

記得關註+轉發喲

開發語言:Python2.7
開發環境:64位Windows8系統,4G記憶體,i7-3612QM處理器。
資料庫:MongoDB 3.2.0
(Python編輯器:Pycharm 5.0.4;MongoDB管理工具:MongoBooster 1.1.1)
多執行緒使用 multiprocessing.dummy 。
抓取 Cookie 使用 selenium 和 PhantomJS 。
判重使用 BitVector 。
啟動前配置:
MongoDB安裝好 能啟動即可,不需要配置。
Python需要安裝以下模組(註意官方提供的模組是針對win32系統的,64位系統使用者在使用某些模組的時候可能會出現問題,所以儘量先找64位模組,如果沒有64的話再去安裝32的資源):
requests、BeautifulSoup、multiprocessing、selenium、itertools、BitVector、pymongo

啟動程式:
-
進入 myQQ.txt 寫入QQ賬號和密碼(用一個空格隔開,不同QQ換行輸入),一般你開啟幾個QQ爬蟲執行緒,就至少需要兩倍數量的QQ用來登入,至少要輪著登入嘛。
-
進入 init_messages.py 進行爬蟲引數的配置,例如執行緒數量的多少、設定爬哪個時間段的日誌,哪個時間段的說說,爬多少個說說備份一次等等。
-
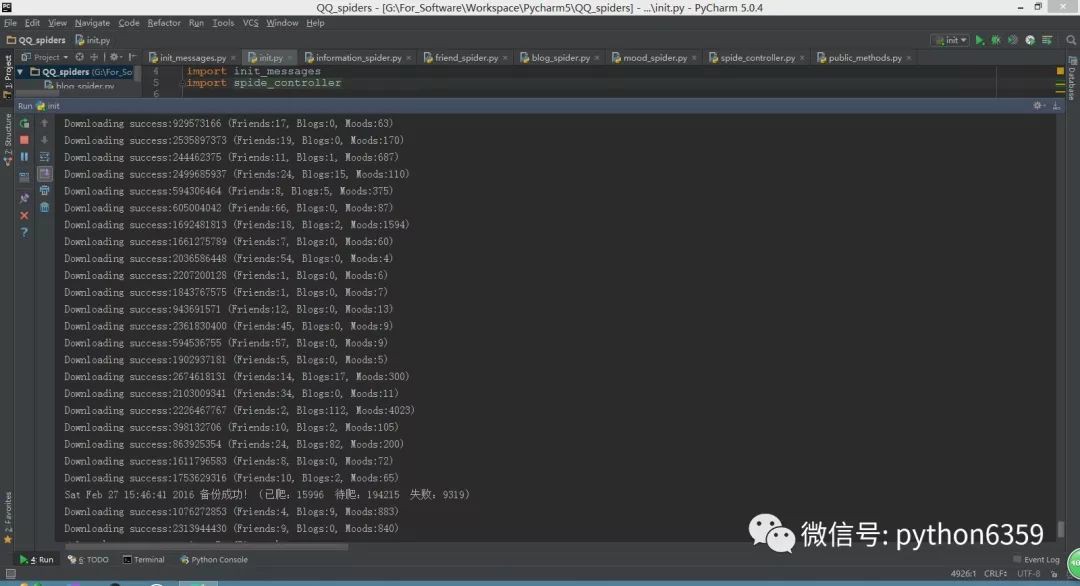
執行 init.py 檔案開啟爬蟲專案。
-
爬蟲開始之後首先根據 myQQ.txt 裡面的QQ去獲取 Cookie(以後登入的時候直接用已有的Cookie,就不需要每次都去拿Cookie了,遇到Cookie失效也會自動作相應的處理)。獲取完Cookie後爬蟲程式會去申請四百多兆的記憶體,申請的時候會佔用兩G左右的記憶體,大約五秒能完成申請,之後會掉回四百多M。
-
爬蟲程式可以中途停止,下次可開啟繼續抓取。



