虛擬檔案系統層的處理:
核心函式 sys_read() 是 read 系統呼叫在該層的入口點,清單2顯示了該函式的程式碼。
清單2 sys_read 函式的程式碼

程式碼解析:
-
fget_light() :根據 fd 指定的索引,從當前行程描述符中取出相應的 file 物件(見圖3)。
-
如果沒找到指定的 file 物件,則傳回錯誤
-
如果找到了指定的 file 物件:
-
呼叫 file_pos_read() 函式取出此次讀寫檔案的當前位置。
-
呼叫 vfs_read() 執行檔案讀取操作,而這個函式最終呼叫 file->f_op.read() 指向的函式,程式碼如下:
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);
-
呼叫 file_pos_write() 更新檔案的當前讀寫位置。
-
呼叫 fput_light() 更新檔案的取用計數。
-
最後傳回讀取資料的位元組數。
到此,虛擬檔案系統層所做的處理就完成了,控制權交給了 ext2 檔案系統層。
在解析 ext2 檔案系統層的操作之前,先讓我們看一下 file 物件中 read 指標來源。
File 物件中 read 函式指標的來源:
從前面對 sys_open 核心函式的分析來看, file->f_op 來自於 inode->i_fop 。那麼 inode->i_fop 來自於哪裡呢?在初始化 inode 物件時賦予的。見清單3。
清單3 ext2_read_inode() 函式部分程式碼

從程式碼中可以看出,如果該 inode 所關聯的檔案是普通檔案,則將變數 ext2_file_operations 的地址賦予 inode 物件的 i_fop 成員。所以可以知道: inode->i_fop.read 函式指標所指向的函式為 ext2_file_operations 變數的成員 read 所指向的函式。下麵來看一下 ext2_file_operations 變數的初始化過程,如清單4。
清單4 ext2_file_operations 的初始化

該成員 read 指向函式 generic_file_read 。所以, inode->i_fop.read 指向 generic_file_read 函式,進而 file->f_op.read 指向 generic_file_read 函式。最終得出結論: generic_file_read 函式才是 ext2 層的真實入口。
Ext2 檔案系統層的處理
圖4 read 系統呼叫在 ext2 層中處理時函式呼叫關係
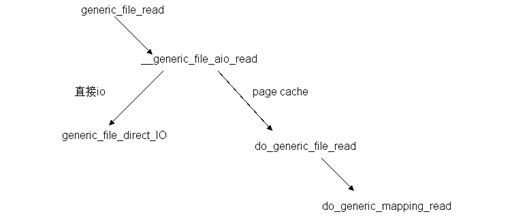
由圖 4 可知,該層入口函式 generic_file_read 呼叫函式 __generic_file_aio_read ,後者判斷本次讀請求的訪問方式,如果是直接 io (filp->f_flags 被設定了 O_DIRECT 標誌,即不經過 cache)的方式,則呼叫 generic_file_direct_IO 函式;如果是 page cache 的方式,則呼叫 do_generic_file_read 函式。函式 do_generic_file_read 僅僅是一個包裝函式,它又呼叫 do_generic_mapping_read 函式。
在講解 do_generic_mapping_read 函式都作了哪些工作之前,我們再來看一下檔案在記憶體中的快取區域是被怎麼組織起來的。
檔案的 page cache 結構
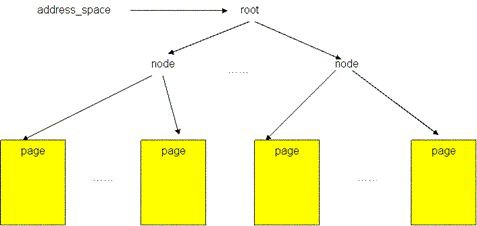
圖5顯示了一個檔案的 page cache 結構。檔案被分割為一個個以 page 大小為單元的資料塊,這些資料塊(頁)被組織成一個多叉樹(稱為 radix 樹)。樹中所有葉子節點為一個個頁幀結構(struct page),表示了用於快取該檔案的每一個頁。在葉子層最左端的第一個頁儲存著該檔案的前4096個位元組(如果頁的大小為4096位元組),接下來的頁儲存著檔案第二個4096個位元組,依次類推。樹中的所有中間節點為組織節點,指示某一地址上的資料所在的頁。此樹的層次可以從0層到6層,所支援的檔案大小從0位元組到16 T 個位元組。樹的根節點指標可以從和檔案相關的 address_space 物件(該物件儲存在和檔案關聯的 inode 物件中)中取得(更多關於 page cache 的結構內容請參見參考資料)。
圖5 檔案的 page cache 結構
現在,我們來看看函式 do_generic_mapping_read 都作了哪些工作, do_generic_mapping_read 函式程式碼較長,本文簡要介紹下它的主要流程:
-
根據檔案當前的讀寫位置,在 page cache 中找到快取請求資料的 page
-
如果該頁已經最新,將請求的資料複製到使用者空間
-
否則, Lock 該頁
-
呼叫 readpage 函式向磁碟發出添頁請求(當下層完成該 IO 操作時會解鎖該頁),程式碼:
|
1 |
|
-
再一次 lock 該頁,操作成功時,說明資料已經在 page cache 中了,因為只有 IO 操作完成後才可能解鎖該頁。此處是一個同步點,用於同步資料從磁碟到記憶體的過程。
-
解鎖該頁
-
到此為止資料已經在 page cache 中了,再將其複製到使用者空間中(之後 read 呼叫可以在使用者空間傳回了)
到此,我們知道:當頁上的資料不是最新的時候,該函式呼叫 mapping->a_ops->readpage 所指向的函式(變數 mapping 為 inode 物件中的 address_space 物件),那麼這個函式到底是什麼呢?
Readpage 函式的由來
address_space 物件是嵌入在 inode 物件之中的,那麼不難想象: address_space 物件成員 a_ops 的初始化工作將會在初始化 inode 物件時進行。如清單3中後半部所顯示。

