中以及在雲上部署應用程式的過程,但同時它也增加了日常管理應用程式效能、獲取服務可見性以及監控->報警->故障排除流程的複雜性。
基礎設施層次的新型複雜性出現在期望簡化應用程式部署的過程中:透過IaaS層動態配置;使用配置管理工具自動配置;以及使用像Kubernetes一樣的編排工具,這些編排工具介於裸機或者虛機基礎設施和支援應用程式的服務之間。

除了增加基礎設施複雜性之外,應用程式正在被設計成微服務,在微服務結構中,更多元件之間需要互相通訊。每個服務都可以分佈在多個實體上,Docker容器根據需求跨越基礎設施。在我們知道每個服務元件有多少實體以及它們的部署位置之前,情況就不再是這樣了。這會怎麼影響Kubernetes監控的方法和工具呢?正如Site Reliability Engineering – How Google Runs Production Systems[1]中所述,“我們需要監控系統,讓我對高層次服務標的保持警惕,但也要根據需求保持對單個元件粒度的監控”。考慮到這一點,這篇部落格是一個系列中的第一篇,幫助您更好地理解在生產中使用Kubernetes的行為。 這四部分組成的系列包括:
-
第一部分(本篇):Kubernetes監控開源工具的基本介紹以及使用Sysdig進行監控。
-
第二部分:Kubernetes報警的最佳實踐[2]
-
第三部分:透過系統捕獲對Kubernetes服務發現進行故障排除[3]
-
第四部分:WayBlazer的Kubernetes監控(一個示例)[4]

