小便邀請您,先思考:
1 正則化解決什麼問題?
2 正則化如何應用?
3 L1和L2有什麼區別?
正則化方法:防止過擬合,提高泛化能力
在訓練資料不夠多時,或者overtraining時,常常會導致overfitting(過擬合)。其直觀的表現如下圖所示,隨著訓練過程的進行,模型複雜度增加,在training data上的error漸漸減小,但是在驗證集上的error卻反而漸漸增大——因為訓練出來的網路過擬合了訓練集,對訓練集外的資料卻不work。

為了防止overfitting,可以用的方法有很多,下文就將以此展開。有一個概念需要先說明,在機器學習演演算法中,我們常常將原始資料集分為三部分:training data、validation data,testing data。這個validation data是什麼?它其實就是用來避免過擬合的,在訓練過程中,我們通常用它來確定一些超引數(比如根據validation data上的accuracy來確定early stopping的epoch大小、根據validation data確定learning rate等等)。那為啥不直接在testing data上做這些呢?因為如果在testing data做這些,那麼隨著訓練的進行,我們的網路實際上就是在一點一點地overfitting我們的testing data,導致最後得到的testing accuracy沒有任何參考意義。因此,training data的作用是計算梯度更新權重,validation data如上所述,testing data則給出一個accuracy以判斷網路的好壞。
避免過擬合的方法有很多:early stopping、資料集擴增(Data augmentation)、正則化(Regularization)包括L1、L2(L2 regularization也叫weight decay),dropout。
L2 regularization(權重衰減)
L2正則化就是在代價函式後面再加上一個正則化項:

C0代表原始的代價函式,後面那一項就是L2正則化項,它是這樣來的:所有引數w的平方的和,除以訓練集的樣本大小n。λ就是正則項繫數,權衡正則項與C0項的比重。另外還有一個繫數1/2,1/2經常會看到,主要是為了後面求導的結果方便,後面那一項求導會產生一個2,與1/2相乘剛好湊整。
L2正則化項是怎麼避免overfitting的呢?我們推導一下看看,先求導:

可以發現L2正則化項對b的更新沒有影響,但是對於w的更新有影響:
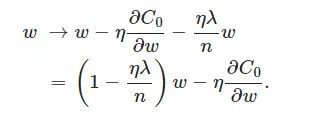
在不使用L2正則化時,求導結果中w前繫數為1,現在w前面繫數為 1−ηλ/n ,因為η、λ、n都是正的,所以 1−ηλ/n小於1,它的效果是減小w,這也就是權重衰減(weight decay)的由來。當然考慮到後面的導數項,w最終的值可能增大也可能減小。
另外,需要提一下,對於基於mini-batch的隨機梯度下降,w和b更新的公式跟上面給出的有點不同:
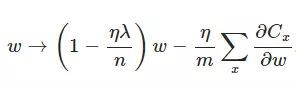

對比上面w的更新公式,可以發現後面那一項變了,變成所有導數加和,乘以η再除以m,m是一個mini-batch中樣本的個數。
到目前為止,我們只是解釋了L2正則化項有讓w“變小”的效果,但是還沒解釋為什麼w“變小”可以防止overfitting?一個所謂“顯而易見”的解釋就是:更小的權值w,從某種意義上說,表示網路的複雜度更低,對資料的擬合剛剛好(這個法則也叫做奧卡姆剃刀),而在實際應用中,也驗證了這一點,L2正則化的效果往往好於未經正則化的效果。當然,對於很多人(包括我)來說,這個解釋似乎不那麼顯而易見,所以這裡新增一個稍微數學一點的解釋(引自知乎):
過擬合的時候,擬合函式的繫數往往非常大,為什麼?如下圖所示,過擬合,就是擬合函式需要顧忌每一個點,最終形成的擬合函式波動很大。在某些很小的區間裡,函式值的變化很劇烈。這就意味著函式在某些小區間裡的導數值(絕對值)非常大,由於自變數值可大可小,所以只有繫數足夠大,才能保證導數值很大。
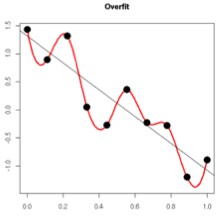
而正則化是透過約束引數的範數使其不要太大,所以可以在一定程度上減少過擬合情況。
L1 regularization
在原始的代價函式後面加上一個L1正則化項,即所有權重w的絕對值的和,乘以λ/n(這裡不像L2正則化項那樣,需要再乘以1/2,具體原因上面已經說過。)