可以知道 address_space 物件的成員 a_ops 指向變數 ext2_aops 或者變數 ext2_nobh_aops 。這兩個變數的初始化如清單5所示。
清單5 變數 ext2_aops 和變數 ext2_nobh_aops 的初始化

從上述程式碼中可以看出,不論是哪個變數,其中的 readpage 成員都指向函式 ext2_readpage 。所以可以斷定:函式 do_generic_mapping_read 最終呼叫 ext2_readpage 函式處理讀資料請求。
到此為止, ext2 檔案系統層的工作結束。
Page cache 層的處理
從上文得知:ext2_readpage 函式是該層的入口點。該函式呼叫 mpage_readpage 函式,清單6顯示了 mpage_readpage 函式的程式碼。
清單6 mpage_readpage 函式的程式碼

該函式首先呼叫函式 do_mpage_readpage 函式建立了一個 bio 請求,該請求指明瞭要讀取的資料塊所在磁碟的位置、資料塊的數量以及複製該資料的標的位置——快取區中 page 的資訊。然後呼叫 mpage_bio_submit 函式處理請求。 mpage_bio_submit 函式則呼叫 submit_bio 函式處理該請求,後者最終將請求傳遞給函式 generic_make_request ,並由 generic_make_request 函式將請求提交給通用塊層處理。
到此為止, page cache 層的處理結束。
通用塊層的處理
generic_make_request 函式是該層的入口點,該層只有這一個函式處理請求。清單7顯示了函式的部分程式碼
清單7 generic_make_request 函式部分程式碼

