
作者 | Brendan Gregg
譯者 | qhwdw ? ? ? ? ? 共計翻譯:88 篇 貢獻時間:130 天
Linux 跟蹤很神奇!
跟蹤器是一個高階的效能分析和除錯工具,如果你使用過 strace(1) 或者 tcpdump(8),你不應該被它嚇到 … 你使用的就是跟蹤器。系統跟蹤器能讓你看到很多的東西,而不僅是系統呼叫或者資料包,因為常見的跟蹤器都可以跟蹤核心或者應用程式的任何東西。
有大量的 Linux 跟蹤器可供你選擇。由於它們中的每個都有一個官方的(或者非官方的)的吉祥物,我們有足夠多的選擇給孩子們展示。
你喜歡使用哪一個呢?
我從兩類讀者的角度來回答這個問題:大多數人和效能/內核工程師。當然,隨著時間的推移,這也可能會發生變化,因此,我需要及時去更新本文內容,或許是每年一次,或者更頻繁。(LCTT 譯註:本文最後更新於 2015 年)
對於大多數人
大多數人(開發者、系統管理員、運維人員、網路可靠性工程師(SRE)…)是不需要去學習系統跟蹤器的底層細節的。以下是你需要去瞭解和做的事情:
1. 使用 perf_events 進行 CPU 剖析
可以使用 perf_events 進行 CPU 剖析。它可以用一個 火焰圖[1] 來形象地表示。比如:
git clone --depth 1 https://github.com/brendangregg/FlameGraph
perf record -F 99 -a -g -- sleep 30
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
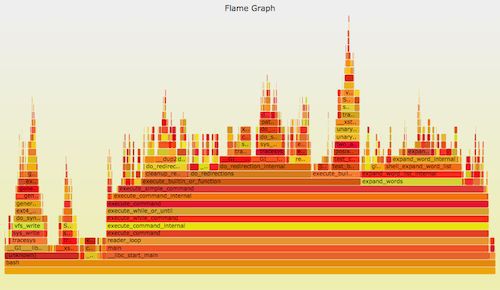
Linux 的 perf_events(即 perf,後者是它的命令)是官方為 Linux 使用者準備的跟蹤器/分析器。它位於核心原始碼中,並且維護的非常好(而且現在它的功能還在快速變強)。它一般是透過 linux-tools-common 這個包來新增的。
perf 可以做的事情很多,但是,如果我只能建議你學習其中的一個功能的話,那就是 CPU 剖析。雖然從技術角度來說,這並不是事件“跟蹤”,而是取樣。最難的部分是獲得完整的棧和符號,這部分在我的 Linux Profiling at Netflix[2] 中針對 Java 和 Node.js 討論過。
2. 知道它能幹什麼
正如一位朋友所說的:“你不需要知道 X 光機是如何工作的,但你需要明白的是,如果你吞下了一個硬幣,X 光機是你的一個選擇!”你需要知道使用跟蹤器能夠做什麼,因此,如果你在業務上確實需要它,你可以以後再去學習它,或者請會使用它的人來做。
簡單地說:幾乎任何事情都可以透過跟蹤來瞭解它。內部檔案系統、TCP/IP 處理過程、裝置驅動、應用程式內部情況。閱讀我在 lwn.net 上的 ftrace[3] 的文章,也可以去瀏覽 perf_events 頁面[4],那裡有一些跟蹤(和剖析)能力的示例。
3. 需要一個前端工具
如果你要購買一個效能分析工具(有許多公司銷售這類產品),並要求支援 Linux 跟蹤。想要一個直觀的“點選”介面去探查內核的內部,以及包含一個在不同堆疊位置的延遲熱力圖。就像我在 Monitorama 演講[5] 中描述的那樣。
我建立並開源了我自己的一些前端工具,雖然它是基於 CLI 的(不是圖形介面的)。這樣可以使其它人使用跟蹤器更快更容易。比如,我的 perf-tools[6],跟蹤新行程是這樣的:
# ./execsnoop
Tracing exec()s. Ctrl-C to end.
PID PPID ARGS
22898 22004 man ls
22905 22898 preconv -e UTF-8
22908 22898 pager -s
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
[...]
