(點選上方公眾號,可快速關註)
編譯:伯樂線上 – LynnShaw,英文:Peter Gleeso
http://blog.jobbole.com/113745/
看看下麵這張圖片。這是一個不同形狀大小的昆蟲的集合。花點時間按照相似程度將它們分成幾組。
這不是什麼很有技巧性的問題。 我們從把蜘蛛分到一起開始。

圖片來自Google圖片搜尋,標記以便重用
做完了嗎?雖然這裡沒有必要有所謂的正確答案,不過你極有可能將這些蟲子分成四組。蜘蛛分成一組,蝸牛一組,蝴蝶和蛾子一族,黃蜂和蜜蜂總共三個一組。
不算太糟糕,是吧?如果蟲子數量是這個的兩倍你可能還是會這麼分,對吧?如果你有空餘的時間——或者對昆蟲學的熱情——你甚至可能用相同方法對一百年個蟲子這樣分類。
然而對一個機器來說,將十個標的分成多個有意義的群組是個不小的任務,多虧了數學中一個令人費解的分支組合數學,它告訴我們將十個昆蟲分組共有115975種不同的可能。如果對二十個蟲子進行分組,將會有超過五十萬億種不同的可能。
如果對一百個蟲子分類——方案數將是宇宙中粒子的數量的很多倍。多少倍呢?透過我的計算,大概是5*10的35次方倍。事實上,有四千萬億googol多種方案(什麼是googol?)。僅僅是一百個標的。
而這些方案幾乎都是沒有意義的——雖然從這些數量異常龐大的可能的選擇中,你可以很快地找到為數不多的對蟲子分類的有用的方式。
我們人類理所當然的可以很快地對大量資料理解並分類。無論是一段文字,或者螢幕上的影象,或是一系列的標的——人類通常可以相當有效地搞清世界給我們的任何資料。
鑒於發展人工智慧和機器學習的一個關鍵方面就是讓機器迅速理解龐大的輸入資料集,那麼有什麼捷徑嗎?在這本文中,你將會看到三個聚類演演算法,機器可以這些演演算法快速理解大型資料集。這決不是一個詳盡的清單——還有很多其他的演演算法——但這三個演演算法代表了一個良好的開端!
當你想要使用它們的時候,你會得到對於每一個問題的總結,一個總體的功能介紹以及一個更細緻的,一步一步實現的例子。我相信在現實中實現對於理解是非常有幫助的。如果你真的很喜歡這些,你會發現最好的學習方式是用筆和紙。加油去吧——沒人評判哪種方式更好!

三個整齊的聚類,K=3
K-均值聚類
適用場景:
預先已經知道要分成多少組。
如何工作:
演演算法首先將每一個觀測點隨機地分配到K個類別中的一個,然後計算每一個類別的均值。下一步,在重新計算均值之前演演算法將每一個點重新分配給均值與該點資料最接近的類別。不斷重覆這一步直到不需要再重新分配。
實現例子:
考慮有12個足球運動員的一個足球隊,這些運動員每個人在本賽季都獲得了一定的進球數(3-30之間)。現在我們來將他們分成三個單獨的聚類。
第一步需要我們隨機地將這些運動員分成三組並計算每組的均值。
Group 1
Player A (5 goals), Player B (20 goals), Player C (11 goals)
Group Mean = (5 + 20 + 11) / 3 = 12
Group 2
Player D (5 goals), Player E (3 goals), Player F (19 goals)
Group Mean = 9
Group 3
Player G (30 goals), Player H (3 goals), Player I (15 goals)
Group Mean = 16
第二步:對每一個運動員,將它們重新分配到均值離他們最近的組。即,運動員A(進球數5)被分配到第2個組(均值=9)。然後重新計算這幾組的均值。
Group 1 (Old Mean = 12)
Player C (11 goals)
New Mean = 11
Group 2 (Old Mean = 9)
Player A (5 goals), Player D (5 goals), Player E (3 goals), Player H (3 goals)
New Mean = 4
Group 3 (Old Mean = 16)
Player G (30 goals), Player I (15 goals), Player B (20 goals), Player F (19 goals)
New Mean = 21
不斷重覆第二步直到所有組的均值不再變化。對於這個有些不太好的例子,下一次重覆就會達到終止條件。停止!現在你已經形成三個聚類的資料集!
