

清華大學計算機系副教授裴丹於運維自動化專場發表了題為《基於機器學習的智慧運維》的演講,上篇參看“科研角度談“如何實現基於機器學習的智慧運維”文章,此為下篇。從百度運維實踐談基於機器學習的智慧運維。以下為演講實錄,內容包括基於機器學習的智慧運維的案例、挑戰和思路。下麵先講一下實際的三個百度案例。

第一個場景,橫軸是時間,縱軸是百度的搜尋流量,大概是一天幾億條的級別,隨著時間的變化,每天早上到中午上升,到下午到晚上下去,我們要在這個曲線裡面找到它的異常點,要在這樣一個本身就在變化的曲線裡面,能夠自動化的找到它的坑,並且進行告警。那麼多演演算法,如何挑選演演算法?如何把閾值自動設出來?這是第一個場景。
第二個場景,我們要秒級。對於搜尋引擎來說,就是要1秒的指標,這個時候有30%超過1秒,我們的標的是要降到20%及以下,如何找到具體的最佳化方法把它降下來?我們有很多最佳化工具,但是不知道到底用哪個,因為資料太複雜了,這是第二個應用場景。
第三個場景,自動關聯KPI異常與版本上線。上線的過程中,隨時都有可能發生問題,發生問題的時候,如何迅速判斷出來是你這次上線導致發生的問題?有可能是你上線導致的,也有可能不是,那麼多因素,剛才說了幾十萬臺機器,你怎麼判斷出來?這是百度實際搜尋廣告的收入,我們看到有一個上線事件,收入在上線之後掉下來了。
下麵這個是我們一個學生在百度實習的時候做出來的一個方案,基於機器學習的KPI自動化異常檢測。

橫軸是時間,縱軸是流量,要找到異常。我們要迅速識別出來,並且準確識別出來,幫助我們迅速進行診斷和修複,進一步阻止潛在風險。
我們學術界,包括其他的領域,包括股票市場,已經研究幾十年了,如何根據持續的曲線預測到下一個值是多少?有很多演演算法。我們的運維人員,就是我們的領域專家,會對自己檢測的KPI進行負責,但是我們有海量的資料,這KPI又是千變萬化各種各樣的,三個曲線就很不一樣,如何在這些具體的KPI曲線裡取得良好的匹配?這是非常難的一件事情。

我們看看為什麼是這樣的?有一個運維人員負責檢測這樣的曲線,假如說要試用一下演演算法,學術界的常規演演算法,要跟演演算法開發人員進行一些描述。演演算法開發人員說,你看我這兒有三個引數,把你的異常按照我的三個引數描述一下,運維人員肯定不乾這個事情。開發人員還不瞭解KPI的專業知識,就想差不多做一做吧,做完了之後說你看看效果怎麼樣?往往效果差強人意,再來迭代一下,可能幾個月就過去了。

運維人員難以事先給出準確、量化的異常定義;對於開發人員來說,選擇和綜合不同的檢測器需要很多人力;檢測器演演算法複雜,引數調節不直觀,這些都是存在的問題。
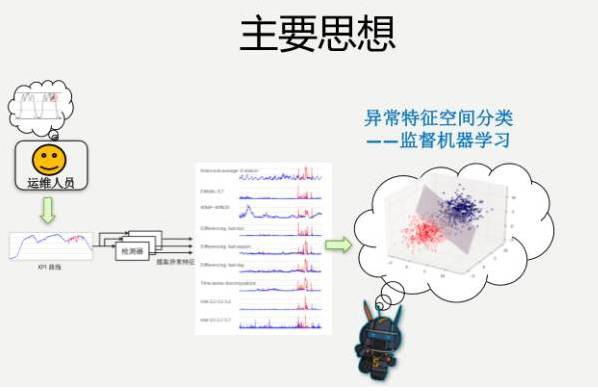
所以我們方法的主要思想是,做一個機器學習的工具。我們跟著運維人員學,做一個案例學一個,把他的知識學下來,不需要挑具體的檢測演演算法,把這個事情做出來,根據歷史的資料以及它的異常學到這個東西。
運維人員需要做什麼事情?我看著這些KPI的曲線,這段是異常,標註出來,就有了標註資料。本身就是有特徵資料的,提供一下,說你這個小徒弟,你要想把它做好,我有一個要求,準確率要超過80%,小徒弟就拼命的跟師傅學。