在 Netflix 公司,我正在開發 Vector[7],它是一個實體分析工具,實際上它也是一個 Linux 跟蹤器的前端。
對於效能或者內核工程師
一般來說,我們的工作都非常難,因為大多數人或許要求我們去搞清楚如何去跟蹤某個事件,以及因此需要選擇使用哪個跟蹤器。為完全理解一個跟蹤器,你通常需要花至少一百多個小時去使用它。理解所有的 Linux 跟蹤器並能在它們之間做出正確的選擇是件很難的事情。(我或許是唯一接近完成這件事的人)
在這裡我建議選擇如下,要麼:
A)選擇一個全能的跟蹤器,並以它為標準。這需要在一個測試環境中花大量的時間來搞清楚它的細微差別和安全性。我現在的建議是 SystemTap 的最新版本(例如,從 原始碼[8] 構建)。我知道有的公司選擇的是 LTTng ,儘管它並不是很強大(但是它很安全),但他們也用的很好。如果在 sysdig 中添加了跟蹤點或者是 kprobes,它也是另外的一個候選者。
B)按我的 Velocity 教程中[9] 的流程圖。這意味著盡可能使用 ftrace 或者 perf_events,eBPF 已經整合到核心中了,然後用其它的跟蹤器,如 SystemTap/LTTng 作為對 eBPF 的補充。我目前在 Netflix 的工作中就是這麼做的。
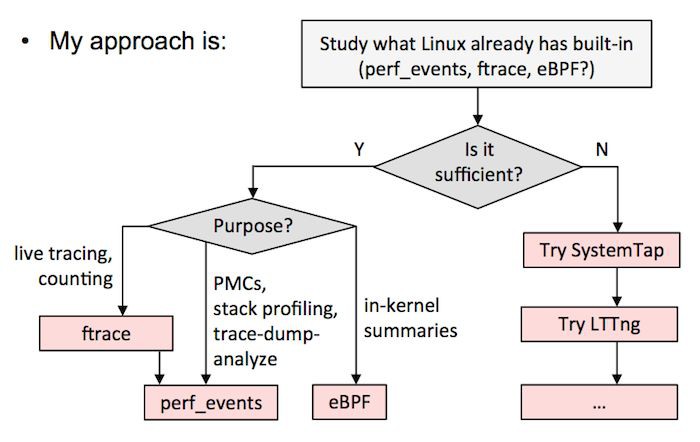
以下是我對各個跟蹤器的評價:
1. ftrace
我愛 ftrace[10],它是核心駭客最好的朋友。它被構建進核心中,它能夠利用跟蹤點、kprobes、以及 uprobes,以提供一些功能:使用可選的過濾器和引數進行事件跟蹤;事件計數和計時,核心概覽;函式流步進。關於它的示例可以檢視核心原始碼樹中的 ftrace.txt[11]。它透過 /sys 來管理,是面向單一的 root 使用者的(雖然你可以使用緩衝實體以讓其支援多使用者),它的介面有時很繁瑣,但是它比較容易調校,並且有個前端:ftrace 的主要建立者 Steven Rostedt 設計了一個 trace-cmd,而且我也建立了 perf-tools 集合。我最詬病的就是它不是可程式設計的,因此,舉個例子說,你不能儲存和獲取時間戳、計算延遲,以及將其儲存為直方圖。你需要轉儲事件到使用者級以便於進行後期處理,這需要花費一些成本。它也許可以透過 eBPF 實現可程式設計。
2. perf_events
perf_events[12] 是 Linux 使用者的主要跟蹤工具,它的原始碼位於 Linux 核心中,一般是透過 linux-tools-common 包來新增的。它又稱為 perf,後者指的是它的前端,它相當高效(動態快取),一般用於跟蹤並轉儲到一個檔案中(perf.data),然後可以在之後進行後期處理。它可以做大部分 ftrace 能做的事情。它不能進行函式流步進,並且不太容易調校(而它的安全/錯誤檢查做的更好一些)。但它可以做剖析(取樣)、CPU 效能計數、使用者級的棧轉換、以及使用本地變數利用除錯資訊進行行級跟蹤。它也支援多個併發使用者。與 ftrace 一樣,它也不是內核可程式設計的,除非 eBPF 支援(補丁已經在計劃中)。如果只學習一個跟蹤器,我建議大家去學習 perf,它可以解決大量的問題,並且它也相當安全。
3. eBPF
擴充套件的伯克利包過濾器(eBPF)是一個核心內的虛擬機器,可以在事件上執行程式,它非常高效(JIT)。它可能最終為 ftrace 和 perf_events 提供核心內程式設計,並可以去增強其它跟蹤器。它現在是由 Alexei Starovoitov 開發的,還沒有實現完全的整合,但是對於一些令人印象深刻的工具,有些核心版本(比如,4.1)已經支援了:比如,塊裝置 I/O 的延遲熱力圖。更多參考資料,請查閱 Alexei 的 BPF 演示[13],和它的 eBPF 示例[14]。
4. SystemTap
SystemTap[15] 是一個非常強大的跟蹤器。它可以做任何事情:剖析、跟蹤點、kprobes、uprobes(它就來自 SystemTap)、USDT、核心內程式設計等等。它將程式編譯成核心模組並載入它們 —— 這是一種很難保證安全的方法。它開發是在核心程式碼樹之外進行的,並且在過去出現過很多問題(核心崩潰或凍結)。許多並不是 SystemTap 的過錯 —— 它通常是首次對核心使用某些跟蹤功能,並率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要從它的原始碼編譯),但是,許多人仍然沒有從早期版本的問題陰影中走出來。如果你想去使用它,花一些時間去測試環境,然後,在 irc.freenode.net 的 #systemtap 頻道與開發者進行討論。(Netflix 有一個容錯架構,我們使用了 SystemTap,但是我們或許比起你來說,更少擔心它的安全性)我最詬病的事情是,它似乎假設你有辦法得到核心除錯資訊,而我並沒有這些資訊。沒有它我實際上可以做很多事情,但是缺少相關的檔案和示例(我現在自己開始幫著做這些了)。
