作者丨左育莘
學校丨西安電子科技大學
研究方向丨計算機視覺
之前看的文章裡有提到 GAN 在影象修複時更容易得到符合視覺上效果更好的影象,所以也是看了一些結合 GAN 的影象修複工作。
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks 發表於 ECCV 2018 的 Workshops,作者在 SRGAN 的基礎上進行了改進,包括改進網路的結構、判決器的判決形式,以及更換了一個用於計算感知域損失的預訓練網路。

超解析度生成對抗網路(SRGAN)是一項開創性的工作,能夠在單一影象超解析度中生成逼真的紋理。這項工作發表於 CVPR 2017。
但是,放大後的細節通常伴隨著令人不快的偽影。為了更進一步地提升視覺質量,作者仔細研究了 SRGAN 的三個關鍵部分:1)網路結構;2)對抗性損失;3)感知域損失。並對每一項進行改進,得到 ESRGAN。
具體而言,文章提出了一種 Residual-in-Residual Dense Block (RRDB) 的網路單元,在這個單元中,去掉了 BN(Batch Norm)層。此外,作者借鑒了 Relativistic GAN 的想法,讓判別器預測影象的真實性而不是影象“是否是 fake 影象”。
最後,文章對感知域損失進行改進,使用啟用前的特徵,這樣可以為亮度一致性和紋理恢復提供更強的監督。在這些改進的幫助下,ESRGAN 得到了更好的視覺質量以及更逼真和自然的紋理。
改進後的效果圖(4 倍放大):
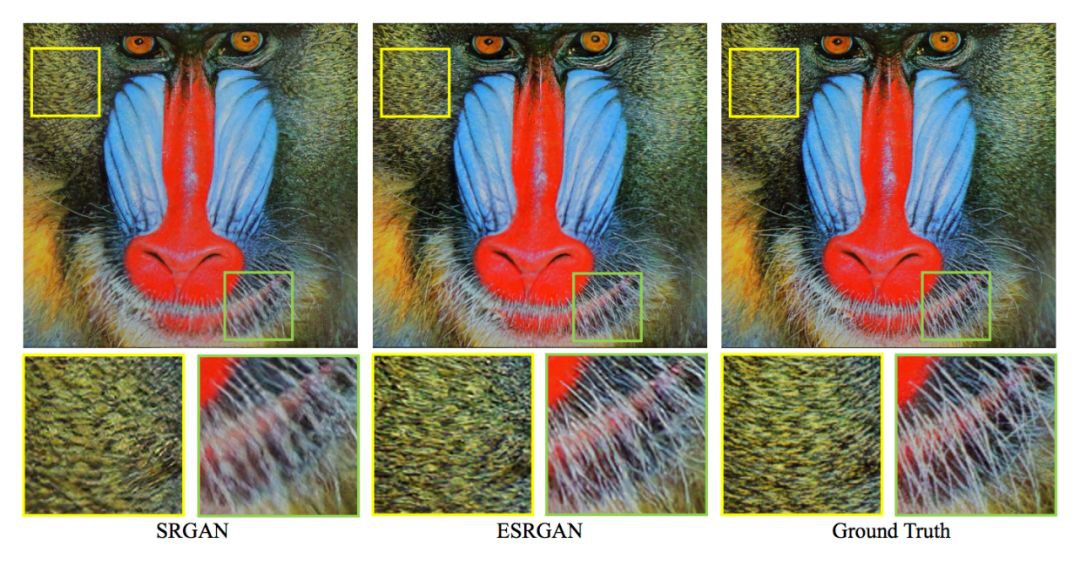
▲ 在紋理和細節上,ESRGAN都優於SRGAN
SRGAN的思考與貢獻
現有的超解析度網路在不同的網路結構設計以及訓練策略下,超分辨的效果得到了很大的提升,特別是 PSNR 指標。但是,基於 PSNR 指標的模型會傾向於生成過度平滑的結果,這些結果缺少必要的高頻資訊。PSNR 指標與人類觀察者的主觀評價從根本上就不統一。
一些基於感知域資訊驅動的方法已經提出來用於提升超解析度結果的視覺質量。例如,感知域的損失函式提出來用於在特徵空間(instead of 畫素空間)中最佳化超解析度模型;生成對抗網路透過鼓勵網路生成一些更接近於自然影象的方法來提升超解析度的質量;語意影象先驗資訊用於進一步改善恢復的紋理細節。
透過結合上面的方法,SRGAN 模型極大地提升了超解析度結果的視覺質量。但是 SRGAN 模型得到的影象和 GT 影象仍有很大的差距。
ESRGAN的改進
文章對這三點做出改進:
1. 網路的基本單元從基本的殘差單元變為 Residual-in-Residual Dense Block (RRDB);
2. GAN 網路改進為 Relativistic average GAN (RaGAN);
3. 改進感知域損失函式,使用啟用前的 VGG 特徵,這個改進會提供更尖銳的邊緣和更符合視覺的結果。
網路結構及思想
生成器部分
首先,作者參考 SRResNet 結構作為整體的網路結構,SRResNet 的基本結構如下:
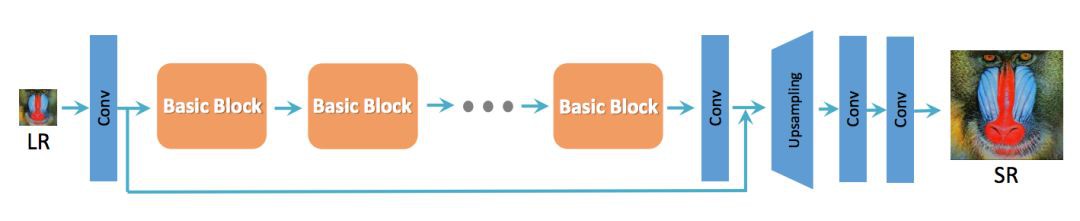
▲ SRResNet基本結構
為了提升 SRGAN 重構的影象質量,作者主要對生成器 G 做出如下改變:
1. 去掉所有的 BN 層;
2. 把原始的 block 變為 Residual-in-Residual Dense Block (RRDB),這個 block 結合了多層的殘差網路和密集連線。
如下圖所示:
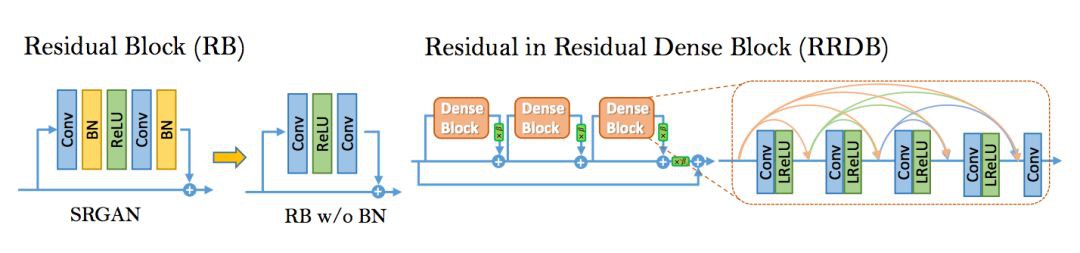
思想
BN 層的影響:對於不同的基於 PSNR 的任務(包括超解析度和去模糊)來說,去掉 BN 層已經被證明會提高表現和減小計算複雜度。
BN 層在訓練時,使用一個 batch 的資料的均值和方差對該 batch 特徵進行歸一化,在測試時,使用在整個測試集上的資料預測的均值和方差。當訓練集和測試集的統計量有很大不同的時候,BN 層就會傾向於生成不好的偽影,並且限制模型的泛化能力。
作者發現,BN 層在網路比較深,而且在 GAN 框架下進行訓練的時候,更會產生偽影。這些偽影偶爾出現在迭代和不同的設定中,違反了對訓練穩定效能的需求。所以為了穩定的訓練和一致的效能,作者去掉了 BN 層。此外,去掉 BN 層也能提高模型的泛化能力,減少計算複雜度和記憶體佔用。
Trick
除了上述的改進,作者也使用了一些技巧來訓練深層網路:
1. 對殘差資訊進行 scaling,即將殘差資訊乘以一個 0 到 1 之間的數,用於防止不穩定;
2. 更小的初始化,作者發現當初始化引數的方差變小時,殘差結構更容易進行訓練。
判別器部分
除了改進的生成器,作者也基於 Relativistic GAN 改進了判別器。判別器 D 使用的網路是 VGG 網路,SRGAN 中的判別器 D 用於估計輸入到判別器中的影象是真實且自然影象的機率,而 Relativistic 判別器則嘗試估計真實影象相對來說比 fake 影象更逼真的機率。
如下圖所示:
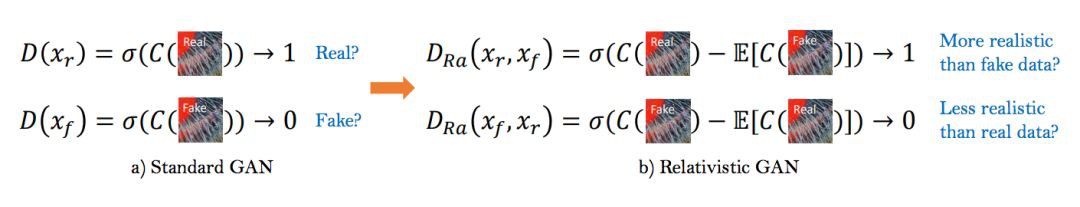
