1. 概述
相信很多同學看過 MySQL 各種最佳化的文章,裡面 99% 會提到:單表資料量大了,需要進行分片(水平拆分 or 垂直拆分)。分片之後,業務上必然面臨的場景:跨分片的資料合併。今天我們就一起來瞅瞅 MyCAT 是如何實現分片結果合併。
跨分片查詢大體流程如下:

和 《【單庫單表】查詢》 不同的兩個過程:
-
【2】多分片執行 SQL
-
【4】合併多分片結果
下麵,我們來逐條講解這兩個過程。
2. 多分片執行 SQL
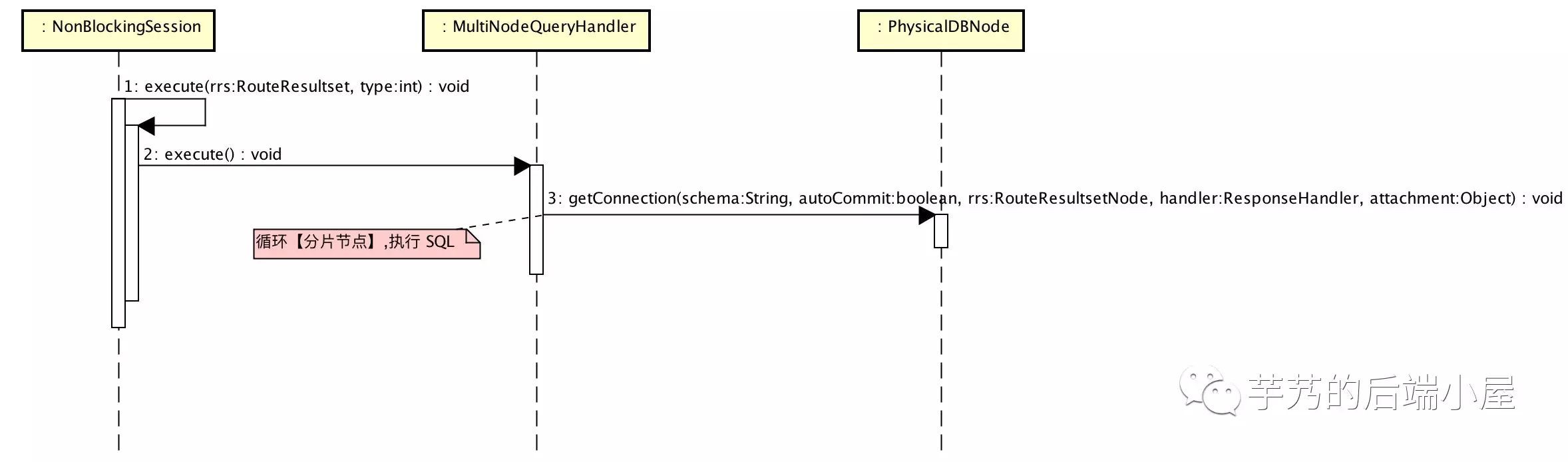
經過 SQL 解析後,計算出需要執行 SQL 的分片節點,遍歷分片節點傳送 SQL 進行執行。
核心程式碼:
-
MultiNodeQueryHandler.java#execute(…)
SQL 解析 詳細過程,我們另開文章,避免內容過多,影響大家對 分片結果合併 流程和邏輯的理解。
3. 合併多分片結果

