
一文詳解資料科學家的必備技能(附學習資源)
導讀:本文為你詳細分析資料科學家最需要掌握的普通技能以及特定語言和工具的特殊技能。 作者:Jeff Hale 翻譯:陳之炎 來源:資料派THU(ID:DatapiTHU) 資料科學家需要涉獵的知識面很廣,包括:機器學習、電腦科學、統計學、...
導讀:本文為你詳細分析資料科學家最需要掌握的普通技能以及特定語言和工具的特殊技能。 作者:Jeff Hale 翻譯:陳之炎 來源:資料派THU(ID:DatapiTHU) 資料科學家需要涉獵的知識面很廣,包括:機器學習、電腦科學、統計學、...
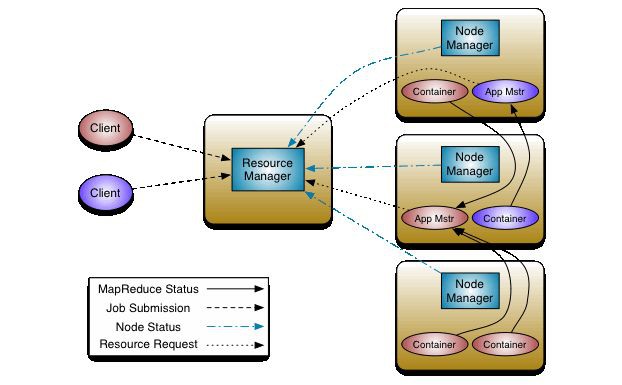
作者: 哈爾的資料城堡 / 佘志銘 (本文來自作者投稿) 在古老的 Hadoop1.0 中,MapReduce 的 JobTracker 負責了太多的工作,包括資源排程,管理眾多的 TaskTracker 等工作。這自然是不合理的,於是 ...

資料科學與大資料技術是一門偏嚮應用的學科領域,因此工具就成為重要的組成部分。在工作中,資料科學家如果選擇有效的工具會帶來事半功倍的效果。一般來說,資料科學家應該具有運算元據庫、資料處理和資料視覺化等相關技能,還有很多人還認為計算機技能也是不...
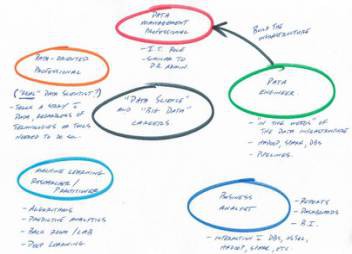
翻譯:盧苗苗、梁傅淇;校對:呂艷芹;作者:Matthew Mayo 原文連結:http://www.kdnuggets.com/2017/02/5-career-paths-data-science-big-data-explained.h...
我們看到開源社群開始紛紛將左版調到最高音量來應對過去所沒有出現過的市場環境 — 華創資本 謝佳 致謝 轉自 | zhuanlan.zhihu.com 作者 | 華創資本 謝佳 最近開源界還發生了一系列有代表性的事件...
當提起這三個詞的時候,是不是很多人都認為分散式=高併發=多執行緒? 當面試官問到高併發系統可以採用哪些手段來解決,或者被問到分散式系統如何解決一致性的問題,是不是一臉懵逼? 確實,在一開始接觸的時候,不少人都會將三者混淆,誤以為所謂的分...

前段時間,IBM進行了儲存新品Flashsystem 9100的釋出會,IBM的合作伙伴及使用者們提出了很多專業性問題。以下是由IBM專家朱軍彙編的直播交流問答,有助於大家瞭解這一新儲存與其他儲存的區別,以及各方面效能指標和技術特性。 1...

如果你們公司已經準備全面使用Kubernetes編排管理器,而你為了方便部署正在找尋一個包管理工具,那麼你可能會傾向於選擇Helm,一個正在雲原生計算基金會(CNCF)孵化的開源專案。 你有可能還希望從推廣容器的公司瞭解Doc...

前幾天,網易雲音樂公佈了一份年度音樂總結。 結果中有暖心的,自然也有扎心的。 然而,讓我更驚嘆的是在這個大資料時代底下,比起我們自己,大資料似乎更懂得我們。 如果科技更進一步,就像《奇葩說》中一集辯題裡所說的,它有可能可以幫我們匹配到那個靈...

終於按時完成第二篇。本來準備著手講一些實踐,但是資料庫部分沒有講到,部分實踐會存在一些問題,於是就有了此篇以及後續——資料庫容器化。本篇將從SQL Server容器化實踐開始,並逐步講解其他資料庫的容器化實踐,中間再穿插一些知識點和實踐細節...