具體而言,作者把標準的判別器換成 Relativistic average Discriminator(RaD),所以判別器的損失函式定義為:
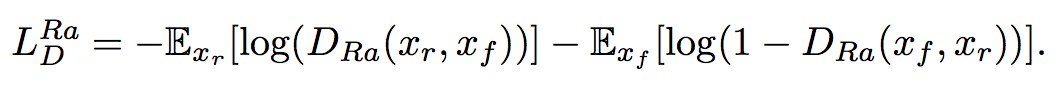
對應的生成器的對抗損失函式為:
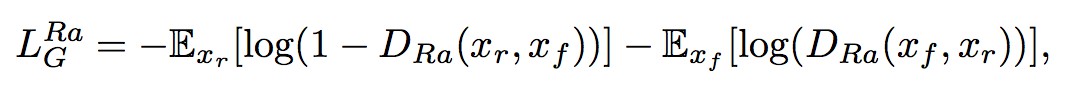
求均值的操作是透過對 mini-batch 中的所有資料求平均得到的,xf 是原始低分辨影象經過生成器以後的影象。
可以觀察到,對抗損失包含了 xr 和 xf,所以這個生成器受益於對抗訓練中的生成資料和實際資料的梯度,這種調整會使得網路學習到更尖銳的邊緣和更細節的紋理。
感知域損失
文章也提出了一個更有效的感知域損失,使用啟用前的特徵(VGG16 網路)。
感知域的損失當前是定義在一個預訓練的深度網路的啟用層,這一層中兩個激活了的特徵的距離會被最小化。
與此相反,文章使用的特徵是啟用前的特徵,這樣會剋服兩個缺點。第一,啟用後的特徵是非常稀疏的,特別是在很深的網路中。這種稀疏的啟用提供的監督效果是很弱的,會造成效能低下;第二,使用啟用後的特徵會導致重建影象與 GT 的亮度不一致。
如圖所示:
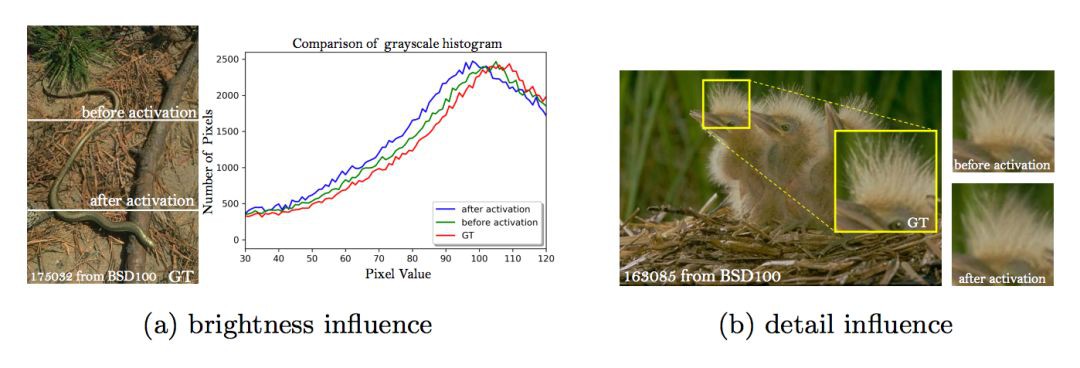
▲ 使用啟用前與啟用後的特徵的比較:a. 亮度 b. 細節
作者對使用的感知域損失進行了探索。與目前多數使用的用於影象分類的 VGG 網路構建的感知域損失相反,作者提出一種更適合於超分辨的感知域損失,這個損失基於一個用於材料識別的 VGG16 網路(MINCNet),這個網路更聚焦於紋理而不是物體。儘管這樣帶來的增益很小,但作者仍然相信,探索關註紋理的感知域損失對超分辨至關重要。
損失函式
經過上面對網路模組的定義和構建以後,再定義損失函式,就可以進行訓練了。
對於生成器 G,它的損失函式為:
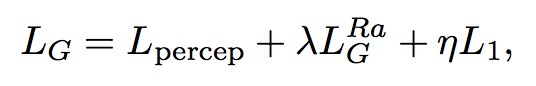
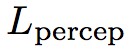 即為感知域損失,作者的原始碼取的是 L1 Loss,
即為感知域損失,作者的原始碼取的是 L1 Loss,![]() 即為上面定義的生成器損失,而 L1 則為 pixel-wise 損失,即
即為上面定義的生成器損失,而 L1 則為 pixel-wise 損失,即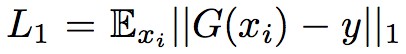 , 實驗中取
, 實驗中取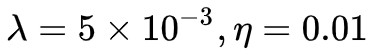 。