從物理/基礎設施的角度來看,Kubernetes叢集由一組master節點監控的nodes組成。master節點的任務包括跨node節點的容器編排、狀態追蹤以及透過REST API和UI介面暴露叢集控制。
另一方面,從邏輯/應用的角度來看,Kubernetes叢集按照圖中所示的層級方式排列:
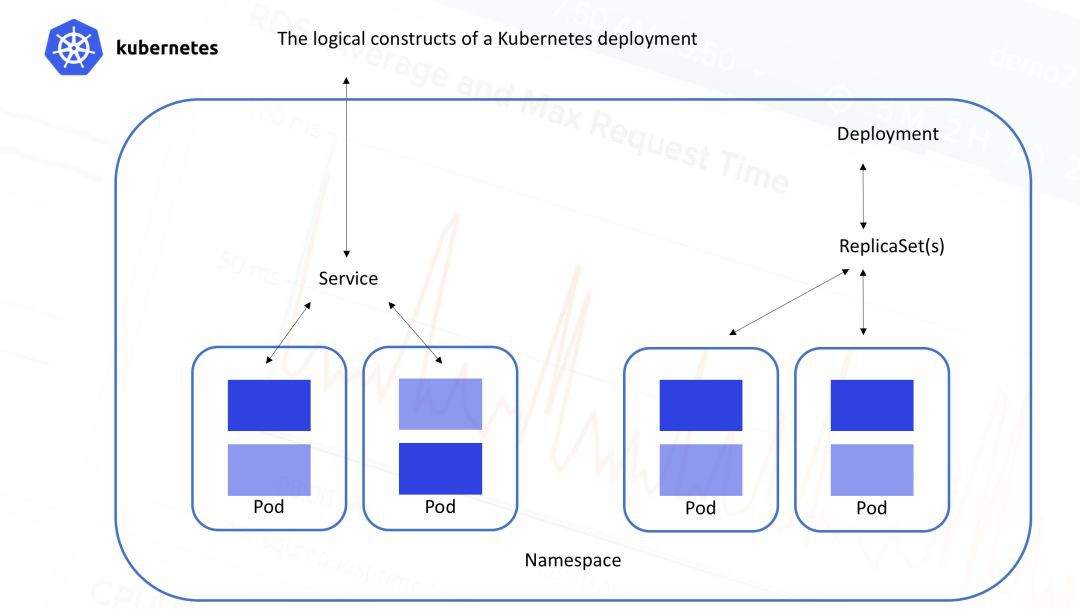
所有容器執行在Pods中,一個Pod是一組容器集合。這些容器總是部署在一起並且一起進行排程,它們執行在共享的環境中並且擁有共享的儲存。Pod中的容器被保證部署在相同的機器上,可以共享資源。
-
Pods位於services之後,service主要負責負載均衡,並且將一組Pod作為一個可發現的IP地址/埠進行暴露。
-
Services透過replica sets(之前成為副本控制器)進行水平伸縮,它根據需求為每個服務建立/銷毀Pod。
-
ReplicaSets由deployments進行控制,它允許對執行中的replicasets以及Pods進行狀態申明。
-
Namespaces代表虛擬叢集,可以包含一個或者多個services。
-
Metadata允許使用labels和tags基於容器的部署特性進行標記。
所以需要搞清楚的是,多個services甚至多個namespaces可以分散在同一個物理基礎設施中。每個service都由多個Pod構建,而每個Pod都有多個container構成,這就為監控增加了一定程度的複雜性,即使是適度的Kubernetes部署也是如此。
讓我們來看看Kubernetes本身提供的解決方案。
和大多數平臺一樣,Kubernetes有一套基本的工具,可以讓你監控你的伺服器,在這種情況下,Kubernetes可以直接部署在物理基礎設施之上。“內建”一詞可能有點言過其實,更公正地說,考慮到Kubernetes的可擴充套件性,你可以新增額外的元件來獲取Kubernetes的可見性,讓我們來看看其中的幾個選擇:
-
Probes
-
cAdvisor
-
Heapster
-
Kubernetes Dashboard
-
Kebu-state-metrics
之後我們將對比一下這些選擇和使用Sysdig進行監控。
Liveness和Readiness Probes
Kubernetes Probes具有定期監測集裝箱或服務的健康狀況的重要功能,併在發生不健康的事件時採取行動。Kubernetes監控探針允許你透過設定一個特定的命令來定義“Liveness”狀態,這個命令應該在Pod中成功執行。你還可以設定Liveness探針執行的頻率。以下是一個簡單的示例,基於cat命令。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
-name: liveness
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
image: gcr.io/google_containers/busybox
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Readiness Probe某種程度上說是Liveness Probe的修正版,同樣它是執行一條命令來檢測Pod在啟動/重啟後是否準備好進行工作。
cAdvisor是一個開源的容器資源使用收集器。它是專門為容器構建的,原生支援Docker容器。與在Pod級別執行的Kubernetes中的大多數元素不同,cAdvisor在每個node節點上執行。它會自動發現給定node節點中的所有容器,並收集CPU,記憶體,檔案系統和網路使用統計資訊。cAdvisor還透過分析機器上的“root”容器來提供整體機器使用情況。不過,cAdvisor兩個方面有限制性:
-
它只能收集一些基本的資源利用資訊——cAdvisor不能夠告訴你應用程式的真實效能,它只能告訴你一個容器使用了X% CPU資訊。
-
cAdvisor自身沒有提供任何長期儲存、趨勢或者分析功能。
為了進一步處理這些資料,我們需要新增Heapster。Heapster會聚集Kubernetes叢集中所有節點上的資料。Heapster作為叢集中的一個Pod執行,就像其他應用程式一樣。Heapster Pod透過節點上Kubelets(機器上的Kubernetes agent)查詢使用資訊,而Kubelets又查詢來自cAdvisor的資料。最終,Heapster將來自相關標簽的Pod資訊進行分組。
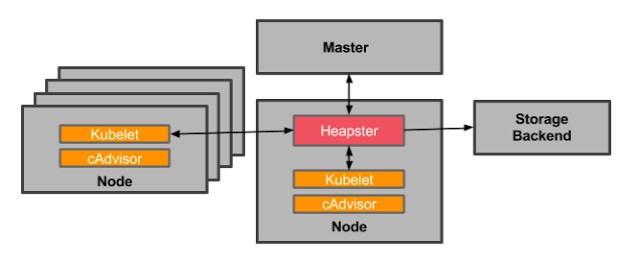
在Kubernetes中使用Heapster和cAdvisor進行監控,來源:blog.kubernetes.io
不過,Heapster也不能夠進行儲存資料、趨勢分析以及報警。它只是讓你更容易在整個叢集中收集cAdvisor資料。所以,你還需要將資料推送到可配置的後端進行儲存和視覺化,目前支援的後端包括InfluxDB,Google Cloud Monitoring等。此外,你還必須新增一個和Grafana一樣的視覺化圖層來檢視資料。
最近比較流行使用Kubernets外掛提供一致性方式來檢視一些基礎資料以及管理叢集環境。Kubernetes Dashboard提供了一種依據Kubernetes元資料來檢視您的環境的簡單方式。它有兩個優勢:基本的CPU/記憶體資料是可用的,以及可以在Dashboard上採取行動。