Group 1 (Old Mean = 11)
Player C (11 goals), Player I (15 goals)
Final Mean = 13
Group 2 (Old Mean = 4)
Player A (5 goals), Player D (5 goals), Player E (3 goals), Player H (3 goals)
Final Mean = 4
Group 3 (Old Mean = 21)
Player G (30 goals), Player B (20 goals), Player F (19 goals)
Final Mean = 23
在這個例子中,聚類可能對應於球員在場上的位置——如後衛、中場和前鋒。k-均值在這裡使用因為我們合理地預期資料可以分成這三類。
透過這種方式,給出一系列效能統計資料,機器可以合理地評估任何團體運動中運動員的位置——這對運動分析很有用,對任何其他的將資料集按照預定義的組別進行分類也可以提供相關的見解。
細節:
這個演演算法有一些變體。對聚類進行“seeding”的初始化方法有好幾種方式。在這裡,我們將每個球員隨機分配到一個小組,然後計算出這些組的均值。這會導致初始生成的組之間的均值很接近,致使後面有更多重覆步驟。
另一種方法是初始化每個聚類時只分配一個球員,然後將其它球員分配到最近的聚類。這樣傳回的聚類比初始化seeding得到的聚類更有意義,降低了變化很大的資料集中的重覆性。但是,這種方法可能會減少完成演演算法所需的迭代次數,因為這些組將花費較少的時間完成收斂。
K-均值聚類的一個明顯的缺點是你必須提供關於你期望找到多少個聚類的先驗假設。 有一些方法可以評估一組特定的聚類結果。 例如,聚類內平方和(Within-Cluster Sum-of-Squares)是每個聚類內方差的度量。 聚類效果越好,整體WCSS越低。
層次聚類
什麼時候使用:
…你希望發掘出你的觀測資料之間的潛在關係。
如何工作:
計算距離矩陣,其中矩陣元素(i,j)的值是觀察值i和j之間的距離度量值。 然後,將最接近的兩個觀察值進行配對並計算其平均值。透過將配對的觀測值合併成一個單一的物件,形成一個新的距離矩陣。 從這個距離矩陣中,配對最近的兩個觀察值並計算它們的平均值。 重覆這個過程,直到所有的觀察結果合併在一起。
實體:
這是一個關於鯨魚和海豚物種選擇的超簡化資料集。作為一名訓練有素的生物學家,我可以向您保證,我們通常會使用更多更詳細的資料集來重建系統發生樹。 現在我們來看看這六種物種的典型體長。 我們將只使用兩個重覆的步驟。
Species Initials Length(m)
Bottlenose Dolphin BD 3.0
Risso‘s Dolphin RD 3.6
Pilot Whale PW 6.5
Killer Whale KW 7.5
Humpback Whale HW 15.0
Fin Whale FW 20.0
步驟1:計算每個物種之間的距離矩陣。在這裡,我們將使用歐式距離——資料點之間的距離。你可以計算出距離就像在道路圖上檢視距離圖一樣。可以透過讀取相關行和列的交點處的值來查詢任何物種對之間的長度差異。
BD RD PW KW HW
RD 0.6
PW 3.5 2.9
KW 4.5 3.9 1.0
HW 12.0 11.4 8.5 7.5
FW 17.0 16.4 13.5 12.5 5.0