。
對於判別器,其損失函式就是上面提到的:
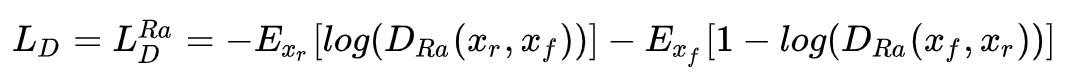
網路細節
生成器網路G
要定義 RDDB 模組,首先要定義 Dense Block,而 Dense Block 裡面又有摺積層,LReLU 層以及密集連線,所以首先將摺積層和 LReLU 層進行模組化,這部分的程式碼如下(PyTorch):
def conv_block(in_nc, out_nc, kernel_size, stride=1, dilation=1, groups=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='CNA'):
'''
Conv layer with padding, normalization, activation
mode: CNA --> Conv -> Norm -> Act
NAC --> Norm -> Act --> Conv (Identity Mappings in Deep Residual Networks, ECCV16)
'''
assert mode in ['CNA', 'NAC', 'CNAC'], 'Wong conv mode [{:s}]'.format(mode)
padding = get_valid_padding(kernel_size, dilation)
p = pad(pad_type, padding) if pad_type and pad_type != 'zero' else None
padding = padding if pad_type == 'zero' else 0
c = nn.Conv2d(in_nc, out_nc, kernel_size=kernel_size, stride=stride, padding=padding, \
dilation=dilation, bias=bias, groups=groups)
a = act(act_type) if act_type else None
if 'CNA' in mode:
n = norm(norm_type, out_nc) if norm_type else None
return sequential(p, c, n, a)
elif mode == 'NAC':
if norm_type is None and act_type is not None:
a = act(act_type, inplace=False)