同樣先計算導數:

上式中sgn(w)表示w的符號。那麼權重w的更新規則為:

比原始的更新規則多出了η * λ * sgn(w)/n這一項。當w為正時,更新後的w變小。當w為負時,更新後的w變大——因此它的效果就是讓w往0靠,使網路中的權重盡可能為0,也就相當於減小了網路複雜度,防止過擬合。
另外,上面沒有提到一個問題,當w為0時怎麼辦?當w等於0時,|W|是不可導的,所以我們只能按照原始的未經正則化的方法去更新w,這就相當於去掉η*λ*sgn(w)/n這一項,所以我們可以規定sgn(0)=0,這樣就把w=0的情況也統一進來了。(在程式設計的時候,令sgn(0)=0,sgn(w>0)=1,sgn(w<0)=-1)
Dropout
L1、L2正則化是透過修改代價函式來實現的,而Dropout則是透過修改神經網路本身來實現的,它是在訓練網路時用的一種技巧(trike)。它的流程如下:

假設我們要訓練上圖這個網路,在訓練開始時,我們隨機地“刪除”一半的隱層單元,視它們為不存在,得到如下的網路:
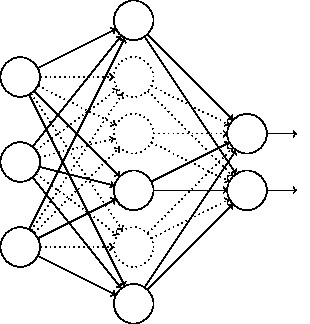
保持輸入輸出層不變,按照BP演演算法更新上圖神經網路中的權值(虛線連線的單元不更新,因為它們被“臨時刪除”了)。
以上就是一次迭代的過程,在第二次迭代中,也用同樣的方法,只不過這次刪除的那一半隱層單元,跟上一次刪除掉的肯定是不一樣的,因為我們每一次迭代都是“隨機”地去刪掉一半。第三次、第四次……都是這樣,直至訓練結束。
以上就是Dropout,它為什麼有助於防止過擬合呢?可以簡單地這樣解釋,運用了dropout的訓練過程,相當於訓練了很多個只有半數隱層單元的神經網路(後面簡稱為“半數網路”),每一個這樣的半數網路,都可以給出一個分類結果,這些結果有的是正確的,有的是錯誤的。隨著訓練的進行,大部分半數網路都可以給出正確的分類結果,那麼少數的錯誤分類結果就不會對最終結果造成大的影響。
更加深入地理解,可以看看Hinton和Alex兩牛2012的論文《ImageNet Classification with Deep Convolutional Neural Networks》
資料集擴增(data augmentation)
“有時候不是因為演演算法好贏了,而是因為擁有更多的資料才贏了。”
不記得原話是哪位大牛說的了,hinton?從中可見訓練資料有多麼重要,特別是在深度學習方法中,更多的訓練資料,意味著可以用更深的網路,訓練出更好的模型。
既然這樣,收集更多的資料不就行啦?如果能夠收集更多可以用的資料,當然好。但是很多時候,收集更多的資料意味著需要耗費更多的人力物力,有弄過人工標註的同學就知道,效率特別低,簡直是粗活。
所以,可以在原始資料上做些改動,得到更多的資料,以圖片資料集舉例,可以做各種變換,如:
-
將原始圖片旋轉一個小角度
-
新增隨機噪聲
-
一些有彈性的畸變(elastic distortions),論文《Best practices for convolutional neural networks applied to visual document analysis》對MNIST做了各種變種擴增。
-
擷取(crop)原始圖片的一部分。比如DeepID中,從一副人臉圖中,截取出了100個小patch作為訓練資料,極大地增加了資料集。感興趣的可以看《Deep learning face representation from predicting 10,000 classes》.
更多資料意味著什麼?
用50000個MNIST的樣本訓練SVM得出的accuracy94.48%,用5000個MNIST的樣本訓練NN得出accuracy為93.24%,所以更多的資料可以使演演算法表現得更好。在機器學習中,演演算法本身並不能決出勝負,不能武斷地說這些演演算法誰優誰劣,因為資料對演演算法效能的影響很大。

連結:http://blog.csdn.net/u012162613/article/details/44261657
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
