(點選上方公眾號,可快速關註)
編譯:伯樂線上 – 精算狗,英文:ageitgey
http://python.jobbole.com/89004/
人人都恨驗證碼——那些惱人的圖片,顯示著你在登陸某網站前得輸入的文字。設計驗證碼的目的是,透過驗證你是真實的人來避免電腦自動填充表格。但是隨著深度學習和計算機視覺的興起,現在驗證碼常常易被攻破。
我拜讀了 Adrian Rosebrock 寫的《Deep Learning for Computer Vision with Python》。在書中,Adrian 描述了他是怎樣用機器學習繞過紐約 E-ZPass 網站上的驗證碼:

Adrian 無法接觸到該應用生成驗證碼的原始碼。為了攻破該系統,他不得不下載數百張示例圖片,並手動處理它們來訓練他自己的系統。
但是如果我們想攻破的是一個開源驗證碼系統,我們確實能接觸到原始碼該怎麼辦呢?
我訪問了 WordPress.org 的外掛頻道,並搜尋了“驗證碼”。第一條搜尋結果是 Really Simple CAPTCHA,並且有超過一百萬次的活躍安裝:

最好的一點是,它是開源的!既然我們已經有了生成驗證碼的原始碼,那它應該挺容易被攻破的。為了讓這件事更有挑戰性,讓我們給自己規定個時限吧。我們能在 15 分鐘內完全攻破這個驗證碼系統嗎?來試試吧!
重要說明:這絕不是對 Really Simple CAPTCHA 外掛或對其作者的批評。該外掛作者自己說它已經不再安全了,建議使用其他外掛。這僅僅是一次好玩又迅速的技術挑戰。但是如果你是那剩餘的一百多萬使用者之一,也許你應該改用其他外掛 🙂
挑戰
為了構思一個攻擊計劃,來看看 Really Simple CAPTCHA 會生成什麼樣的圖片。在示例網站上,我們看到了以下圖片:

好了,所以驗證碼似乎是四個字母。在 PHP 原始碼中對其進行驗證:
public function __construct() {
/* Characters available in images */
$this->chars = ‘ABCDEFGHJKLMNPQRSTUVWXYZ23456789’;
/* Length of a word in an image */
$this->char_length = 4;
/* Array of fonts. Randomly picked up per character */
$this->fonts = array(
dirname( __FILE__ ) . ‘/gentium/GenBkBasR.ttf’,
dirname( __FILE__ ) . ‘/gentium/GenBkBasI.ttf’,
dirname( __FILE__ ) . ‘/gentium/GenBkBasBI.ttf’,
dirname( __FILE__ ) . ‘/gentium/GenBkBasB.ttf’,
);
沒錯,它用四種不同字型的隨機組合來生成四個字母的驗證碼。並且可以看到,它在程式碼中從未使用 O 或者 I,以此避免使用者混淆。總共有 32 個可能的字母和數字需要我們識別。沒問題!
計時:2 分鐘
工具
在進行下一步前,提一下我們要用來解決問題的工具:
Python 3
Python 是一種有趣的程式語言,它有大量的機器學習和計算機視覺庫。
OpenCV
OpenCV 是一種流行的計算機視覺和圖片處理框架。我們要使用 OpenCV 來處理驗證碼圖片。由於它有 Python API,所以我們可以直接從 Python 中使用它。
Keras
Keras 是用 Python 編寫的深度學習框架。它使得定義、訓練和用最少的程式碼使用深度神經網路容易實現。
TensorFlow
TensorFlow 是 Google 的機器學習庫。我們會用 Keras 程式設計,但是 Keras 並沒有真正實現神經網路的邏輯本身,而是在幕後使用 Google 的 TensorFlow 庫來挑起重擔。
好了,回到我們的挑戰吧!
創造我們的資料集
為了訓練任何機器學習系統,我們需要訓練資料。為了攻破一個驗證碼系統,我們想要像這樣的訓練資料:

鑒於我們有 WordPress 外掛的原始碼,我們可以調整它,一起儲存 10,000 張驗證碼圖片及分別對應的答案。
經過幾分鐘對程式碼的攻擊,並添加了一個簡單的 for 迴圈之後,我有了一個訓練資料的檔案夾——10,000 個 PNG 檔案,檔案名為對應的正確答案:

這是唯一一個我不會給你示例程式碼的部分。我們做這個是為了教育,我不希望你們真去黑 WordPress 網站。但是,我最後會給你生成的這10,000 張圖片,這樣你就能重覆我的結果了。
計時:5 分鐘
簡化問題
既然有了訓練資料,就可以直接用它來訓練神經網路了:

有了足夠的訓練資料,這個方法可能會有用——但是我們可以使問題更簡化來解決。問題越簡單,要解決它需要的訓練資料就越少,需要的計算能力也越低。畢竟我們只有 15 分鐘!
幸運的是,驗證碼圖片總是由僅僅四個字母組成。如果我們能想辦法把圖片分開,使得每個字母都在單獨的圖片中,這樣我們只需要訓練神經網路一次識別一個字母:
我沒有時間去瀏覽 10,000 張訓練圖片併在 Photoshop 中手動把它們拆分開。這得花掉好幾天的時間,而我只剩下 10 分鐘了。我們還不能把圖片分成相等大小的四塊,因為該驗證碼外掛把字母隨機擺放在不同的水平位置上以防止這一做法:

幸運的是,我們仍然可以自動處理。在影象處理中,常常需要檢測有相同顏色的畫素塊。這些連續畫素塊周圍的界限被稱為輪廓。OpenCV 中有一個 LndContours() 函式,可以被用來檢測這些連續區域。
所以我們用一個未經處理的驗證碼圖片開始:
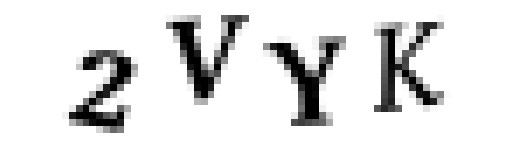
接下來把該圖片轉換成純黑白(這叫做 thresholding),這樣容易找到連續區域:
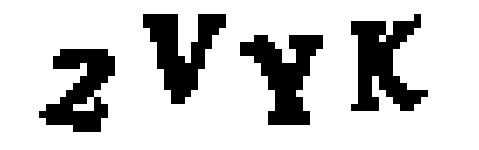
接著,使用 OpenCV 的 LndContours() 函式來檢測該圖片中包含相同顏色畫素塊的不同部分:

接下來就是簡單地把每個區域存成不同的圖片檔案。鑒於我們知道每張圖片都應該包含從左到右的四個字母,我們可以利用這一點在儲存的同時給字母標記。只要我們是按順序儲存的,我們就應該能儲存好每個圖片字母及其對應的字母名。
但是等等——我看到一個問題!有時驗證碼中有像這樣重疊的字母:

這意味著我們會把兩個字母分離成一個區域:

如果不處理這個問題,會創造出糟糕的訓練資料。我們得解決這個問題,這樣就不會意外地教機器把兩個重疊的字母識別成一個字母了。
一個簡單的方法是,如果一個輪廓區域比它的高度更寬,這意味著很可能有兩個字母重疊在一起了。在這種情況下,我們可以把重疊的字母從中間拆分成兩個,並將其看作兩個不同的字母:
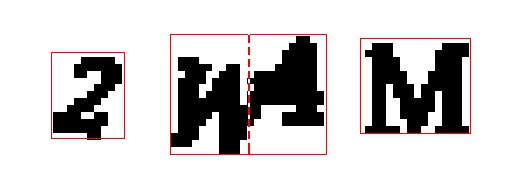
既然我們找到拆分出單個字母的方法了,就對所有驗證碼圖片進行該操作。標的是收集每個字母的不同變體。我們可以將每個字母儲存在各自對應的檔案夾中,以保持條理。
在我分離出所有字母后,我的 W 檔案夾長這樣:

計時:10 分鐘
構建並訓練神經系統
由於我們只需要識別單個字母和數字的圖片,我們不需要非常複雜的神經網路結構。識別字母要比識別像貓狗這樣複雜的圖片容易得多。
我們要使用簡單的摺積神經網路結構,有兩層摺積層以及兩層完全連線層:

如果你想要瞭解更多神經網路的工作,以及為什麼它們是圖片識別的理想工具,請參考 Adrian 的書或者我之前的文章。
定義該神經網路結構,只需要使用 Keras 的幾行程式碼:
# Build the neural network!
model = Sequential()
# First convolutional layer with max pooling
model.add(Conv2D(20, (5, 5), padding=“same”, input_shape=(20, 20, 1), activation=“relu”))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Second convolutional layer with max pooling
model.add(Conv2D(50, (5, 5), padding=“same”, activation=“relu”))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Hidden layer with 500 nodes
model.add(Flatten())
model.add(Dense(500, activation=“relu”))
# Output layer with 32 nodes (one for each possible letter/number we predict)
model.add(Dense(32, activation=“softmax”))
# Ask Keras to build the TensorFlow model behind the scenes
model.compile(loss=“categorical_crossentropy”, optimizer=“adam”, metrics=[“accuracy”])
現在我們可以訓練它了!
# Train the neural network
model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=32, epochs=10, verbose=1)
在 10 透過了訓練資料集後,我們達到了幾乎 100% 的正確率。此時,我們應該能隨時自動繞過這個驗證碼了!我們成功了!
計時:15 分鐘(好險!)
使用訓練後的模型來處理驗證碼
既然有了一個訓練後的神經網路,利用它來攻破真實的驗證碼要很容易了:
-
1.從一個使用 WordPress 外掛的網站上下載一張驗證碼圖片。
-
2.使用文章中生成訓練資料集的方法,把該驗證碼圖片拆分成四張字母圖片。
-
3.用神經網路對每張字母圖片分別作預測。
-
4.用四個預測字母作為驗證碼的答案。
-
5.狂歡!
在破解驗證碼時,我們的模型看起來是這樣:

或者從命令來看:

來試試吧!
如果你想自己試試,你可以從這裡找到程式碼( http://t.cn/R8yFJiN )。它包含 10,000 張示例圖片和文章中每一步的所有程式碼。參考檔案 README.md 中的執行指導。
但是如果你想瞭解每一行程式碼都做了什麼,我強烈建議你看看《 Deep Learning for Computer Vision with Python》。該書改寫了更多的細節,而且有大量的詳細示例。這本書是我目前見過的唯一一本既包含了執行原理,又包含瞭如何在現實生活中用其來解決複雜問題的書。去看看吧!
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功