# Important!
# input----ReLU(inplace)----Conv--+----output
# |________________________|
# inplace ReLU will modify the input, therefore wrong output
n = norm(norm_type, in_nc) if norm_type else None
return sequential(n, a, p, c)
註意這裡的 pad_type=’zero’ 並不是指 padding=0,原始碼中定義了兩個函式,針對不同樣式下的 padding:
def pad(pad_type, padding):
# helper selecting padding layer
# if padding is 'zero', do by conv layers
pad_type = pad_type.lower()
if padding == 0:
return None
if pad_type == 'reflect':
layer = nn.ReflectionPad2d(padding)
elif pad_type == 'replicate':
layer = nn.ReplicationPad2d(padding)
else:
raise NotImplementedError('padding layer [{:s}] is not implemented'.format(pad_type))
return layer
def get_valid_padding(kernel_size, dilation):
kernel_size = kernel_size + (kernel_size - 1) * (dilation - 1)
padding = (kernel_size - 1) // 2
return padding
所以當 pad_type=’zero’ 時,執行的是 get_valid_padding 函式,根據輸入引數可知此時 padding=1。
模組化以後,對 Dense Block 進行定義:
class ResidualDenseBlock_5C(nn.Module):
'''
Residual Dense Block
style: 5 convs
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
'''
norm_type=None, act_type=‘leakyrelu’, mode=‘CNA’):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv2 = conv_block(nc+gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv3 = conv_block(nc+2*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv4 = conv_block(nc+3*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
if mode == ‘CNA’:
last_act = None
else:
last_act = act_type
self.conv5 = conv_block(nc+4*gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=last_act, mode=mode)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(torch.cat((x, x1), 1))
x3 = self.conv3(torch.cat((x, x1, x2), 1))
x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
return x5.mul(0.2) + x
前面提到的對殘差資訊進行 scaling,在這裡可以看出來,繫數為 0.2。可以看到在 kernel size(3×3)和 stride=1,padding=1 的設定下,特徵圖的大小始終不變,但是通道數由於 concat 的原因,每次都會增加 gc 個通道,但是會在最後一層由變回原來的通道數 nc,這裡的引數 norm_type=None,表示不要 Batch Norm。
定義了 Dense Block 以後,就可以組成 RDDB 了:
class RRDB(nn.Module):
'''
Residual in Residual Dense Block
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)
'''
norm_type=None, act_type=‘leakyrelu’, mode=‘CNA’):
super(RRDB, self).__init__()
self.RDB1 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB2 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB3 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
out = self.RDB3(out)
return out.mul(0.2) + x
因為特徵圖大小始終不變,所以需要定義上取樣模組進行放大,得到最後的結果:
def upconv_blcok(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='nearest'):
# Up conv
# described in https://distill.pub/2016/deconv-checkerboard/
upsample = nn.Upsample(scale_factor=upscale_factor, mode=mode)
conv = conv_block(in_nc, out_nc, kernel_size, stride, bias=bias, \
pad_type=pad_type, norm_type=norm_type, act_type=act_type)
return sequential(upsample, conv)
參考 SRResNet,還需要一個 Shortcut 連線模組:
class ShortcutBlock(nn.Module):
#Elementwise sum the output of a submodule to its input
def __init__(self, submodule):
super(ShortcutBlock, self).__init__()
self.sub = submodule
output = x + self.sub(x)
return output
def __repr__(self):
tmpstr = 'Identity + \n|'
modstr = self.sub.__repr__().replace('\n', '\n|')