具體做的時候,比如說KPI的具體曲線,假如說這裡有一個異常點,我們把能拿到的理論界上,學術界上的各種演演算法都已經實現了,它還有各種引數,把引數空間掃一遍,大概100多種,用集體的智慧把KPI到底是不是異常,透過跟運維人員去學,把這個學出來。
為什麼能夠工作?就是因為它的基本工作原理,就是我會學歷史資訊,學到了之後生成一些訊號,對於同樣的異常會有預測值,紅色是檢測出來的訊號。檢測出來的訊號略有不同,但是我們覺得集體的智慧,能夠最後給出一個非常好的效果,這就是一個基本的思路。

如何把它轉化成機器學習的問題?我們有特徵資料、有標註,想要的就是它是異常還是非異常,就是一個簡單的監督機器學習分類的問題。運維人員進行標註,產生各種特徵資料,這就是剛才100多種檢測器給出的特徵資料,然後進行分類,效果還是比較理想的。
但是,還是有很多實際的挑戰,我們簡單提一個挑戰。第一個挑戰,我們運維人員需要標註,我得花多長時間去標註?在實際運維過程中,那些真正的異常並沒有那麼多,本身數量相對比較少。如果能做出一些比較高效的標記工具,是能夠很好的幫助我們的。
如果把這個標註工具像做一個網際網路產品一樣,做得非常好,能夠節省標註人員很多的時間。我們做了很多工作,滑鼠加鍵盤,瀏覽同比、環比的資料,上面有放大縮小,想標註一個資料,拿著滑鼠拖一下就OK了。一個月裡面的異常資料,最後由運維人員實際進行標註,大概一個月也就花五六分鐘的時間,就搞定了。

還有很多其他的挑戰,比如說歷史資料中異常種類比較少,類別不均衡問題,還有冗餘和無關特徵等。

下麵是一個整體的設計。那麼,拿實際運維的資料進行檢測的時候效果怎麼樣呢?

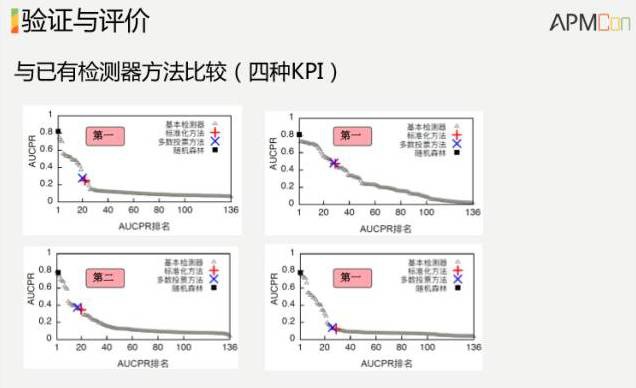
這裡拿了四組資料,三組是百度的,一組是清華校園網的。一般的操作,分別對這些資料配一組閾值。我們不管這個資料是什麼樣的,就是用一種演演算法把它搞定,就拿剛才給出的運維小徒弟這樣的演演算法,把100多種其他的演演算法都跑了一遍,比較了一下,在四組資料裡面,我們演演算法的準確率不是第一就是第二,而且我們的好處是不用調引數。超過我們這個演演算法,普通的可能要把100多種試一下,我們這個不用試,直接就出來。
為了讓運維更高效,可以讓告警工作更智慧,無需人工選擇繁雜的檢測器,無需調參,把它做得像一個網際網路產品一樣好。這是第一個案例,關於智慧告警的。理論上學術界有很多漂亮的演演算法,如何在實際中落地的問題,在這個過程中我們使用的是機器學習的方案。我們看一下第二個案例,剛才說的秒級。先看一個概念,搜尋響應時間。

搜尋響應時間,這個就是首屏時間了。對於綜合搜尋來說,使用者在瀏覽器上輸入一個關鍵字,點一下按紐,直到首屏搜尋結果傳回來,當然這裡面有一些過程。
這個為什麼很重要?這就是錢。對於亞馬遜來說,如果響應時間增加100毫秒,銷量降低1%。對於谷歌來說,每增加100毫秒到400毫秒搜尋,使用者數就會下降0.2%到0.6%,所以非常重要。
看一下在實際中搜索響應時間是什麼樣的?橫軸是搜尋響應時間,縱軸是CDF。70%的搜尋響應時間是低於1秒,是符合要求的。30%的時間是高於1秒的,是不達標的。那怎麼辦呢?大於1秒的搜尋原因到底是什麼?如何改進?這裡面也是一個機器學習的問題。各種日誌非常多,答案就藏在日誌裡面,問題是如何拿到日誌分析出來。我們看一下日誌的形式:

對於使用者每一次搜尋,都有他來自於哪個運營商,瀏覽器內核是什麼,傳回結果裡面圖片有多少,傳回結果有沒有廣告,後臺負載如何等資訊。這次響應,它的響應時間是多少,大於1秒就是不理想,小於1秒就是比較理想,我們有足夠多的資料,一天上億,還有標註,這個標註比較簡單了。
我們現在來回答幾個問題,在這麼多維度的資料裡邊,如何找出它響應時間比較高的時候,高響應時間容易發生的條件是什麼?哪些HSRT條件比較流行?如果找出流行的條件,我們就找到了一些線索,就知道如何去最佳化。我們能不能在實際最佳化之前,事先看一下,有可能最佳化的結果是什麼?基本上想做的就是這麼一個事情。這裡面有些細節我們就跳過,想表達的意思是說對於多維度資料,如果只看單維度的資料,會有各種各樣的問題。
在分析多維屬性搜尋日誌的時候也會有很多挑戰
-
第一,單維度屬性分析方法無法揭示不同條件屬性的組合帶來的影響。
-
第二,屬性之間還存在著潛在的依賴關係,所以單維度分析的結論可能是片面的。
-
第三,得到的HSRT條件可重疊,每次HSRT被計算多次,不易理解。你如果單維度看,圖片數量大於30%,貢獻了50%的響應時間,看一下其他的維度,加起來發現120%,這都是單維度看存在的問題。
因為每個維度有各種各樣的取值,一旦組合,空間就爆炸了,人是不可能做的,就算是做了視覺化的工具,人是不可能一個個試來得出結論,必須靠機器學習的方法,所以我們把這個問題建模成分類問題,利用監督機器學習演演算法,決策樹得到直觀分類模型。
下麵這個是我們當時設計的一個架構圖,每天日誌來了之後,輸入到機器學習決策樹的模型裡面,分析出每天高響應時間的條件,跨天進行分析,之後再去做一些準實驗,最後得出一些結果。

下麵這個是我們第一步完成了之後,得出的一個決策樹,生成決策樹的過程,基本上拿一些現成的工具,把資料導進去,調一些引數就可以了。
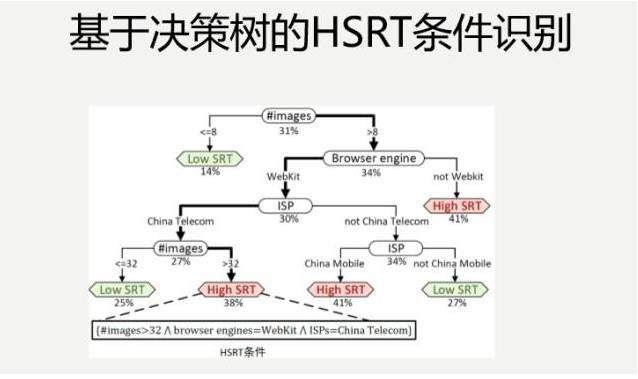
我們會看一個月的時間內,每天都獲得的資料,我們得出一個月裡面,哪些條件比較流行,然後,在此基礎上,做一些準實驗。不是說分析出來了之後,就真的上線調這些最佳化條件,比如說得出這樣的組合,當圖片數量大於10,它的瀏覽器引擎不是WebKit,裡面沒有打廣告,它會容易響應時間比較高。
給了我們一些啟示,具體哪個條件導致的?最佳化哪個維度會產生比較好的結果?這不知道。我如果把每個條件調一下,這個大於10,變成小於10,這個條件的組合,在實際的日誌資料裡面就是存在的,把這個資料取出來,看一下它的響應延遲到底是高還是低,這就是準實驗,諸如此類都做一些,很容易得出一些結論。
我們針對當時的場景,圖片數量過多是導致響應時間比較長的主要瓶頸,是當時最重要的瓶頸,具體對這個進行了最佳化,大家可能就比較熟悉了,部署了base64 encoding來提高“數量多、體積小”的圖片傳輸速度。
這裡想強調一點,這個最佳化方式,大家都知道,但是在沒有這樣分析的情況下,你並沒有把握上線之後,就有效果。假如說你運維部門的KPI指標,超過20%就不達標,如果低於20%就達標了,上線這一個就達標了。各種比較都很清晰,就是這樣的一個工具,有很多日誌,你做一些基於機器學習的分析,找到目前最重要的瓶頸,把這些瓶頸跟拿到手的各種最佳化的方式方法,應用一下,就能得到很好的效果,這個效果是很不錯的,通用性也比較高。
第三個案例跳過去吧,大概意思是說自動更新會產生很多問題,我簡單直接把案例給出來就好了。
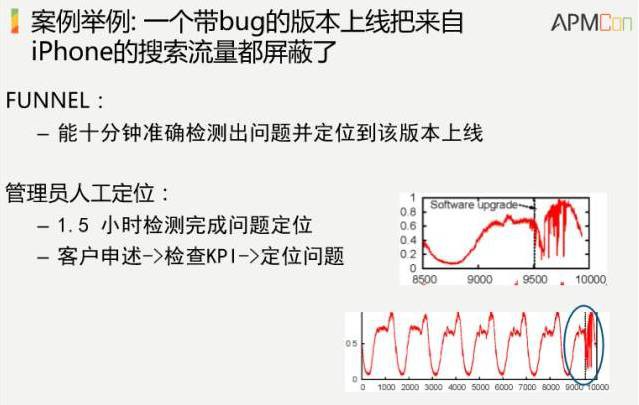
最後給出一個案例,這個案例就是說百度上線了一個反點選作弊的版本,上線之後,廣告收入就出現了下降,實際上用我們這個系統做了一下,10分鐘能夠準確檢測出問題。而人在具體做的時候,要客戶申述、檢查KPI、定位問題,要一個半小時,差異還是很大的。
剛才舉了幾個具體的案例,其實還有其他的很多案例,如異常檢測之後的故障定位、故障止損建議、故障根因分析、資料中心交換機故障預測、海量Syslog日誌壓縮成少量有意義的事件、基於機器學習的系統最佳化(如TCP執行引數)。