步驟1:計算每個物種之間的距離矩陣。在這裡,我們將使用歐式距離——資料點之間的距離。你可以計算出距離就像在道路圖上檢視距離圖一樣。可以透過讀取相關行和列的交點處的值來查詢任何物種對之間的長度差異。
BD RD PW KW HW
RD 0.6
PW 3.5 2.9
KW 4.5 3.9 1.0
HW 12.0 11.4 8.5 7.5
FW 17.0 16.4 13.5 12.5 5.0
步驟2:配對兩個最接近的物種。在這裡,兩個最接近的物種是寬吻海豚和灰海豚,平均長度為3.3米。
重覆步驟1重新計算距離矩陣,但是這次將寬吻海豚和灰海豚合併成長度為3.3m的單個物件。
[BD, RD] PW KW HW
PW 3.2
KW 4.2 1.0
HW 11.7 8.5 7.5
FW 16.7 13.5 12.5 5.0
接下來,用這個新距離矩陣重覆步驟2。現在,距離最小的是領航鯨與逆戟鯨,所以我們計算他們的平均——7.0米。
然後,我們重覆第1步——重新計算距離矩陣,但是現在我們已經將領航鯨與逆戟鯨合併成了一個長度為7.0米的單個物件。
[BD, RD] [PW, KW] HW
[PW, KW] 3.7
HW 11.7 8.0
FW 16.7 13.0 5.0
接下來,我們用這個距離矩陣重覆步驟2。最小距離是兩個合併物件之間的(3.7米)——現在我們將它們合併成一個更大的物件,並取平均值(即5.2米)。
然後,我們重覆步驟1並計算一個新的距離矩陣,合併了寬吻海豚和灰海豚與領航鯨與逆戟鯨。
[[BD, RD] , [PW, KW]] HW
HW 9.8
FW 14.8 5.0
接下來,我們重覆步驟2。最小的距離(5.0米)在座頭鯨與長鬚鯨之間,所以我們將它們合併成一個單一的物件,取平均值(17.5米)。
然後,傳回步驟1——計算距離矩陣,座頭鯨與長鬚鯨已經合併。
[[BD, RD] , [PW, KW]]
[HW, FW] 12.3
最後,我們重覆步驟2——在這個矩陣中只有一個距離(12.3米),我們把所有東西都放在一個大物件中,現在我們可以停下來了!我們來看看最後的合併物件:
[[[BD, RD],[PW, KW]],[HW, FW]]
它有一個巢狀的結構(可以認為是JSON),可以把它繪製成一個樹狀的圖形或者樹形圖。 它讀取的方式與家譜相同。 兩個觀察結果在樹上離得越近,就被認為是更相似或更密切相關的。

在R-Fiddle.org上生成一個簡單的樹狀圖
樹狀圖的結構使我們能夠深入瞭解資料集的結構。在我們的例子中,我們看到兩個主要分支,一個分支是 HW 和 FW,另一個是 BD、RD、PW、KW。
在進化生物學中,具有更多樣本和測量的更大的資料集以這種方式被用來推斷它們之間的分類關係。 除了生物學之外,層次聚類在資料挖掘和機器學習環境中也有應用。
很酷的是,這種方法不需要假設你正在尋找的聚類數量。 您可以透過在給定高度“切割”樹來將傳回的樹形圖劃分為聚類。 這個高度可以透過多種方式進行選擇,具體取決於你希望對資料進行聚類的解析度。
例如,從上面的樹狀圖可以看出,如果我們在高度為10的情況下繪製一條水平線,我們就會將兩條主要分支分割,將樹狀圖分成兩個子圖。 如果我們在高度= 2切割,樹狀圖就被分成三個聚類。
細節:
關於層次聚類演演算法可以出現的變化,基本上有三個方面。
最根本的是方法——在這裡,我們使用了一個凝聚的過程,我們從單個資料點開始,並將它們迭代地聚集在一起,直到剩下一個大聚類。 另一種(但是計算量更大)的方法是從一個大聚類開始,然後將資料分成越來越小的聚類,直到剩下孤立的資料點為止。
