小編邀請您,先思考:
1 邏輯回歸演演算法的原理是什麼?
2 邏輯回歸演演算法的有哪些應用?
邏輯回歸(Logistic Regression)是機器學習中的一種分類模型,由於演演算法的簡單和高效,在實際中應用非常廣泛。本文作為美團機器學習InAction系列中的一篇,主要關註邏輯回歸演演算法的數學模型和引數求解方法,最後也會簡單討論下邏輯回歸和貝葉斯分類的關係,以及在多分類問題上的推廣。
邏輯回歸
問題
實際工作中,我們可能會遇到如下問題:
-
預測一個使用者是否點選特定的商品
-
判斷使用者的性別
-
預測使用者是否會購買給定的品類
-
判斷一條評論是正面的還是負面的
這些都可以看做是分類問題,更準確地,都可以看做是二分類問題。同時,這些問題本身對美團也有很重要的價值,能夠幫助我們更好的瞭解我們的使用者,服務我們的使用者。要解決這些問題,通常會用到一些已有的分類演演算法,比如邏輯回歸,或者支援向量機。它們都屬於有監督的學習,因此在使用這些演演算法之前,必須要先收集一批標註好的資料作為訓練集。有些標註可以從log中拿到(使用者的點選,購買),有些可以從使用者填寫的資訊中獲得(性別),也有一些可能需要人工標註(評論情感極性)。另一方面,知道了一個使用者或者一條評論的標簽後,我們還需要知道用什麼樣的特徵去描述我們的資料,對使用者來說,可以從使用者的瀏覽記錄和購買記錄中獲取相應的統計特徵,而對於評論來說,最直接的則是文字特徵。這樣拿到資料的特徵和標簽後,就得到一組訓練資料:

其中 xi是一個 m維的向量,xi=[xi1,xi2,…,xim],y 在 {0, 1} 中取值。(本文用{1,0}表示正例和負例,後文沿用此定義。)
我們的問題可以簡化為,如何找到這樣一個決策函式y∗=f(x)
值得一提的是,模型效果往往和所用特徵密切相關。特徵工程在任何一個實用的機器學習系統中都是必不可少的,機器學習InAction系列已有一篇文章中對此做了詳細的介紹,本文不再詳細展開。
模型
sigmoid 函式
在介紹邏輯回歸模型之前,我們先引入sigmoid函式,其數學形式是:
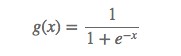
對應的函式曲線如下圖所示:
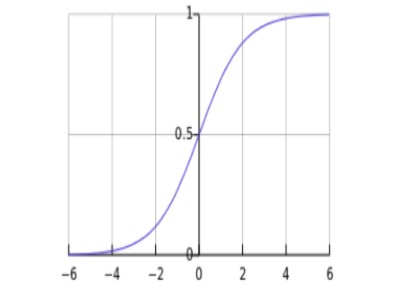
從上圖可以看到sigmoid函式是一個s形的曲線,它的取值在[0, 1]之間,在遠離0的地方函式的值會很快接近0/1。這個性質使我們能夠以機率的方式來解釋(後邊延伸部分會簡單討論為什麼用該函式做機率建模是合理的)。
決策函式
一個機器學習的模型,實際上是把決策函式限定在某一組條件下,這組限定條件就決定了模型的假設空間。當然,我們還希望這組限定條件簡單而合理。而邏輯回歸模型所做的假設是:
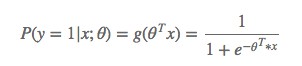
這裡的 g(h)是上邊提到的 sigmoid 函式,相應的決策函式為:

選擇0.5作為閾值是一個一般的做法,實際應用時特定的情況可以選擇不同閾值,如果對正例的判別準確性要求高,可以選擇閾值大一些,對正例的召回要求高,則可以選擇閾值小一些。
引數求解
模型的數學形式確定後,剩下就是如何去求解模型中的引數。統計學中常用的一種方法是最大似然估計,即找到一組引數,使得在這組引數下,我們的資料的似然度(機率)越大。在邏輯回歸模型中,似然度可表示為:

取對數可以得到對數似然度:
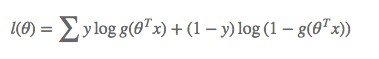
另一方面,在機器學習領域,我們更經常遇到的是損失函式的概念,其衡量的是模型預測錯誤的程度。常用的損失函式有0-1損失,log損失,hinge損失等。其中log損失在單個資料點上的定義為
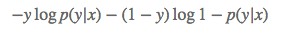
如果取整個資料集上的平均log損失,我們可以得到

即在邏輯回歸模型中,我們最大化似然函式和最小化log損失函式實際上是等價的。對於該最佳化問題,存在多種求解方法,這裡以梯度下降的為例說明。梯度下降(Gradient Descent)又叫作最速梯度下降,是一種迭代求解的方法,透過在每一步選取使標的函式變化最快的一個方向調整引數的值來逼近最優值。基本步驟如下:
-
選擇下降方向(梯度方向,∇J(θ)
-
選擇步長,更新引數 θi=θi−1−αi∇J(θi−1)
-
重覆以上兩步直到滿足終止條件

