來源:MSSQL123
www.cnblogs.com/wy123/p/8419707.html
資料庫中的統計資訊在不同(精確)程度上描述了表中資料的分佈情況,執行計劃透過統計資訊獲取符合查詢條件的資料大小(行數),來指導執行計劃的生成。
在以Oracle和SQLServer為代表的商業資料庫,和以開源的PostgreSQL為代表的資料庫中,直方圖是統計資訊的一個重要組成部分。
在生成執行計劃的時候,透過統計資訊以及統計資訊的直方圖來預估符合條件的資料行數,從而影響執行計劃的生成。
統計資訊對執行計劃的影響,具體體現在:索引的查詢與掃描,多表連線時表之間的驅動順序,表之間的JOIN方式,以及對sql查詢陳述句的資源分配等等。
但是在MySQL資料庫中,執行計劃的方式相對簡單,表之間的JOIN只有LOOPJOIN一種方式,且沒有並行執行計劃等,也就說透過預估結果集的行數對執行計劃的影響有限。
但是對於某些情況,依舊需要預估的方式來指導執行計劃的生成,比如常見的多表連線時驅動順序,多數情況下是小表驅動大表(不完全一定)的方式來實現查詢的,因此MySQL中一樣需要預估來指導執行計劃的生成。
不過MySQL中的統計資訊相對來說簡單很多,只有一個cardinality資訊來預估索引的選擇性(show index from table),索引統計資訊不包含直方圖的資訊,非索引列也不會生成直方圖,也就是無法透過直方圖來預估查詢資料的大小,mysql是透過其他方式來實現預估的。
對於有直方圖的資料來說,直方圖為預估提供了重要的依據,對於沒有直方圖的MySQL,執行計劃是如何預估的?預估的準確性有如何?
筆者在研究這個問題的時候,一開始也遇到不少疑惑的地方,還是看了部落格園大神的問題才得以釋惑,後面會給出連結。
首先透過例子,透過一個非常簡單的查詢來觀察一個有意思的現象。
新建測試表,測試表如下:
create table test_statistics
(
id int auto_increment primary key,
col2 varchar(200),
col3 varchar(200),
create_date datetime,
index idx_create_date(create_date)
)ENGINE=InnoDB;
儲存過程透過迴圈插入資料,呼叫儲存過程生成100W行資料(100W行的資料,在實際應用中已經是一個非常小的資料量了),create_date欄位上生成一個範圍之內的隨機時間。
CREATE DEFINER=`root`@`%` PROCEDURE `p_insert_test_data`(
IN `loop_count` INT
)
BEGIN
declare i int;
while (loop_count>0)
do
insert into test_statistics(col2,col3,create_date) values (uuid(),uuid(), DATE_ADD(sysdate(), INTERVAL -rand()*2400 hour));
set loop_count = loop_count -1;
end while;
END
寫入測試資料完成之後,進行如下兩個查詢做測試。
簡單地使用select count(1)的來做測試
首先看第一個查詢:查詢的時間範圍是: where create_date>’2017-11-01 12:00:00′ and create_date
可以發現:explain預估的行數,與實際行數完全一致。
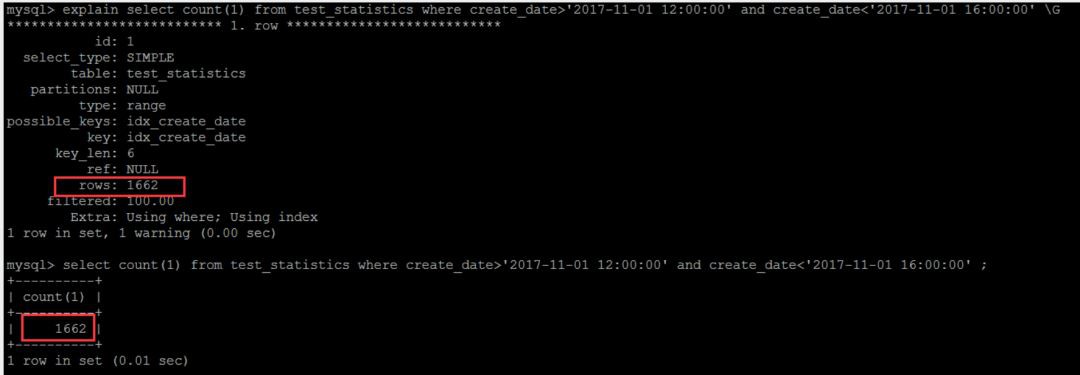
繼續第二個查詢,擴大查詢的時間範圍,查詢的時間範圍是:where create_date>’2017-11-01 12:00:00′ and create_date
可以發現,此時的explain執行計劃的預估,與實際行數出現了嚴重的偏差