還有一系列的方法可以用來計算距離矩陣。 很多情況下,歐幾裡得距離(參考畢達哥拉斯定理)就足夠了,但是在某些情況下還有其他可能更適用的選擇。
最後,連線標準也可以變化。 聚類根據彼此之間的距離而相互連線,但是我們定義“近”的方式是靈活的。 在上面的例子中,我們測量了每個組的平均值(或“質心”)之間的距離,並將最近的組進行配對。 但是, 你可能想要使用其他的定義。
例如,每個聚類由多個離散點組成。 我們可以將兩個聚類之間的距離定義為任意點之間的最小(或最大)距離——如下圖所示。 還有其他方法來定義連線標準,它們可能適用於不同的環境。

紅/藍:形心連線;紅色/綠色:最少連線;綠/藍:最大連線
圖社群發現
什麼時候使用:
…你可以將資料表示為網路或“圖”的時候。
如何工作:
圖中的社群通常被定義為與網路其餘部分相比,彼此連線更多的頂點的子集。 存在各種演演算法來基於更具體的定義來識別社群。 演演算法包括但不限於:Edge Betweenness,Modularity-Maximsation,Walktrap,Clique Percolation,Leading Eigenvector …
實現例子:
圖論或網路的數學研究是數學的一個有趣的分支,它讓我們將複雜系統建模為由“線”(或邊)連線的“點”(或頂點)的抽象集合。
最直觀的案例研究也許就是社交網路了。在這裡,頂點代表人,邊連線的是朋友/關註者的頂點。 然而,如果你能證明一個方法可以有意義地連線不同的部分,任何系統都可以被建模為一個網路。 圖論中聚類的創新應用包括從影象資料中提取特徵,分析基因調控網路。
作為一個入門級的例子,看看這個快速組合在一起的圖。 它顯示了我最近訪問過的八個網站,根據它們各自的維基百科文章是否彼此連線而連線在一起。 您可以手動組合這些資料,但是對於大型專案,編寫Python指令碼執行相同的操作要快得多。這是我之前寫的一個。

根據其社群成員對頂點進行著色,並根據其中心位置來確定大小。 看看Google和Twitter是最中心的吧?
而且,這些聚類在現實世界中也很有意義(一直一個重要的效能指標)。黃色的頂點通常是參考/搜尋網站;藍色頂點全部用於線上釋出(文章,推文或程式碼);紅色的頂點包括YouTube,因為Youtube是由前PayPal員工建立的。 機器推論的不錯!
除了作為有用的大型系統視覺化的方式之外,網路的真正威力是其數學分析。 讓我們開始把我們的這張網路圖片變成一種更加數學的格式。 以下是網路的鄰接矩陣。
GH Gl M P Q T W Y
GitHub 0 1 0 0 0 1 0 0
Google 1 0 1 1 1 1 1 1
Medium 0 1 0 0 0 1 0 0
PayPal 0 1 0 0 0 1 0 1
Quora 0 1 0 0 0 1 1 0
Twitter 1 1 1 1 1 0 0 1
Wikipedia 0 1 0 0 1 0 0 0
YouTube 0 1 0 1 0 1 0 0
每行和每列交點處的值記錄該對頂點之間是否存在邊。例如,Medium和Twitter之間存在一條邊(驚喜!),所以它們的行/列相交的值是1。同樣,Medium和PayPal之間沒有邊,所以它們行/列交點的值為0。
在鄰接矩陣內進行編碼就會得到這個網路的所有屬性——它給了我們解鎖各種有價值見解的鑰匙。首先,將任意列(或行)相加,就可以得出每個頂點的度數——即連線了多少個頂點。通常用字母k表示。