tmpstr = tmpstr + modstr
return tmpstr
定義好上面的模組以後,就可以定義生成器網路 G(RDDBNet):
class RRDBNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, gc=32, upscale=4, norm_type=None, \
act_type='leakyrelu', mode='CNA', upsample_mode='upconv'):
super(RRDBNet, self).__init__()
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
rb_blocks = [B.RRDB(nf, kernel_size=3, gc=32, stride=1, bias=True, pad_type=‘zero’, \
norm_type=norm_type, act_type=act_type, mode=‘CNA’) for _ in range(nb)]
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
upsample_block = B.upconv_blcok
elif upsample_mode == ‘pixelshuffle’:
upsample_block = B.pixelshuffle_block
else:
raise NotImplementedError(‘upsample mode [{:s}] is not found’.format(upsample_mode))
if upscale == 3:
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
else:
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
*upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
註意到這裡有個引數 nb,這個引數控制網路中 RDDB 的數量,作者取的是 23。
判別器網路D
前面提到,判別器 D 的網路結構為 VGG 網路,定義如下(輸入影象 size 為 128×128):
# VGG style Discriminator with input size 128*128
class Discriminator_VGG_128(nn.Module):
def __init__(self, in_nc, base_nf, norm_type='batch', act_type='leakyrelu', mode='CNA'):
super(Discriminator_VGG_128, self).__init__()
# features
# hxw, c
# 128, 64
conv0 = B.conv_block(in_nc, base_nf, kernel_size=3, norm_type=None, act_type=act_type, \
mode=mode)
conv1 = B.conv_block(base_nf, base_nf, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 64, 64
conv2 = B.conv_block(base_nf, base_nf*2, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv3 = B.conv_block(base_nf*2, base_nf*2, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 32, 128
conv4 = B.conv_block(base_nf*2, base_nf*4, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv5 = B.conv_block(base_nf*4, base_nf*4, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 16, 256
conv6 = B.conv_block(base_nf*4, base_nf*8, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv7 = B.conv_block(base_nf*8, base_nf*8, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 8, 512
conv8 = B.conv_block(base_nf*8, base_nf*8, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv9 = B.conv_block(base_nf*8, base_nf*8, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 4, 512
self.features = B.sequential(conv0, conv1, conv2, conv3, conv4, conv5, conv6, conv7, conv8,\
conv9)
self.classifier = nn.Sequential(
nn.Linear(512 * 4 * 4, 100), nn.LeakyReLU(0.2, True), nn.Linear(100, 1))
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
可以看到,這裡使用了 batch norm,層間的啟用函式為 leakyReLU,base_nf引數為基礎通道數,為 64。經過特徵提取以後,原本為 128×128×1(/3) 的輸入影象輸出為 4×4×512。再經過其定義的 classifier 得到輸出值。
提取感知域損失的網路(Perceptual Network)
文章使用了一個用於材料識別的 VGG16 網路(MINCNet)來提取感知域特徵,定義如下:
class MINCNet(nn.Module):
def __init__(self):
super(MINCNet, self).__init__()
self.ReLU = nn.ReLU(True)
self.conv11 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv12 = nn.Conv2d(64, 64, 3, 1, 1)
self.maxpool1 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv21 = nn.Conv2d(64, 128, 3, 1, 1)
self.conv22 = nn.Conv2d(128, 128, 3, 1, 1)
self.maxpool2 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv31 = nn.Conv2d(128, 256, 3, 1, 1)