簡單透過kubectl安裝Dashboard,Kubernetes命令:
$ kubectl create -f https://rawgit.com/kubernetes/dashboard/master/src/deploy/kubernetes-dashboard.yaml
然後在安裝了Dashboard的機器上透過localhost進行訪問:http://localhost:8001/ui。
kube-state-metrics:作為監控設定的補充
除了配置cAdvisor/Heapster/Influx/Grafana之外,還可以考慮部署kube-state-metrics。這是一個附加服務,與Heapster一起執行,它會輪詢Kubernetes API並將有關你的Kubernetes結構化特徵資訊轉換為metrics資訊。以下是kube-state-metrics會回答的一些問題:
……等等。一般來說,該模型將採集Kubernetes事件並將其轉換為metrics資訊。需要Kubernetes 1.2+版本,不過,需要提醒的是metrics名稱和標簽是不穩定的,可能會改變。
透過以上介紹,至少可以讓你瞭解如何為你的Kubernetes環境構建合理的監控配置。雖然我們仍然沒有詳細的應用程式監控(例如:“我的資料庫服務的響應時間是多少?”),但我們至少可以看到我們的宿主機,Kubernetes節點以及我們的Kubernetes抽象狀態的一些監控。
讓我們來看看Sysdig進行Kubernetes監控的方式。
在與數百名Kubernetes使用者交談之後,似乎典型的叢集管理員往往有興趣從物理角度來看事物,而負責構建服務的應用程式開發人員往往更傾向於從邏輯角度來看事物。無論你從什麼角度進行觀察,所有團隊都希望減少他們為了測試系統或管理資料收集而需要完成的工作量。
考慮到這兩個用例,Sysdig Monitor對Kubernetes的支援現在可以做到:
-
透過連線到Kubernetes的叢集API伺服器並查詢API(常規API和觀察API)我們現在可以推斷出您的微服務應用程式物理和邏輯結構。
-
另外,我們透傳獲取到的重要元資料資訊,例如labels。
-
這些資訊與我們的ContainerVision[4]技術相結合,這使得我們可以檢查在容器內執行的應用程式,而不需要對任何容器或應用程式進行檢測。檢測在每個節點上進行,而不是針對每個Pod。
-
因此,使用單一的檢測點,你就可以監控你的主機、網路、容器和應用程式——所有這些都使用Kubernetes元資料進行標記。您可以透過Kubernetes中的DaemonSet部署Sysdig。
-
然後,你可以根據你的要求,在Sysdig Monitor的雲服務或我們的內部部署軟體中對此資料進行視覺化和報警。
基於此,Sysdig Monitor現在可以從以基礎架構為中心和以應用為中心的角度提供豐富的可視性和背景關係。 兩全其美!
Sysdig Monitor的核心功能之一就是分組。你可以根據物理層次(例如,AWS region > Host > pod > container),或者基於邏輯微服務層次(例如,namespace > replicaset > pod > container)對容器進行分組和檢索。


如果你對利用你的基礎物理資源感興趣——例如識別noisy neighbors——那麼物理層次是較好的選擇。但是如果你正在研究應用程式和微服務的效能,那麼邏輯層次往往是較好的。
一般來說,與典型Dashboard相比,動態重新組合基礎架構的能力是解決環境故障更強大的方法。
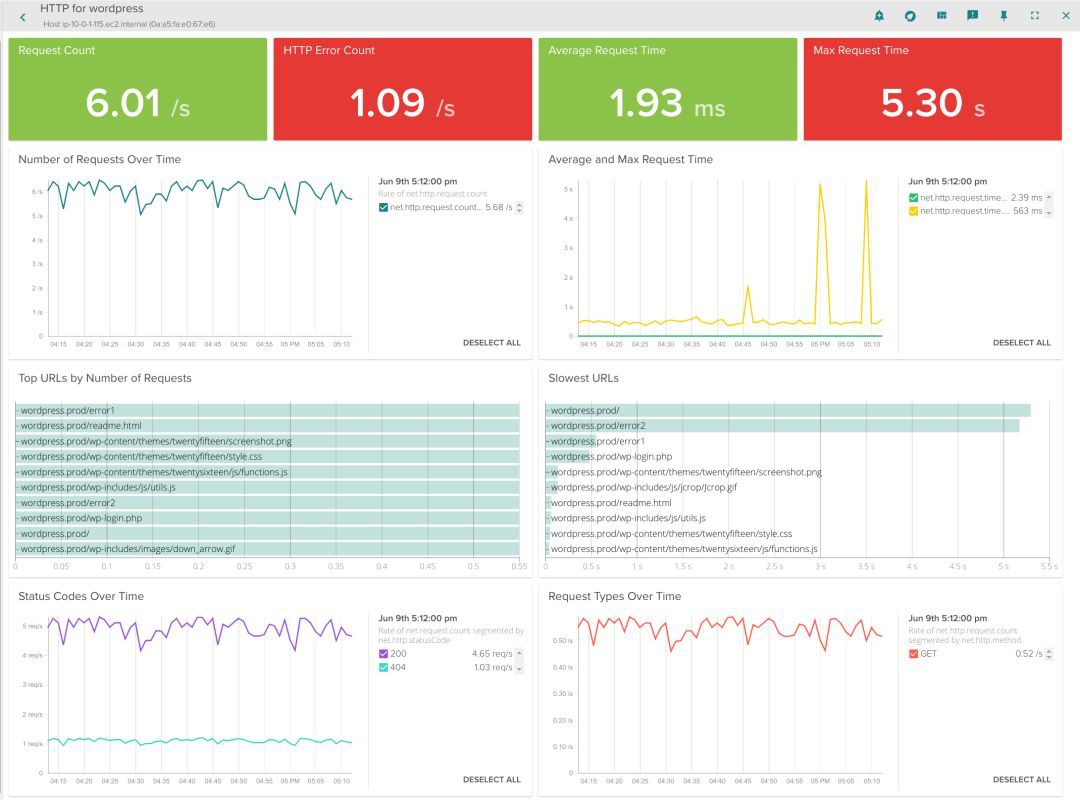
例如:透過單擊邏輯表中的Prod -> WordPress,我們會自動獲得一個dashboard,不管容器中執行的是主機或資料中心服務,該dashboard可以分析所有容器上聚合的HTTP服務效能。其中一個強大的概況是服務響應時間:跨所有相關容器自動聚合服務延遲,然後將其與資源利用率相關聯:

這使我們能夠快速分析服務是否按預期執行,是否與底層資源利用率有關。 現在我們可以更深入服務。
接下來,讓我們深入應用程式本身的特定指標——在本演示中使用WordPress應用程式充當我們的HTTP服務,讓我們來看看HTTP概況。
-
最常用的HTTP端點
-
最慢的HTTP端點
-
平均連線時間
-
錯誤
-
狀態碼
實現此服務的Pod可能分散在多臺計算機上,但我們仍然可以將此服務的請求計數、響應時間和URL統計資訊彙總在一起。不要忘記:這不需要任何配置或檢測WordPress、Apache或底層容器。
同樣,如果這是RabbitMQ、MySQL、Redis、Consul、Nginx或其他50多個元件服務,我們將以相同的方式執行(儘管每個應用程式的指標會有所不同)。
最後,根據你正在檢測的任何metrics資訊,檢視Kubernetes彙報的背景關係事件,可能會提供一些有用的線索用以檢視你的應用程式的執行過程。Sysdig會自動收集Kubernetes事件,所以你可以這麼做。

從這個檢視(或任何其他方面),你可以輕鬆地為Kubernetes service聚合的metrics資訊建立報警策略,而不是容器或node節點。此外,你仍然可以深入到任何單獨的容器中進行深度檢查直至行程級別。
上面的例子讓你感受瞭如何監控一個Kubernetes service的效能。但是如果我們想看到我們所有的service,以及他們如何相互溝通呢?我們透過拓撲檢視來完成這個任務。
下麵的兩張圖片展示的是完全相同的基礎設施和服務。第一張圖描述了物理層次,一個master節點和三個node節點:

而第二張圖將容器分組到Namespace、Service和Pod中,同時抽象容器的物理位置。

第二張(面向服務的)檢視對於監視Kubernetes應用程式是多麼自然和直觀。應用程式的結構和各種依賴性非常清晰。各種微服務之間的互動變得明顯,儘管這些微服務混合在我們的機器群集中!
主要結論是:如果你有一個非常龐大的部署,你必須開始考慮用一種適合你的方式來監視Kubernetes叢集環境。
-
https://landing.google.com/sre/book/chapters/practical-alerting.html
-
http://dockone.io/article/4053
-
http://dockone.io/article/4054
-
http://dockone.io/article/4055
-
http://sysdig.com/blog/no-plugins-required-application-visibility-inside-containers/
原文連結:https://sysdig.com/blog/monitoring-kubernetes-with-sysdig-cloud/
本次培訓內容包括:Docker容器的原理與基本操作;容器網路與儲存解析;Kubernetes的架構與設計理念詳解;Kubernetes的資源物件使用說明;Kubernetes 中的開放介面CRI、CNI、CSI解析;Kubernetes監控、網路、日誌管理;容器應用的開發流程詳解等,點選識別下方二維碼加微信好友瞭解具體培訓內容。

3月23日開始上課,還剩最後3個名額,點選閱讀原文連結即可報名。
長按二維碼向我轉賬
![]()
受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。