來自:碼農翻身(微訊號:coderising)
張大胖找了個實習的工作, 第一天上班Bill師傅給他分了個活兒:日誌分析。
張大胖拿到了師傅給的日誌檔案,大概有幾十兆,開啟一看, 每一行都長得差不多,類似這樣:
212.86.142.33 – – [20/Mar/2017:10:21:41 +0800] “GET / HTTP/1.1″ 200 986 “http://www.baidu.com/” “Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; )”
張大胖知道,這些日誌都是Web伺服器產生的,裡邊包含了像客戶端IP, 訪問時間, 請求的URL,請求處理的狀態, referer, User Agent等資訊。
師傅說,你想個辦法統計一天之內每個頁面的訪問量(PV),獨立的IP數, 還有使用者最喜歡搜尋的前10個關鍵字。
張大胖心說這簡單啊,我用Linux上的cat,awk等小工具就能做出來, 不過還是正式一點,用我最喜歡的Python寫個程式吧,把每一行文字分割成一個個欄位,然後分分組、計算一下不就得了。
慢著, 這樣一來這個程式就只能幹這些事兒,不太靈活,擴充套件性不太好。
要不把分割好的欄位寫入資料庫表?
比如access_log(id,ip,timestamp,url, status,referer, user_agent), 這樣就能利用資料庫的group 功能和count功能了,sql多強大啊, 想怎麼處理就怎麼處理。
對,就這麼辦!
半天以後,張大胖就把這個程式給搞定了,還畫了一個架構圖,展示給了師傅。

師傅一看:“不錯嘛,思路很清晰,還考慮到了擴充套件性,可以應對以後更多的需求。”
於是這個小工具就這麼用了起來。
張大胖畢業以後也順利地加入了這家公司。
網際網路尤其是移動網際網路發展得極快,公司網站的使用者量暴增,訪問量也水漲船高,日誌量也很感人,每小時都能產生好幾個G,張大胖實習期間“引以為傲”的小程式沒法再用了,資料庫根本就放不下啊。
不僅資料庫放不下,在Web伺服器上也放不下了,更不用說去做分析了。
張大胖主動請纓,打算搞定這個問題。 當然他也很聰明地把經驗豐富的師傅Bill給拉上了。
兩個人來到會議室,開始了討論。
張大胖先算了一筆賬:如果是一臺機器,一個硬碟,讀取速度是75M/s ,那需要花費10多天才能讀取100T的內容。 但是如果是有100個硬碟, 並行的讀取速度就能達到75G/s , 幾十分鐘就可以把100T的資料給讀出來了,多快啊。
他對Bill說道:“看來只有分散式儲存才能拯救了。多來幾臺機器吧,把log1, log2,log3…這些檔案存放在不同的機器上。”

師傅Bill說道:“你想得太簡單了,分散式可不是簡單地新增機器, 機器的硬碟壞了怎麼辦?日誌檔案是不是就丟失了? 熱門檔案怎麼辦? 訪問量特別大,那對應的機器負載就特別高, 這樣不公平啊!
張大胖說道:“第一個問題好辦,我可以做備份啊,把每個檔案都存三個備份。這樣壞的可能性就大大降低了。你說的第二個問題,我們的日誌哪有什麼熱門檔案?”
“要考慮下通用性嘛!將來你這個分散式的檔案系統可以處理別的東西啊。”
“好吧, 我可以被檔案切成小塊,讓他們分散在各個機器上,這就行了吧。 備份的時候,把每個小塊都備份三份就解決問題了。”

(備註:三份是最低要求)
“那問題就來了,我們該怎麼使用呢? 客戶端總不能說把檔案的第一塊從伺服器1上取出來,第二塊從伺服器4上取出來,第三塊從伺服器2上取出來….. 再說客戶端保留這些‘亂七八糟’的資訊該多煩人啊。” Bill提出的問題很致命。
“這個……” 張大胖思考了半天, “看來還得做抽象啊,我的分散式檔案系統得提供一個抽象層,讓檔案分塊對客戶端保持透明, 客戶端根本不必知道檔案是怎麼分塊的,分塊後存放在什麼伺服器上。他們只需要知道一個檔案的路徑/logs/log1,就可以讀寫了,細節不用操心。”

“不錯,看來你已經Get到了,一定要透過抽象給客戶端提供一個簡單的檢視,盡可能讓他們像訪問本地檔案一樣來使用!” Bill 立刻做了升華。
“不過,”張大胖突然想到一個問題,“這樣的分散式檔案系統似乎只適合在檔案末尾不斷地對追加內容,如果是想隨機地讀寫,比如定位到某個位置,然後寫入新的資料,就很麻煩了。”
“這也沒辦法,事物總是有利有弊,現在的系統就是適合一次寫入,多次讀取的場景。”
“不過, ”Bill 接著說,“檔案被分成了哪些塊,這些塊都放在什麼伺服器上,系統有哪些伺服器,伺服器上都多大空間,這些都是Metadata, 你得專門找個伺服器儲存起來,我們把這個伺服器叫做Metadata節點如何?或者簡單一點,叫做NameNode吧!類似於整個系統的大管家。 ”
“好, 我們把那些儲存資料的伺服器叫做Data節點(DataNode)吧,這樣就區分開了。我可以寫一個客戶端讓大家使用,這個客戶端透過查詢NameNode,定位到檔案的分塊和儲存位置,這樣大家就可以讀寫了!”
Bill在白板上畫了一張圖,展示了當前的設計:

“綠色虛線的意思是資料的讀寫流, 對吧, 但是橙色的虛線是什麼鬼?” 張大胖問道。
“你想想這麼一種情況,如果某個Datanode 的機器掛掉了,它上面的所有檔案分塊都無法讀寫了,這時候Namenode如何才能知道呢? 還有,如果某個Datanode所在機器的磁碟空間不足了,是不是也得讓Namenode這個大管家知道?”
“奧,Datanode和Namenode 之間需要定期的通訊, 這就麻煩了,我還得特別為他們設計一個通訊協議啊!” 張大胖有點沮喪。
“分散式系統就是這樣,有很多挑戰,機器壞掉,網路斷掉….. 你想在普通的、廉價的機器上實現高可靠性是很難的一件事情。”
“我們再細化下讀寫的流程吧?” Bill 提議。
“我覺得挺簡單啊,比如去讀取一個檔案,客戶端只需把檔案名告訴Namenode, 讓Namenode把所有資料都傳回不就行了?這樣客戶端對Datanode保持透明,不錯吧!”
Bill嚴肅地搖了搖頭:“不行, 如果所有的資料流都經過Namenode, 它會成為瓶頸的! 無法支援多個客戶端的併發訪問, 記住,我們要處理的可是TB, 乃至PB級別的資料啊。”
“對對,我沒有深入考慮啊!” 張大胖感慨薑還是老的辣,趕緊換個思路, “要不這樣,讀取檔案的時候,Namenode只傳回檔案的分塊以及該分塊所在的Datanode串列, 這樣我們的客戶端就可以選擇一個Datanode來讀取檔案了。”
“但是一個分塊有3個備份,到底選哪個? ” Bill問道
“肯定是最近的那個了,嗯,怎麼定義遠近呢?” 張大胖犯難了。
“我們可以定義一個‘距離’的概念。 ” Bill 說道。
客戶端和Datanode是同一個機器 : 距離為0 ,表示最近
客戶端和Datanode是同一個機架的不同機器 : 距離為2 ,稍微遠一點
客戶端和Datanode位於同一個資料中心的不同機架上 : 距離為4, 更遠一點
“沒想到分散式系統這麼難搞,比我實習做的那個程式難度提高了好幾個數量級!”
話雖這麼說,張大胖還是畫了一個讀取檔案的流程圖:

(註:圖中只畫出了一個分塊的讀取,對檔案其他分塊的讀取還會持續進行)
“寫入檔案也類似,” 張大胖打算趁熱打鐵,“讓Namenode 找到可以寫資料的三個Datanode,傳回給我們的客戶端,客戶端就可以向這三個Datanode 發起寫的操作了!”
“假設你有個10G的檔案,難道讓客戶端向Datanode寫入3次,使用30G的流量嗎?” Bill馬上提了一個關鍵的問題。
“不這麼做還能怎麼辦? 我們要儲存多個備份啊!”
“有個解決辦法,我們可以把三個Datanode 組成一個Pipline(管道), 我們只把資料發給第一個Datanode, 讓資料在這個管道內‘流動’起來, 第一個Datanode發個備份給第二個, 第二個發同樣的備份給第三個。”
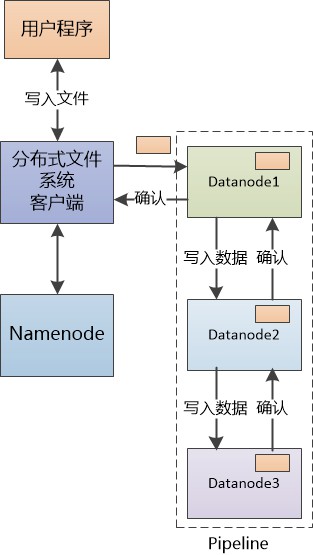
(註:實際的檔案寫入比較複雜,有更多細節, 這裡只是重點展示pipeline)
“有點意思,客戶端只發出一次寫的請求,資料的複製由我們的Datanode合作搞定。” 張大胖深為佩服,師傅Bill的腦子就是好使啊。
“還有啊,”Bill說道,“咱們的設計中Namenode這個大管家有單點失敗的風險,我們最好還是做一個備份的節點。”
張大胖深表贊同。
“我們給這個系統起個名字吧?叫Distrubted File System(簡稱DFS)怎麼樣?” 張大胖說。
“俗,太俗,叫Hadoop吧,這是我兒子玩具象的名稱。嗯,還是叫Hadoop Distributed File System, HDFS。” Bill 的提議出乎張大胖意料。
“行吧,我們有了HDFS,可以儲存海量的日誌了,我就可以寫個程式,去讀取這些檔案,統計各種各樣的使用者訪問了。”
“你打算把你的程式放到哪裡?”
“自然是放在HDFS之外的某個機器上,然後透過HDFS 客戶端去訪問資料啊!”
“100T的資料從HDFS的眾多機器中讀取出來,在一臺機器上處理? 這得多慢啊! 我們要考慮把計算也做成分散式的,並且讓計算程式盡可能地靠近資料,這樣就快了!”
“分散式計算?”
“沒錯,聽說過Mapreduce 沒有?”
張大胖搖了搖頭:“這是什麼鬼?”
“我們下次再聊吧!”
後記:這篇文章介紹了HDFS的一些關鍵設計理念,已經屬於非常簡化的情況了,沒有考慮資料的完整性,節點失效等更多細節。
●本文編號292,以後想閱讀這篇文章直接輸入292即可
●輸入m獲取文章目錄

Java程式設計
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