self.conv32 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv33 = nn.Conv2d(256, 256, 3, 1, 1)
self.maxpool3 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv41 = nn.Conv2d(256, 512, 3, 1, 1)
self.conv42 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv43 = nn.Conv2d(512, 512, 3, 1, 1)
self.maxpool4 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv51 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv52 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv53 = nn.Conv2d(512, 512, 3, 1, 1)
def forward(self, x):
out = self.ReLU(self.conv11(x))
out = self.ReLU(self.conv12(out))
out = self.maxpool1(out)
out = self.ReLU(self.conv21(out))
out = self.ReLU(self.conv22(out))
out = self.maxpool2(out)
out = self.ReLU(self.conv31(out))
out = self.ReLU(self.conv32(out))
out = self.ReLU(self.conv33(out))
out = self.maxpool3(out)
out = self.ReLU(self.conv41(out))
out = self.ReLU(self.conv42(out))
out = self.ReLU(self.conv43(out))
out = self.maxpool4(out)
out = self.ReLU(self.conv51(out))
out = self.ReLU(self.conv52(out))
out = self.conv53(out)
return out
再引入預訓練引數,就可以進行特徵提取:
class MINCFeatureExtractor(nn.Module):
def __init__(self, feature_layer=34, use_bn=False, use_input_norm=True, \
device=torch.device('cpu')):
super(MINCFeatureExtractor, self).__init__()
self.features.load_state_dict(
torch.load(‘../experiments/pretrained_models/VGG16minc_53.pth’), strict=True)
self.features.eval()
# No need to BP to variable
for k, v in self.features.named_parameters():
v.requires_grad = False
def forward(self, x):
output = self.features(x)
return output
網路插值思想
為了平衡感知質量和 PSNR 等評價值,作者提出了一個靈活且有效的方法——網路插值。具體而言,作者首先基於 PSNR 方法訓練的得到的網路 G_PSNR,然後再用基於 GAN 的網路 G_GAN 進行 finetune。
然後,對這兩個網路相應的網路引數進行插值得到一個插值後的網路 G_INTERP:
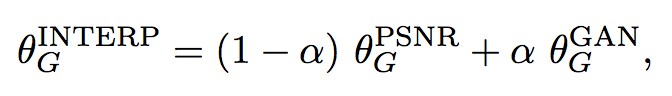
這樣就可以透過 α 值來調整效果。
訓練細節
放大倍數:4;mini-batch:16。
透過 Matlab 的 bicubic 函式對 HR 影象進行降取樣得到 LR 影象。
HR patch 大小:128×128。實驗發現使用大的 patch 時,訓練一個深層網路效果會更好,因為一個增大的感受域會幫助模型捕捉更具有語意的資訊。
訓練過程如下:
1. 訓練一個基於 PSNR 指標的模型(L1 Loss),初始化學習率:2×1e-4,每 200000 個 mini-batch 學習率除以 2;
2. 以 1 中訓練的模型作為生成器的初始化。
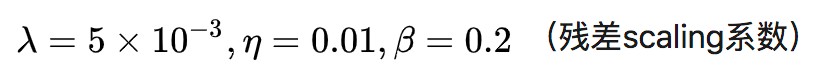
初始學習率:1e-4,併在 50k,100k,200k,300k 迭代後減半。
一個基於畫素損失函式進行最佳化的預訓練模型會幫助基於 GAN 的模型生成更符合視覺的結果,原因如下:
1. 可以避免生成器不希望的區域性最優;
2. 再預訓練以後,判別器所得到的輸入影象的質量是相對較好的,而不是完全初始化的影象,這樣會使判別器更關註到紋理的判別。
最佳化器:Adam (β1=0.9, β2=0.999);交替更新生成器和判別器,直到收斂。
生成器的設定:1.16 層(基本的殘差結構);2.23層(RDDB)。
資料集:DIV2K,Flickr2K,OST(有豐富紋理資訊的資料集會是模型產生更自然的結果)。
對比實驗(4倍放大)
針對文中提到的各種改進,包括移除 BN,使用啟用前特徵作為感知域特徵,修改 GAN 的判別條件,以及提出的 RDDB,作者做了詳細的對比試驗,結果如下:

經過實驗以後,作者得出結論:
1. 去掉 BN:並沒有降低網路的效能,而且節省了計算資源和記憶體佔用。而且發現當網路變深變複雜時,帶 BN 層的模型更傾向於產生影響視覺效果的偽影;
2. 使用啟用前的特徵:得到的影象的亮度更準確,而且可以產生更尖銳的邊緣和更豐富的細節;
3. RaGAN:產生更尖銳的邊緣和更豐富的細節;
4. RDDB:更加提升恢復得到的紋理(因為深度模型具有強大的表示能力來捕獲語意資訊),而且可以去除噪聲。
網路插值實驗
為了平衡視覺效果和 PSNR 等效能指標,作者對網路插值引數 α 的取值進行了實驗,結果如下:

此外,作者還對比了網路插值和影象插值的效果。影象插值即指分別由兩個網路輸出的影象進行插值。透過對比實驗可以看到,影象插值對消除偽影的效果不如網路插值。
與SOTA方法對比(4倍放大)

可以看到,ESRGAN 得到的影象 PSNR 值不高,但是從視覺效果上看會更好,Percpetual Index 值更小(越小越好),而且 ESRGAN 在 PIRM-SR 競賽上也獲得了第一名(在 Percpetual Index 指標上)。
總結
文章提出的 ESRGAN 在 SRGAN 的基礎上做出了改進,包括去除 BN 層,基本結構換成 RDDB,改進 GAN 中判別器的判別標的,以及使用啟用前的特徵構成感知域損失函式,實驗證明這些改進對提升輸出影象的視覺效果都有作用。
此外,作者也使用了一些技巧來提升網路的效能,包括對殘差資訊的 scaling,以及更小的初始化。最後,作者使用了一種網路插值的方法來平衡輸出影象的視覺效果和 PSNR 等指標值。