主要操作:
-
根據 bio 中儲存的塊裝置號取得請求佇列 q
-
檢測當前 IO 排程器是否可用,如果可用,則繼續;否則等待排程器可用
-
呼叫 q->make_request_fn 所指向的函式將該請求(bio)加入到請求佇列中
到此為止,通用塊層的操作結束。
IO 排程層的處理
對 make_request_fn 函式的呼叫可以認為是 IO 排程層的入口,該函式用於向請求佇列中新增請求。該函式是在建立請求佇列時指定的,程式碼如下(blk_init_queue 函式中):
|
1 2 |
|
函式 blk_queue_make_request 將函式 __make_request 的地址賦予了請求佇列 q 的 make_request_fn 成員,那麼, __make_request 函式才是 IO 排程層的真實入口。
__make_request 函式的主要工作為:
-
檢測請求佇列是否為空,若是,延緩驅動程式處理當前請求(其目的是想積累更多的請求,這樣就有機會對相鄰的請求進行合併,從而提高處理的效能),並跳到3,否則跳到2
-
試圖將當前請求同請求佇列中現有的請求合併,如果合併成功,則函式傳回,否則跳到3
-
該請求是一個新請求,建立新的請求描述符,並初始化相應的域,並將該請求描述符加入到請求佇列中,函式傳回
將請求放入到請求佇列中後,何時被處理就由 IO 排程器的排程演演算法決定了(有關 IO 排程器的演演算法內容請參見參考資料)。一旦該請求能夠被處理,便呼叫請求佇列中成員 request_fn 所指向的函式處理。這個成員的初始化也是在建立請求佇列時設定的:
|
1 2 |
|
第一行是將請求處理函式 rfn 指標賦給了請求佇列的 request_fn 成員。而 rfn 則是在建立請求佇列時透過引數傳入的。
對請求處理函式 request_fn 的呼叫意味著 IO 排程層的處理結束了。
塊裝置驅動層的處理
request_fn 函式是塊裝置驅動層的入口。它是在驅動程式建立請求佇列時由驅動程式傳遞給 IO 排程層的。
IO 排程層透過回呼 request_fn 函式的方式,把請求交給了驅動程式。而驅動程式從該函式的引數中獲得上層發出的 IO 請求,並根據請求中指定的資訊操作裝置控制器(這一請求的發出需要依據物理裝置指定的規範進行)。
到此為止,塊裝置驅動層的操作結束。
塊裝置層的處理
接受來自驅動層的請求,完成實際的資料複製工作等等。同時規定了一系列規範,驅動程式必須按照這個規範操作硬體。
後續工作
當裝置完成了 IO 請求之後,透過中斷的方式通知 cpu ,而中斷處理程式又會呼叫 request_fn 函式進行處理。
當驅動再次處理該請求時,會根據本次資料傳輸的結果通知上層函式本次 IO 操作是否成功,如果成功,上層函式解鎖 IO 操作所涉及的頁面(在 do_generic_mapping_read 函式中加的鎖)。
該頁被解鎖後, do_generic_mapping_read() 函式就可以再次成功獲得該鎖(資料的同步點),並繼續執行程式了。之後,函式 sys_read 可以傳回了。最終 read 系統呼叫也可以傳回了。
至此, read 系統呼叫從發出到結束的整個處理過程就全部結束了。
總結
本文介紹了 linux 系統呼叫 read 的處理全過程。該過程分為兩個部分:使用者空間的處理和核心空間的處理。在使用者空間中透過 0x80 中斷的方式將控制權交給核心處理,核心接管後,經過6個層次的處理最後將請求交給磁碟,由磁碟完成最終的資料複製操作。在這個過程中,呼叫了一系列的核心函式。如圖 6
圖6 read 系統呼叫在核心中所經歷的函式呼叫層次

相關主題
-
檢視文章“使用 Linux 系統呼叫的核心命令”, 瞭解系統呼叫的基本原理以及如何實現自己的系統呼叫的方法。
-
檢視文章“Linux 檔案系統剖析”,瞭解 linux 檔案系統的相關內容。
-
參看文章“Ext2 檔案系統的硬碟佈局”和書籍“ understanding the linux kernel(3rd edition)”第18章的內容,瞭解 ext2 檔案系統的相關內容。
-
檢視書籍“understanding the linux kernel(3rd edition)”第 14、15 章內容,瞭解 IO 排程演演算法、page cache 的技術等內容。
本文轉發自:https://www.ibm.com/developerworks/cn/linux/l-cn-read/