和 《【單庫單表】查詢》 不同,多個分片節點都會分別響應 記錄頭(essay-header) 和 記錄行(row) 。在開始分析 MyCAT 是怎麼合併多分片結果之前,我們先來回想下 SQL 的執行順序。
FROM // [1] 選擇表
WHERE // [2] 過濾表
GROUP BY // [3] 分組SELECT // [4] 普通欄位,max / min / avg / sum / count 等函式,distinctHAVING // [5] 再過濾表ORDER BY // [6] 排序LIMIT // [7] 分頁3.1 記錄頭(essay-header)
多個分片節點響應時,會響應多次 記錄頭(essay-header) 。MyCAT 在實際處理時,只處理第一個傳回的 記錄頭(essay-header) 。因此,在使用時要保證表的 Schema 相同。
分片節點響應的 記錄頭(essay-header) 可以直接傳回 MySQL Client 嗎?答案是不可以。AVG函式 是特殊情況,MyCAT 需要將 AVG 拆成 SUM + COUNT 進行計算。舉個例子:
// [1] MySQL Client => MyCAT :
SELECT AVG(age) FROM student;
// [2] MyCAT => MySQL Server :
SELECT SUM(age) AS AVG0SUM, COUNT(age) AS AVG0COUNT FROM student;
// [3] 最終:AVG(age) = SUM(age) AS AVG0SUM / COUNT(age)核心程式碼:
-
MultiNodeQueryHandler.java#fieldEofResponse(…)。
3.2 記錄行(row)
3.1 AbstractDataNodeMerge
MyCAT 對分片結果合併透過 AbstractDataNodeMerge 子類來完成。

AbstractDataNodeMerge :
-
-packs :待合併記錄行(row)佇列。佇列尾部插入
END_FLAG_PACK表示佇列已結束。 -
-running :合併邏輯是否正在執行中的標記。
-
~onRowMetaData(…) :根據記錄列資訊(ColMeta)構建對應的排序元件和聚合元件。需要子類進行實現。
-
~onNewRecord(…) :插入記錄行(row) 到
packs。 -
~outputMergeResult(…) :插入
END_FLAG_PACK到packs。 -
~run(…) :執行合併分片結果邏輯,並將合併結果傳回給 MySQL Client。需要子類進行實現。

透過 running 標記保證同一條 SQL 同時只有一個執行緒正在執行,並且不需要等到每個分片結果都傳回就可以執行聚合邏輯。當然,排序邏輯需要等到所有分片結果都傳回才可以執行。
核心程式碼:
-
AbstractDataNodeMerge.java
-
DataNodeMergeManager.java#run(…)
3.2 DataNodeMergeManager
AbstractDataNodeMerge 有兩種子類實現:
-
DataMergeService:基於堆內記憶體合併分片結果。 -
DataNodeMergeManager:基於堆外記憶體合併分片結果。
目前官方預設配置使用 DataNodeMergeManager。主要有如下優點:
-
可以使用更大的記憶體空間。當併發量大或者資料量大時,更大的記憶體空間意味著更好的效能。
-
減少 GC 暫停時間。記錄行(row)物件小且重用性很低,需要能夠進行類似 C / C++ 的自主記憶體釋放。
-
更快的記憶體複製和讀取速度,對排序和聚合帶來很好的提速。
如果對堆外記憶體不太瞭解,推薦閱讀如下文章:
-
《從0到1起步-跟我進入堆外記憶體的奇妙世界》
-
《堆內記憶體還是堆外記憶體?》
-
《JAVA堆外記憶體》
-
《JVM原始碼分析之堆外記憶體完全解讀》
本文主要分析 DataNodeMergeManager 實現,DataMergeService 可以自己閱讀或者等待後續文章(?歡迎訂閱我的公眾號噢)。
DataNodeMergeManager 有三個元件:
-
globalSorter:UnsafeExternalRowSorter=> 實現記錄行(row)合併併排序邏輯。 -
globalMergeResult:UnsafeExternalRowSorter=> 實現記錄行(row)合併不排序邏輯。 -
unsafeRowGrouper:UnsafeRowGrouper=> 實現記錄行(row)聚合邏輯。
DataNodeMergeManager#run(...) 邏輯如下:
-
[1] 寫入記錄行(row)到
UnsafeRow。 -
[2] 根據情況將
UnsafeRow插入對應元件。 -
[3] 當所有
UnsafeRow插入完後,根據情況使用元件聚合、排序。
| 是否排序 | 是否聚合 | 依賴元件 | [2] | [3] |
|---|---|---|---|---|
| 否 | 否 | globalSorter |
插入 globalSorter |
使用 globalSorter 合併併排序 |
| 是 | 否 | globalMergeResult |
插入 globalMergeResult |
使用 globalMergeResult 合併不排序 |
| 否 | 是 | unsafeRowGrouper + globalSorter |
插入 unsafeRowGrouper 進行聚合 |
使用 globalSorter 合併併排序 |
| 是 | 是 | unsafeRowGrouper + globalMergeResult |
插入 unsafeRowGrouper 進行聚合 |
使用 globalMergeResult 合併不排序 |
核心程式碼:
-
DataNodeMergeManager.java。
?看到這裡,可能很多同學都有點懵逼,問題不大,我們繼續往下瞅。
3.3 UnsafeRow