5. LTTng
LTTng[16] 對事件收集進行了最佳化,效能要好於其它的跟蹤器,也支援許多的事件型別,包括 USDT。它的開發是在核心程式碼樹之外進行的。它的核心部分非常簡單:透過一個很小的固定指令集寫入事件到跟蹤緩衝區。這樣讓它既安全又快速。缺點是做核心內程式設計不太容易。我覺得那不是個大問題,由於它最佳化的很好,可以充分的擴充套件,儘管需要後期處理。它也探索了一種不同的分析技術。很多的“黑匣子”記錄了所有感興趣的事件,以便可以在 GUI 中以後分析它。我擔心該記錄會錯失之前沒有預料的事件,我真的需要花一些時間去看看它在實踐中是如何工作的。這個跟蹤器上我花的時間最少(沒有特別的原因)。
6. ktap
ktap[17] 是一個很有前途的跟蹤器,它在核心中使用了一個 lua 虛擬機器,不需要除錯資訊和在嵌入時裝置上可以工作的很好。這使得它進入了人們的視野,在某個時候似乎要成為 Linux 上最好的跟蹤器。然而,由於 eBPF 開始整合到了核心,而 ktap 的整合工作被推遲了,直到它能夠使用 eBPF 而不是它自己的虛擬機器。由於 eBPF 在幾個月過去之後仍然在整合過程中,ktap 的開發者已經等待了很長的時間。我希望在今年的晚些時間它能夠重啟開發。
7. dtrace4linux
dtrace4linux[18] 主要由一個人(Paul Fox)利用業務時間將 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些供應器可以工作,還不是很完美,它最多應該算是實驗性的工具(不安全)。我認為對於許可證的擔心,使人們對它保持謹慎:它可能永遠也進入不了 Linux 核心,因為 Sun 是基於 CDDL 許可證釋出的 DTrace;Paul 的方法是將它作為一個外掛。我非常希望看到 Linux 上的 DTrace,並且希望這個專案能夠完成,我想我加入 Netflix 時將花一些時間來幫它完成。但是,我一直在使用內建的跟蹤器 ftrace 和 perf_events。
8. OL DTrace
Oracle Linux DTrace[19] 是將 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。過去這些年的許多釋出版本都一直穩定的進步,開發者甚至談到了改善 DTrace 測試套件,這顯示出這個專案很有前途。許多有用的功能已經完成:系統呼叫、剖析、sdt、proc、sched、以及 USDT。我一直在等待著 fbt(函式邊界跟蹤,對內核的動態跟蹤),它將成為 Linux 核心上非常強大的功能。它最終能否成功取決於能否吸引足夠多的人去使用 Oracle Linux(併為支援付費)。另一個羈絆是它並非完全開源的:核心元件是開源的,但使用者級程式碼我沒有看到。
9. sysdig
sysdig[20] 是一個很新的跟蹤器,它可以使用類似 tcpdump 的語法來處理系統呼叫事件,並用 lua 做後期處理。它也是令人印象深刻的,並且很高興能看到在系統跟蹤領域的創新。它的侷限性是,它的系統呼叫只能是在當時,並且,它轉儲所有事件到使用者級進行後期處理。你可以使用系統呼叫來做許多事情,雖然我希望能看到它去支援跟蹤點、kprobes、以及 uprobes。我也希望看到它支援 eBPF 以檢視核心內概覽。sysdig 的開發者現在正在增加對容器的支援。可以關註它的進一步發展。
深入閱讀
我自己的工作中使用到的跟蹤器包括:
不好意思,沒有更多的跟蹤器了! … 如果你想知道為什麼 Linux 中的跟蹤器不止一個,或者關於 DTrace 的內容,在我的 從 DTrace 到 Linux[45] 的演講中有答案,從 第 28 張幻燈片[46] 開始。
感謝 Deirdre Straughan[47] 的編輯,以及跟蹤小馬的建立(General Zoi 是小馬的建立者)。
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
作者:Brendan Gregg[41] 譯者:qhwdw 校對:wxy
本文由 LCTT 原創編譯,Linux中國 榮譽推出