

濃縮乾貨:MPI-IO對單個行程使用“資料篩選”技術最佳化,對聚合IO使用“兩階段IO”技術最佳化。並行儲存系統的檔案條塊長度與嚴重影響效能。
1997年,MPI 2.0標準添加了並行IO功能,介面函式增加了一堆。但是MPICH、OpenMPI軟體包的檔案、MPI教科書裡只講各種函式的用法,不提這些並行IO函式是如何提高效能的,讓人一邊寫程式碼一邊懷疑它們的實際效果。想知道背後的最佳化原理,就要先瞭解一它的應用場景。
MPI程式讀寫檔案的樣式
只用1個行程讀寫:如圖1,行程p0將檔案中的所有資料讀入自己的緩衝區(buffer),然後用MPI傳送接收函式將大部分資料傳給行程p1~p3。計算結束後,如圖2,行程p1~p3將計算結果傳給行程p0,p0負責將所有結果資料寫到檔案。
顯然,這個樣式下負責讀寫檔案的行程是效能瓶頸,讀寫頻寬受限於p0所在計算伺服器的網路頻寬、儲存系統的單行程效能上限。即使採用並行儲存系統,也無法改善IO效能。
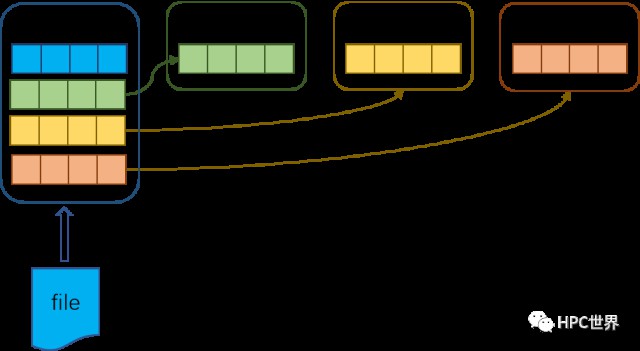
圖 1

圖 2
多個行程分別讀寫:每個行程只操作自己的檔案,彼此間不協調,相互獨立,如圖3。這種樣式既能同時使用計算伺服器的多個網路通道,又能發揮並行儲存系統的多客戶端接入能力。缺點是供讀取的源資料檔案可能沒有行程數量多(大型程式會用成千上萬、百萬的行程),造成負載不均;輸出的檔案資料太多,後續處理困難。

圖 3
多個行程讀寫同一個檔案:多個行程相互配合,避免無用操作,如圖4。這種樣式下MPI並行IO效能有望達到最好。

圖 4
最佳化技術:資料篩選(Data Sieving)
在“多行程讀寫同一個檔案”樣式下,假設4個行程分工處理一個大陣列A,如圖5。根據邊界最小原則劃分,每個行程負責一個角上的資料。

圖 5
假設陣列A及其子陣列在檔案中和記憶體中均按行存放(C語言樣式),那麼4個行程記憶體中的子陣列擺放形式就如圖6所示。
特別註意,作業系統普遍的支援的POSIX協議只允許讀寫連續的資料段,不能1次讀寫有“空洞”的資料段。仔細找找,C語言、Fortran語言的檔案操作函式中沒有讀寫不連線資料的函式吧。

圖 6
那麼問題來了,對行程p0而言,記憶體中連續的4個數a11、a12、a21、a22在檔案中卻是不連續的,MPI後臺需要呼叫2次讀函式才能完成任務。真實的程式中可能需要多呼叫成百上次讀函式才能完成一個記憶體連線段的讀取。
IO函式的呼叫延時開銷很大,儘量每次多讀寫一些資料,減少呼叫次數。這就像送快遞,無論是隻拉1個包裹還是拉100包裹,每次都要花掉固定的路上時間,當然是批次送貨快。
那怎麼辦呢?MPI在後臺開闢一塊緩衝區,如圖7,將不連續的小資料片段合併,1次讀取檔案的一大段資料,放入緩衝區,然後篩選出有用的資料放入記憶體指定位置。雖然讀取了一些無效的“空洞”資料,但減少了操作次數,整體上還是划算的。

圖 7
對寫操作來說,為防止改寫掉最新的“空洞”資料,需要先將資料讀入緩衝區,如圖8,然後用記憶體中的資料新值修改緩衝區中的相應位置,最後將緩衝區中的全部資料1次寫入檔案。
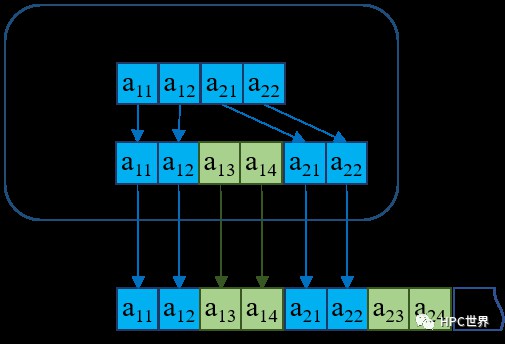
圖8
最佳化技術:兩階段IO
在“多個行程讀寫同一個檔案”樣式下,“資料篩選”技術遇到了問題:寫衝突,如圖9。行程p0寫檔案的時候需要將資料段a11~a22加鎖,而行程p1寫資料要求對資料段a13~a24加鎖,這兩個資料段有重疊,因此只能一個行程先寫另一個行程後寫,被迫序列操作。

圖 9
不能並行的根本原因是操作了沒用的“空洞”資料,因此MPI設計了“兩階段IO”技術,如圖10:每個行程都在本地開闢一塊緩衝區,每塊緩衝區對應一段連續的檔案資料;然後行程之間交換緩衝區裡的資料。

圖 10
“兩階段IO”增加了緩衝區之間的資料交換開銷,但是這樣的資料交換走的是計算伺服器之間高速網路,相對於獲得的檔案操作收益來說還是很划算的。
與並行儲存系統配合
前面都假設檔案是一個完整的資料流,而實際上檔案會被分割成多個條塊,按條塊打散存放在並行儲存伺服器裡面,檢視《糾刪碼(Erasure Code)的數學原理竟然這麼簡單》複習打散方法。
如果並行儲存伺服器上的檔案條塊大小與行程本地的緩衝區大小相匹配,那麼只需從1臺儲存伺服器讀取1次就能填滿緩衝區,最高效,如圖11。

圖 11
如果檔案條塊大小與緩衝區大小不匹配,那麼填滿緩衝區就需要從多臺儲存伺服器讀取多次,效能低下,“兩段段IO”技術前功盡棄,如圖12。
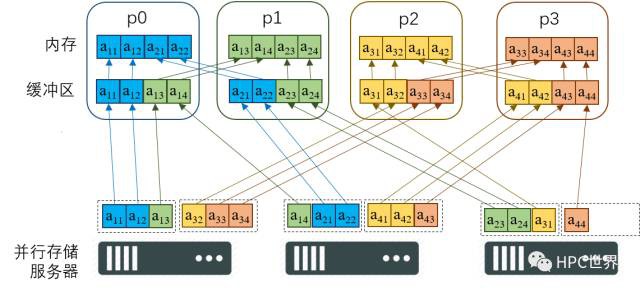
圖 12
MPI-IO與特定檔案系統的配合
如果檔案系統本身有“資料篩選”功能,那麼關閉MPI的“資料篩選”後效能更好。至於如何協調MPI緩衝區大小和檔案條塊大小,如何使MPI行程均勻連線並行儲存裝置,且聽下回分解。
文章來源:HPC世界