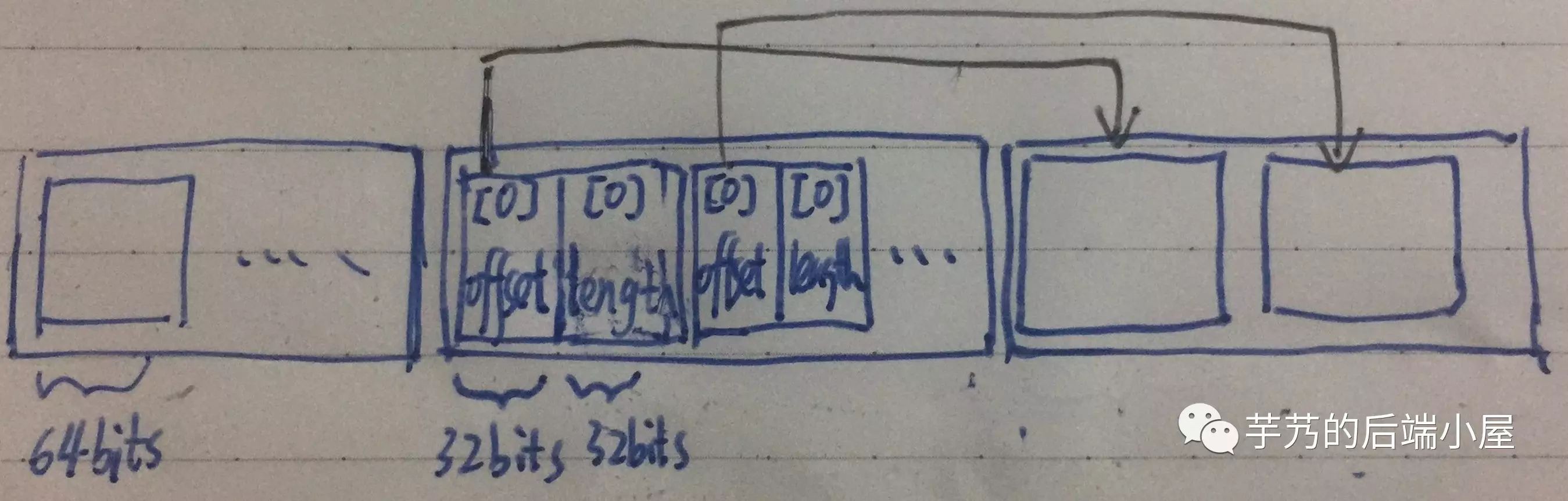
記錄行(row)寫到 UnsafeRow 的 baseObject 屬性,結構如下:

-
拆分成三個區域,每個區域按照格子記錄資訊,每個格子 64bits(8 Bytes)。
-
記錄行(row)按照欄位順序位置記錄到
baseObject。 -
[1] 空標記位區域 :標記欄位對應的值是否為 NULL。
-
當欄位對應的值為 NULL 時,其對應的欄位順序對應的 bit 設定為 1。舉個例子,第 0 個位置欄位為 NULL,則第一個格子對應的 64 bits 從右邊第一個 bit 設定為 1。
-
因為每個格子是 64 bits,每 64 個欄位佔用一個格子,不滿一個格子,按照一個格子計算。因此,該區域的長度(
bitSetWidthInBytes) = 欄位佔用的格子數 * 64 bits。 -
[2] 位置長度區域 :記錄欄位對應的值在
[3]區域所在的位置和長度。 -
每個欄位記錄
[2]區域的位置 =baseOffset+bitSetWidthInBytes+ 8 Bytes * 欄位順序。 -
佔用一個格子,前 32 bits 為
[3]區域的位置,後 32 bits 為欄位對應的值長度。 -
[3] 值區域 :記錄欄位對應的值。
-
每個欄位對應的值佔用格子數 = 欄位對應的值長度 / 8 Byte,如果無法整除再 + 1。
-
因為欄位對應的值可能無法剛好佔滿每個格子,未使用的 bit 用 0 佔位。
寫入 UnsafeRow,MyCAT 可以順序訪問每個欄位,而不需要在記錄行(row)進行遍歷。
?日常開發使用位操作的機會比較少,可能較為難理解,需要反覆理解下,相信會獲得很大啟發。恩,該部分程式碼取用自開源運算框架 Spark,是不是更加有動力列?。
核心程式碼:
-
UnsafeRow.java
-
BufferHolder.java
-
UnsafeRowWriter.java
3.4 UnsafeExternalRowSorter
如果使用 Java 實現 SELECT * FROM student ORDER BY age desc, nickname asc,不考慮演演算法最佳化的情況下,我們可以簡單如下實現:
Collections.sort(students, new Comparator() { @Override
public int compare(Student o1, Student o2) { int cmp = compare(o2.age, o1.age); return cmp != 0 ? cmp : compare(o1.nickname, o2.nickname);
}
}
}); 從功能上,UnsafeExternalRowSorter 是這麼實現排序邏輯。當然肯定的是,不是這麼“簡單”的實現。

UnsafeRow 會寫入到兩個地方:
-
List:記憶體塊陣列。當前MemoryBlock無法容納寫入的UnsafeRow時,生成新的MemoryBlock提供寫入。每條UnsafeRow儲存在MemoryBlock由 長度 + 位元組內容 組成。 -
LongArray:每條UnsafeRow儲存在LongArray由兩部分組成:address + prefix。
-
address:UnsafeRow儲存在List的位置。前 13 bits 記錄所在MemoryBlock的 index,後 51 bit 記錄在MemoryBlock的 offset。 -
prefix:UnsafeRow第一個排序欄位值前 64 bits 計算的值。
UnsafeExternalRowSorter 排序實現方式 :提供 TimSort 和 RadixSort 兩種排序演演算法,前者為預設實現。TimSort 折半查詢時,使用 LongArray,先比較 prefix,若相等,則順序對比每個排序欄位直到不等,提升計算效率。插入操作在 LongArray 操作,List 只作為原始資料。
另外,當需要排序特別大的資料量時,會使用儲存資料到檔案進行排序。限於筆者暫時未閱讀該處原始碼,後續會另開文章分析。?
核心原始碼:
-
UnsafeExternalRowSorter.java
-
UnsafeExternalRowSorter.java
-
TimSort.java
3.5 UnsafeRowGrouper
如果使用 Java 實現 SELECT nickname, COUNT(*) FROM student group by nickname,不考慮演演算法最佳化的情況下,我們可以簡單如下實現:
Map> map = new HashMap<>();// 聚合for (student : students) { if (map.contains(student.nickname)) {
map.put(student.nickname, map.get(student.nickname).get(1) + 1);
} else {
List 從功能上,UnsafeRowGrouper 是這麼實現排序邏輯。當然肯定的是,也不是這麼“簡單”的實現。
?具體怎麼實現的呢?我們在《MyCAT 原始碼解析 —— 分片結果合併(二)》繼續分析。
4. 救護中心
看到此處的應該是真愛吧?!如果內容上有什麼錯誤或者難懂的地方,可以關註我的微信公眾號給我留言,我會很認真的逐條解答的。“萬一”覺得本文還可以,希望轉發到朋友圈讓更多的人看到。
最後的最後,感謝耐心閱讀本文的同學!