同樣,將每個頂點的度數相加並除以2得到L,即網路中邊(或“連線”)的數量。行數/列數即網路中頂點(或“節點”)的數量,用N表示。
知道k,L,N和鄰接矩陣A中每個單元的值,就可以計算任意給定的網路聚類的模組性。
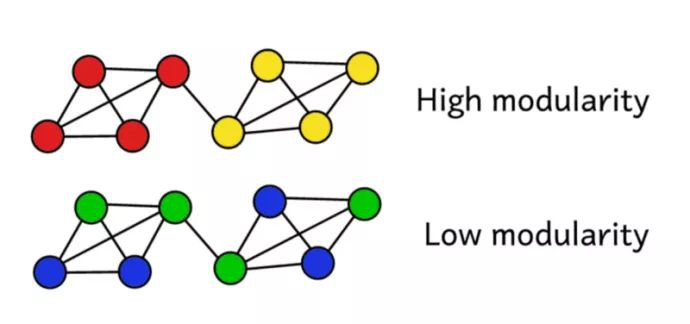
假設我們已經將網路聚類成了一些社群。我們可以使用模組性評分來評估這個聚類的“質量”。更高的分數將表明我們已經把網路分成了“準確”的社群,而低分表明我們的聚類更隨機。下麵的圖片說明瞭這一點。
模組性可以使用下麵的公式計算:

這個公示包含相當數量的數學知識,但我們可以一點一點地分解它,使它更好理解。
M當然是我們正在計算的——模組性。
1/2L告訴我們把後面所有的東西除以2L,即網路中邊的數量的兩倍。到現在為止,一切都很好理解。
Σ符號告訴我們對右邊的所有東西求和,並迭代鄰接矩陣A中的每一行和列。對於那些不熟悉求和符號的人來說,i,j = 1和N的作用非常像程式設計中的巢狀for迴圈。在Python中,你可以這樣寫:
sum = 0
for i in range(1,N):
for j in range(1,N):
ans = #stuff with i and j as indices
sum += ans
那麼#stuff with i and j 具體是什麼?
括號裡的東西告訴我們從A_ij中減去(k_i k_j)/ 2L。
A_ij是鄰接矩陣中第i行第j列的值。
k_i和k_j的值是每個頂點的度數——透過將第i行和第j列中的項分別相加而得到。將它們相乘並除以2L得到如果網路是隨機分佈的頂點i和j之間的期望的邊數。
總的來說,括號中的項表示網路的真實結構和隨機重組的預期結構之間的差異。研究這個值表明,當A_ij = 1,(k_i k_j)/ 2L小的時候,它傳回最大值。這意味著如果在頂點i和j之間存在“非預期”邊緣,我們會看到更大的值。
最後,我們將括號中的項和後面幾個符號相乘。
δc_i,c_j就是有名的 Kronecker-delta 函式。 這裡是其Python解釋:
def Kronecker_Delta(ci, cj):
if ci == cj:
return 1
else:
return 0
Kronecker_Delta(“A”,“A”) #returns 1
Kronecker_Delta(“A”,“B”) #returns 0
是的——這真的很簡單。Kronecker-delta函式有兩個引數,如果相同則傳回1,否則傳回0。
這意味著如果頂點i和j已經被放入同一個聚類中,則δc_i,c_j = 1。否則,如果它們在不同的聚類中,則該函式傳回0。
我們用這個Kronecker-delta函式乘以括號中的項,我們發現對於巢狀總和Σ,當分配給同一個聚類很多“非預期”的連線頂點的邊時,其結果是最高的。因此,模組性是衡量圖如何聚類到不同社群中的一種衡量標準。
除以2L這一操作將模組性的上限值界定為1。模組性分數接近或低於0表示網路的當前聚類實際上是無用的。模組性值越高,網路分散到不同社群的聚類越好。透過最大化模組性,我們可以找到聚類網路的最佳方式。
請註意,我們必須預先定義圖形如何聚類,以找出聚類實際上的“好”。不幸的是,使用暴力對圖的每一種可能的聚類方式進行計算,以找到
具有最高模組性分數的方式,即使是在有限樣本大小的情況下也是不可能的。