為什麼第一個查詢做到了精確的預估,而第二個查詢的預估出現嚴重的偏差?
這一點要從預估的計算方式入手來說。
首先,第一個查詢和第二個查詢,唯一的不同是,第二個查詢的時間範圍放寬了,為什麼時間放寬之後,執行計劃的預估的準確性就大大下降?
既然是“預估”,就一定是存在誤差,只不過是誤差大與小的問題,誤差的大下與具體的預估的方式有關。
任何預估的實現,都是以一種在不同程度上“以偏概全”的方式進行的,比如SQL Server是以對相關資料page的透過某種百分比來取樣,然後儲存在直方圖中做預估依據的。
當然,這種“以偏概全”的預估方式,是在效能與精確度之間權衡折中的結果。
在考慮收集統計資訊對效能和資源影響的前提下,預估策略各種方式或者代價盡可能減少對預估產生誤差的因素,關於直方圖的生成這裡不細說。
對於沒有直方圖的MySQL,它是是在執行的時候,透過掃描符合查詢條件的部分資料頁後做預估統計的。
MySQL是在查詢的時候,直接對查詢條件範圍內的資料頁,取一定比例樣本做統計之後預估的,但是這裡取樣的資料頁面有一定的限制,不會無限制取樣做統計預估。
如果符合條件的資料頁超出了預定的範圍,則會取部分頁進行預估,而不是全部頁(為什麼不是全部樣做統計預估,原因就不用說了吧)。
比如下圖中,不管是聚集索引還是二級索引(非聚集索引),理論上說都是一顆平衡樹,暫不探究其細節。
假如符合條件的資料是一個範圍,位於兩個矩形框之間。矩形框分別是範圍的左右節點,中間可以想象成多個葉子節點
參考zhanlijun大神的文章,
https://www.cnblogs.com/LBSer/p/3333881.html
上述參考連結中得知,MySQL在5.5之後的預估原理如下:
其預估掃描的資料頁分別是前後兩個資料頁,以及從左邊開始連續8個資料頁,得到平均每個page的行數,根據總的page個數預估出這個範圍的資料行數。
具體說,也就是取左右兩個葉子節點,以及從左葉子節點開始連續8個頁的資料做統計,中間可能有多個資料頁,但也會被忽略,這就是上面提到的“以偏概全”的方式。
這裡面就存在一個最明顯的問題,也就是符合條件的資料頁面與預估時候採集的頁面的大小關係。
如果符合條件的資料頁的分佈少於10個,當然在預估的時候,會全部掃描這些page,當然預估是完全精確的,這也是第一個查詢執行計劃預估的實際行數完全不一致的原因。
如果符合條件的資料頁的分佈大於10個,當然在預估的時候,會部分掃描這些page,預估的誤差情況就此產生,這也是第二個查詢執行計劃預估的實際行數差異較大的原因。

當然MySQL的每個版本可能都有所改進或者差異,筆者並沒有從原始碼中找到具體的演演算法,當前測試的是5.7.20版本。
但目前仍不清楚,
-
在create_date欄位上,時間是按照DATE_ADD(sysdate(), INTERVAL -rand()*2400 hour)生成的,從整體分佈看,基本按照時間均勻分佈的.
理論上根據這種方式推到,得到的預估結果偏差應該不會很大,但尚不清楚為什麼預估與實際存在如此大的差異。
-
嘗試找到預估值從精確到產生差異的臨界點,透過查詢實際行數,根據key_len的值以及B樹索引的儲存原理(二級索引葉子節點儲存的二級索引的key值+聚集索引的key值).
理論上計算出來當前查詢一個大概的取樣的page個數,發現這個值預報理論上的10個page差異較大,可能是推到方式有問題,或者是MySQL預估本身有一些不知道的細節問題。
-
沒有詳細翻MySQL的原始碼,尚未找到具體的實現細節。
對於有直方圖的資料庫來說,直方圖的資訊也不是沒有代價,或者是萬能的,直方圖也有直方圖的侷限性,這裡暫不表述。
對於尚沒有直方圖的MySQL資料庫來說,其預估原理是每次查詢的時候進行對相關的資料頁面進行取樣預估的,而不是從直方圖中獲取到預估資訊的,這是一個很消耗效能的操作。
詳情參考:
http://www.orczhou.com/index.php/2013/04/how-mysql-choose-index-in-a-join/
這可能會導致MySQL不適合做較大資料量或者較為複雜的JOIN操作,當然這也取決於具體的業務設計方案以及對資料的依賴程度,或者主觀上的查詢提示操作。
說這句話是冒著被MySQL的大神以及粉絲們怒噴的風險的。
關於MySQL的預估的知識點,搜尋到的文章並不是很多,也拘泥於個人的認識有限,也希望對這方面有關註的大神多多指點。
據說MySQL在8.0之後的版本中會加入直方圖資訊,以及其他JOIN方式(除了LOOP JOIN),這可能對效能上有比較大的幫助。
參考連結
-
https://www.cnblogs.com/LBSer/p/3333881.html
-
http://www.orczhou.com/index.php/2013/04/how-mysql-choose-index-in-a-join/
●本文編號290,以後想閱讀這篇文章直接輸入290即可
●輸入m獲取到文章目錄

Web開發
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