?按住圖片左右滑動
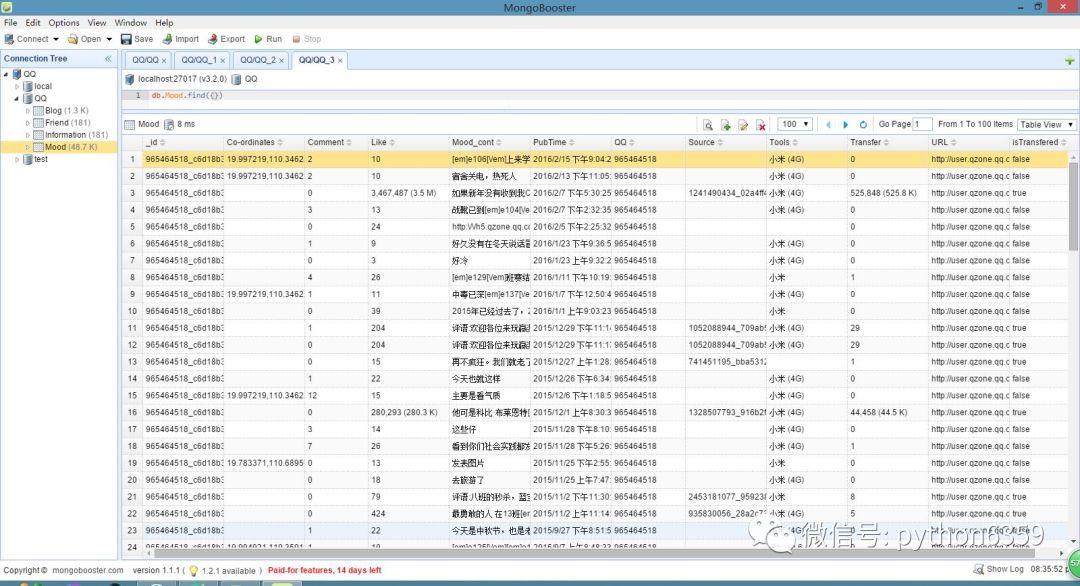
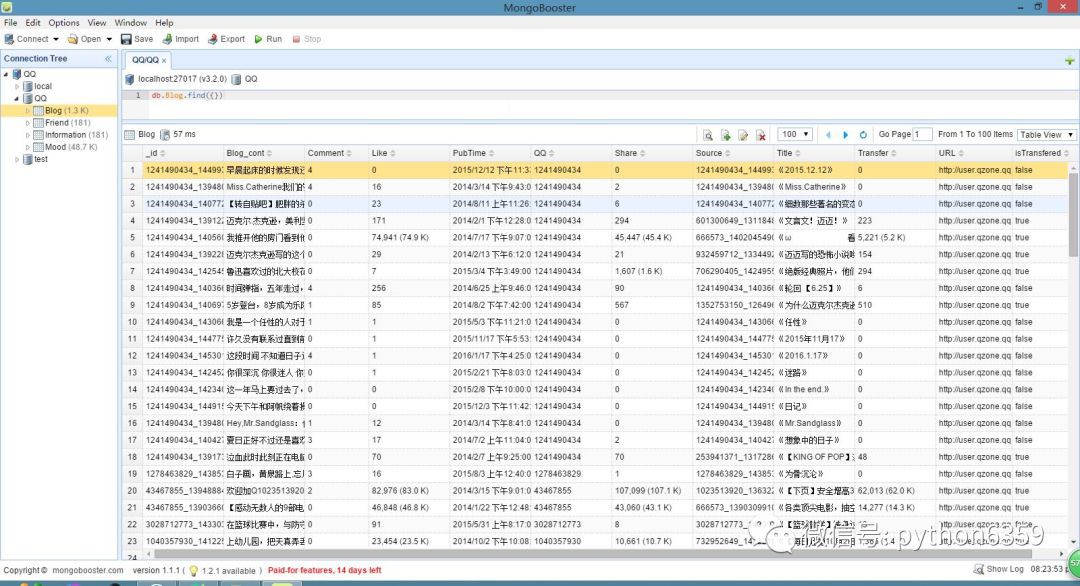
資料庫說明