我們在學術界來說,我們也不做產品,我們是針對一線生產環境中遇到的各種有挑戰性的問題,做一些具體的演演算法。我們的標的就是做一些智慧運維演演算法的集合,執行在雲上面,它會有一些標準的API。標準的API支援任意時序資料,它有一個時間戳,有一個關鍵指標,這個關鍵指標針對不同場景會不一樣,有銷售額、利潤、訂單數、轉化率等等不同屬性,經過這樣的分析之後,跑到雲裡面,就能得出一些通用性的結果。
這裡我想給大家一些具體的啟示,包括我們自己的一些思考。智慧運維到底有哪些可行的標的?我們的步子不能邁得太大,又不能太保守,我們到底想達到什麼樣的效果?誰拿著槍,誰就處於主導地位。像R2-D2是運維人員的可靠助手,最後還是人來起主導作用。
1、很重要的就取決於人工智慧本身發展到哪個地步,人工智慧解決了一些問題,知其然,又知其所以然。知其然,不知其所以然,這個其我知道它下的好,但是為什麼好,計算機算出來的,我並不知道。人工智慧發展到現在的階段,比較可靠的是這個地步:知其然,而不知其所以然,技術方面,透過機器學習相對成熟,在一定條件下比人好。到後面既不知其然,又不知其所以然,以及連問題都不知道,人工智慧還沒有到那個地步。我們要自動化那些“知其然而不知其所以然”的運維任務。
2、如何更系統的應用機器學習技術。機器學習紛繁複雜,簡單說一下。特徵選取的時候,早期可以用一些全部資料 容忍度高的演演算法,如隨機森林,還有特徵工程、自動選取(深度學習);不同機器學習演演算法適用不同的問題;一個比較行之有效的方法,大家做日常運維過程中,可以跟學術界進行具體探討,針對眼前問題一起探討一下,可能比較容易找到適合的起點。工業界跟學術界針對具體問題進行密切合作是一個有效的策略。
3、如何從現有ticket資料中提取有價值資訊。我們可以把ticketing系統作為智慧運維的一部分來設計。
4、如何把智慧運維延伸到智慧運營?我們有各種各樣的資料,資料都在那兒,企業的痛點是,光有海量資料,缺乏真正精準的運營和行動之間有效轉化的工具。其實我們思考一下,我們看的那些KPI,如果抽象成時序資料,跟電商的銷售資料,跟遊戲的KPI指標沒有本質的區別。如果抽象成演演算法層面,可能都有很好的應用場景,具體還會有一些額外的挑戰,但是如果在演演算法層面進行更多投入,可以跳出運維本身到智慧運營這塊。
總結一下今天的內容,基於機器學習的智慧運維,在今後幾年會有飛速的發展,因為它有得天獨厚的資料、標註和應用。智慧運維的終極可行標的,是運維人員高效可靠的助手。智慧運維能夠更系統應用機器學習技術,學術界和工業界應能夠在一些具體問題上密切合作。更系統的資料採集和標註會幫助智慧運維更快發展。下一步把智慧運維的技術延伸到智慧運營裡面。
相關閱讀
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多技術資料。

求知若渴, 虛心若愚—Stay hungry, Stay foolish

