小編邀請您,先思考:
1 如何構建決策樹?
2 決策樹適合解決什麼問題?
1. 什麼是決策樹/判定樹(decision tree)?
決策樹(Decision Tree)演演算法是機器學習(Machine Learning)中分類演演算法中的一個重要演演算法,屬於監督學習(Supervised Learning)演演算法。決策樹演演算法是一種逼近離散函式值的方法。它是一種典型的分類方法,首先對資料進行處理,利用歸納演演算法生成可讀的規則和決策樹,然後使用決策對新資料進行分析。本質上決策樹是透過一系列規則對資料進行分類的過程。

2. 決策樹構造
決策樹學習的演演算法通常是一個遞迴地選擇最優特徵,並根據該特徵對訓練資料進行分割,使得對各個子資料集有一個最好的分類的過程。決策樹構造可以分三步進行:特徵選擇、決策樹的生成、決策樹的修剪。
3. 熵(entropy)概念:
-
資訊和抽象,如何度量?
-
1948年,夏農提出了 “資訊熵(entropy)”的概念
-
一條資訊的資訊量大小和它的不確定性有直接的關係,要搞清楚一件非常非常不確定的事情,或者是我們一無所知的事情,需要瞭解大量資訊==>資訊量的度量就等於不確定性的多少
-
例子:猜世界盃冠軍,假如一無所知,猜多少次?每個隊奪冠的機率不是相等的 位元(bit)來衡量資訊的多少

變數的不確定性越大,熵也就越大.
4. 決策樹歸納演演算法 (ID3)
-
決策樹方法最早產生於上世紀60年代,到70年代末。由J.Ross.Quinlan提出了ID3演演算法,此演演算法的目的在於減少樹的深度。但是忽略了葉子數目的研究。C4.5演演算法在ID3演演算法的基礎上進行了改進,對於預測變數的缺值處理、剪枝技術、派生規則等方面作了較大改進,既適合於分類問題,又適合於回歸問題。
-
決策樹的典型演演算法有ID3,C4.5,CART等。資料挖掘領域的十大經典演演算法中,C4.5演演算法排名第一。C4.5演演算法是機器學習演演算法中的一種分類決策樹演演算法,其核心演演算法是ID3演演算法。C4.5演演算法產生的分類規則易於理解,準確率較高。
選擇屬性判斷節點
資訊獲取量(Information Gain):Gain(A) = Info(D) – Infor_A(D)
透過A來作為節點分類獲取了多少資訊
電腦銷售客戶的訓練資料集:
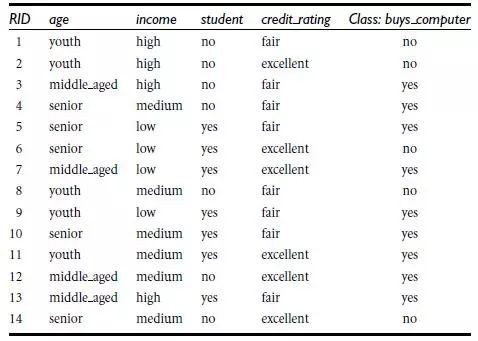
根據年齡、收入、是否為學生,信用度判斷是否買電腦



類似,Gain(income) = 0.029,
Gain(student) = 0.151,
Gain(credit_rating)=0.048
所以,選擇age作為第一個根節點

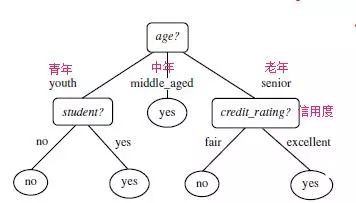
重覆上面的操作。
演演算法:
-
樹以代表訓練樣本的單個結點開始(步驟1)。
-
如果樣本都在同一個類,則該結點成為樹葉,並用該類標號(步驟2 和3)。
-
否則,演演算法使用稱為資訊增益的基於熵的度量作為啟發資訊,選擇能夠最好地將樣本分類的屬性(步驟6)。該屬性成為該結點的“測試”或“判定”屬性(步驟7)。在演演算法的該版本中,
-
所有的屬性都是分類的,即離散值。連續屬性必須離散化。
-
對測試屬性的每個已知的值,建立一個分枝,並據此劃分樣本(步驟8-10)。
-
演演算法使用同樣的過程,遞迴地形成每個劃分上的樣本判定樹。一旦一個屬性出現在一個結點上,就不必該結點的任何後代上考慮它(步驟13)。
-
遞迴劃分步驟僅當下列條件之一成立停止:
-
(a) 給定結點的所有樣本屬於同一類(步驟2 和3)。
-
(b) 沒有剩餘屬性可以用來進一步劃分樣本(步驟4)。在此情況下,使用多數表決(步驟5)。
-
這涉及將給定的結點轉換成樹葉,並用樣本中的多數所在的類標記它。替換地,可以存放結
-
點樣本的類分佈。
-
(c) 分枝
-
test_attribute = a i 沒有樣本(步驟11)。在這種情況下,以 samples 中的多數類
-
建立一個樹葉(步驟12)
5 .決策樹/判定樹(decision tree)
-
判定樹是一個類似於流程圖的樹結構:其中,每個內部節點表示在一個屬性上的測試,每個分支代表一個屬性輸出,而每個樹葉節點代表類或類分佈。典例:

判定樹:根據條件判定是否去play
7. 決策樹優點:
-
直觀、生成的樣式簡單,便於理解,小規模資料集有效
-
分類精度高
缺點:
-
處理連續變數不好
-
類別較多時,錯誤增加的比較快
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
好又樂書屋,專註分享有思想的人物,身心健康,自我教育,閱讀寫作和有趣味的生活等內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