其中損失函式的梯度計算方法為:
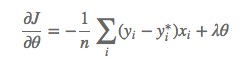
沿梯度負方向選擇一個較小的步長可以保證損失函式是減小的,另一方面,邏輯回歸的損失函式是凸函式(加入正則項後是嚴格凸函式),可以保證我們找到的區域性最優值同時是全域性最優。此外,常用的凸最佳化的方法都可以用於求解該問題。例如共軛梯度下降,牛頓法,LBFGS等。
分類邊界
知道如何求解引數後,我們來看一下模型得到的最後結果是什麼樣的。很容易可以從sigmoid函式看出,當θTx>0
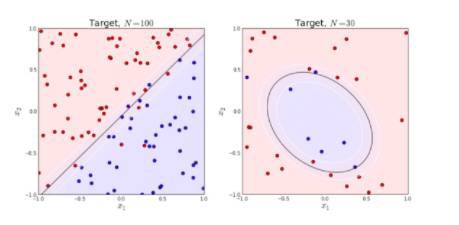
左圖是一個線性可分的資料集,右圖在原始空間中線性不可分,但是在特徵轉換 [x1,x2]=>[x1,x2,x21,x22,x1x2]後的空間是線性可分的,對應的原始空間中分類邊界為一條類橢圓曲線。
正則化
當模型的引數過多時,很容易遇到過擬合的問題。這時就需要有一種方法來控制模型的複雜度,典型的做法在最佳化標的中加入正則項,透過懲罰過大的引數來防止過擬合:

一般情況下,取p=1
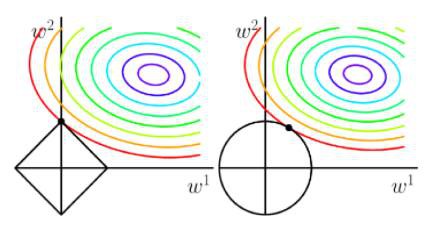
實際應用時,由於我們資料的維度可能非常高,L1正則化因為能產生稀疏解,使用的更為廣泛一些。
延伸
生成模型和判別模型
邏輯回歸是一種判別模型,表現為直接對條件機率P(y|x)建模,而不關心背後的資料分佈P(x,y)。而高斯貝葉斯模型(Gaussian Naive Bayes)是一種生成模型,先對資料的聯合分佈建模,再透過貝葉斯公式來計算樣本屬於各個類別的後驗機率,即:

通常假設P(x|y)是高斯分佈,P(y)是多項式分佈,相應的引數都可以透過最大似然估計得到。如果我們考慮二分類問題,透過簡單的變化可以得到:
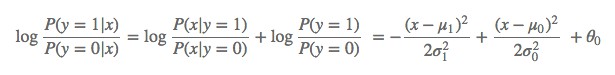
如果 σ1=σ0,二次項會抵消,我們得到一個簡單的線性關係:

由上式進一步可以得到:
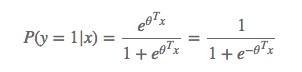
可以看到,這個機率和邏輯回歸中的形式是一樣的。這種情況下GNB 和 LR 會學習到同一個模型。實際上,在更一般的假設(P(x|y)的分佈屬於指數分佈族)下,我們都可以得到類似的結論。
多分類(softmax)
如果y

而決策函式為:y∗=argmaxiP(y=i|x,θ)
對應的損失函式為:
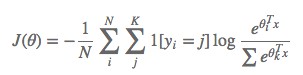
類似的,我們也可以透過梯度下降或其他高階方法來求解該問題,這裡不再贅述。
應用
本文開始部分提到了幾個在實際中遇到的問題,這裡以預測使用者對品類的購買偏好為例,介紹一下美團是如何用邏輯回歸解決工作中問題的。該問題可以轉換為預測使用者在未來某個時間段是否會購買某個品類,如果把會購買標記為1,不會購買標記為0,就轉換為一個二分類問題。我們用到的特徵包括使用者在美團的瀏覽,購買等歷史資訊,見下表

其中提取的特徵的時間跨度為30天,標簽為2天。生成的訓練資料大約在7000萬量級(美團一個月有過行為的使用者),我們人工把相似的小品類聚合起來,最後有18個較為典型的品類集合。如果使用者在給定的時間內購買某一品類集合,就作為正例。喲了訓練資料後,使用Spark版的LR演演算法對每個品類訓練一個二分類模型,迭代次數設為100次的話模型訓練需要40分鐘左右,平均每個模型2分鐘,測試集上的AUC也大多在0.8以上。訓練好的模型會儲存下來,用於預測在各個品類上的購買機率。預測的結果則會用於推薦等場景。
由於不同品類之間正負例分佈不同,有些品類正負例分佈很不均衡,我們還嘗試了不同的取樣方法,最終標的是提高下單率等線上指標。經過一些引數調優,品類偏好特徵為推薦和排序帶來了超過1%的下單率提升。
此外,由於LR模型的簡單高效,易於實現,可以為後續模型最佳化提供一個不錯的baseline,我們在排序等服務中也使用了LR模型。
總結
邏輯回歸的數學模型和求解都相對比較簡潔,實現相對簡單。透過對特徵做離散化和其他對映,邏輯回歸也可以處理非線性問題,是一個非常強大的分類器。因此在實際應用中,當我們能夠拿到許多低層次的特徵時,可以考慮使用邏輯回歸來解決我們的問題。
參考資料
-
Trevor Hastie et al. The elements of statistical learning
-
Andrew Ng, CS 229 lecture notes
-
C.M. Bishop, Pattern recognition and machine learning
-
Andrew Ng et al. On discriminative vs. generative classifiers:a comparison of logistic regression and naïve bayes
-
Wikipedia, http://en.wikipedia.org/wiki/Logistic_regression
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
好又樂書屋,專註分享有思想的人物,身心健康,自我教育,閱讀寫作和有趣味的生活等內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