組合學告訴我們,對於只有8個頂點的網路,有4140種不同的聚類方式。 規模兩倍的16個頂點的網路將有超過一百億種可能的聚集頂點的方式。再次將網路加倍(對一個非常適中的32個頂點)將會產生128 septillion (128*10^24)種可能的方式,而且有八十個頂點的網路的聚類方式將比宇宙中可觀察的原子數還多。
所以,我們不得不轉向一種啟髮式的方法,該方法在評估可以產生最高模組性分數的聚類方面做得相當不錯,而不是嘗試每一種可能性。 這是一種叫Fast-Greedy Modularity-Maximization的演演算法,它有點類似於上面描述的凝聚層次聚類演演算法。 “Mod-Max”不是根據距離進行合併,而是根據模組性的變化來合併。它是這樣工作的:
首先將每個頂點分配到自己的社群,然後計算整個網路的模組性。
第一步要求每一個社群至少被一條單邊連線,如果兩個社群合併為一個,演演算法計算模組性的變化結果ΔM。
然後,步驟2將使得ΔM增加最多的一對社群合併。為這個聚類計算新的模組性M,並記錄下來。
重覆步驟1和2——每次合併產生最大ΔM增益的社群,然後記錄新的聚類樣式及其相關的模組性評分M。
當所有的頂點被分成一個大聚類時停下來。現在,演演算法檢查它整個過程的記錄,並確定傳回最高值M的聚類樣式。這就是傳回的社群結構。
細節:
這需要進行的計算太多了,至少對於我們人類來說。圖論中有豐富的計算難題,通常是NP-hard問題,但它也具有難以置信的潛力,為複雜的系統和資料集提供有價值的見解。與Larry Page同名的PageRank演演算法——幫助Google在不到一代人的時間裡從初創階段發展到了幾乎統治世界——完全基於圖論。
社群發現是當前圖論研究的一個焦點問題,模組性最大化有許多替代方案,雖然有用,但也有一些缺點。
一開始,其聚集的方法往往將小而明確的社群吞併為大的社群。 這就是所謂的解析度限制——演演算法不會在一定大小以內找到社群。 另一個挑戰是,Mod-Max方法實際上傾向於產生許多具有類似的高模組性分陣列成的“高原”,而不是一個獨特的,易於到達的全域性高峰值,這導致有時候難以確定最大分數。
其他演演算法使用不同的方式來定義和處理社群發現。Edge-Betweenness是一個分裂的演演算法,從所有頂點分組在一個大聚類開始。持續迭代去除網路中最不重要的邊,直到所有的頂點都被分開。這個過程產生了一個層級結構,類似的頂點在層級結構中更接近。
另一種演演算法是Clique Percolation,它考慮了圖社群之間可能的重疊。 還有另一組演演算法是基於圖上的隨機漫步,然後是譜聚類方法,它從鄰接矩陣和由其匯出的其它矩陣的特徵分解開始研究。這些方法被用於例如計算機視覺等領域的特徵提取。
給每個演演算法提供一個深入的實體,這已經遠遠超出了本文的範圍。我想說的是,這是一個活躍的研究領域,它提供了強大的方法來理解資料,即使在十年前還是個非常困難的過程。
結論
希望這篇文章能夠讓你更好地理解機器如何理解大資料。未來瞬息萬變,其中許多變化將由在下一代或兩代中的產生的技術所驅動。
正如介紹中所概述的,機器學習是一個雄心勃勃的研究領域,其中大量複雜的問題需要盡可能準確和高效地解決。對於我們人類來說任何容易完成的任務都需要機器採取創新的解決方案。
這個領域內還有很大的進步空間,誰來貢獻下一個突破的想法,無疑將會得到豐厚的回報。 也許讀了這篇文章的某個人就會發明下一個強大的演演算法?所有偉大的想法都必須從某處開始!
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功
