
作者 | Vivek Gite
譯者 | jessie-pang ? ? 共計翻譯:7 篇 貢獻時間:42 天
您需要監控 Linux 伺服器的效能嗎?試試用這些內建命令和附加工具吧!大多數 Linux 發行版都附帶了大量的監控工具。這些工具提供了獲取系統活動的相關指標。您可以使用這些工具來查詢效能問題的可能原因。本文提到的是一些基本的命令,用於系統分析和伺服器除錯等,例如:
1. top – 行程活動監控命令
top 命令會顯示 Linux 的行程。它提供了一個執行中系統的實時動態檢視,即實際的行程活動。預設情況下,它顯示在伺服器上執行的 CPU 佔用率最高的任務,並且每五秒更新一次。

圖 01:Linux top 命令
top 的常用快捷鍵
常用快捷鍵串列:
| 快捷鍵 | 用法 |
|---|---|
t |
是否顯示彙總資訊 |
m |
是否顯示記憶體資訊 |
A |
根據各種系統資源的利用率對行程進行排序,有助於快速識別系統中效能不佳的任務。 |
f |
進入 top 的互動式配置螢幕,用於根據特定的需求而設定 top 的顯示。 |
o |
互動式地調整 top 每一列的順序。 |
r |
調整優先順序(renice) |
k |
殺掉行程(kill) |
z |
切換彩色或黑白樣式 |
相關連結:Linux 如何檢視 CPU 利用率?[1]
2. vmstat – 虛擬記憶體統計
vmstat 命令報告有關行程、記憶體、分頁、塊 IO、中斷和 CPU 活動等資訊。
# vmstat 3
輸出示例:
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 2540988 522188 5130400 0 0 2 32 4 2 4 1 96 0 0
1 0 0 2540988 522188 5130400 0 0 0 720 1199 665 1 0 99 0 0
0 0 0 2540956 522188 5130400 0 0 0 0 1151 1569 4 1 95 0 0
0 0 0 2540956 522188 5130500 0 0 0 6 1117 439 1 0 99 0 0
0 0 0 2540940 522188 5130512 0 0 0 536 1189 932 1 0 98 0 0
0 0 0 2538444 522188 5130588 0 0 0 0 1187 1417 4 1 96 0 0
0 0 0 2490060 522188 5130640 0 0 0 18 1253 1123 5 1 94 0 0
顯示 Slab 快取的利用率
# vmstat -m
獲取有關活動和非活動記憶體頁面的資訊
# vmstat -a
相關連結:如何檢視 Linux 的資源利用率從而找到系統瓶頸?[2]
3. w – 找出登入的使用者以及他們在做什麼
w 命令[3] 顯示了當前登入在該系統上的使用者及其行程。
# w username
# w vivek
輸出示例:
17:58:47 up 5 days, 20:28, 2 users, load average: 0.36, 0.26, 0.24
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 10.1.3.145 14:55 5.00s 0.04s 0.02s vim /etc/resolv.conf
root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
4. uptime – Linux 系統運行了多久
uptime 命令可以用來檢視伺服器運行了多長時間:當前時間、已執行的時間、當前登入的使用者連線數,以及過去 1 分鐘、5 分鐘和 15 分鐘的系統負載平均值。
# uptime
輸出示例:
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
1 可以被認為是最佳負載值。不同的系統會有不同的負載:對於單核 CPU 系統來說,1 到 3 的負載值是可以接受的;而對於 SMP(對稱多處理)系統來說,負載可以是 6 到 10。
5. ps – 顯示系統行程
ps 命令顯示當前執行的行程。要顯示所有的行程,請使用 -A 或 -e 選項:
# ps -A
輸出示例:
PID TTY TIME CMD
1 ? 00:00:02 init
2 ? 00:00:02 migration/0
3 ? 00:00:01 ksoftirqd/0
4 ? 00:00:00 watchdog/0
5 ? 00:00:00 migration/1
6 ? 00:00:15 ksoftirqd/1
....
.....
4881 ? 00:53:28 java
4885 tty1 00:00:00 mingetty
4886 tty2 00:00:00 mingetty
4887 tty3 00:00:00 mingetty
4888 tty4 00:00:00 mingetty
4891 tty5 00:00:00 mingetty
4892 tty6 00:00:00 mingetty
4893 ttyS1 00:00:00 agetty
12853 ? 00:00:00 cifsoplockd
12854 ? 00:00:00 cifsdnotifyd
14231 ? 00:10:34 lighttpd
14232 ? 00:00:00 php-cgi
54981 pts/0 00:00:00 vim
55465 ? 00:00:00 php-cgi
55546 ? 00:00:00 bind9-snmp-stat
55704 pts/1 00:00:00 ps
ps 與 top 類似,但它提供了更多的資訊。
顯示長輸出格式
# ps -Al
顯示完整輸出格式(它將顯示傳遞給行程的命令列引數):
# ps -AlF
顯示執行緒(輕量級行程(LWP)和執行緒的數量(NLWP))
# ps -AlFH
在行程後顯示執行緒
# ps -AlLm
顯示系統上所有的行程
# ps ax
# ps axu
顯示行程樹
# ps -ejH
# ps axjf
# pstree
顯示行程的安全資訊
# ps -eo euser,ruser,suser,fuser,f,comm,label
# ps axZ
# ps -eM
顯示指定使用者(如 vivek)執行的行程
# ps -U vivek -u vivek u
設定使用者自定義的輸出格式
# ps -eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm
# ps axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
# ps -eopid,tt,user,fname,tmout,f,wchan
顯示某行程(如 lighttpd)的 PID
# ps -C lighttpd -o pid=
或
# pgrep lighttpd
或
# pgrep -u vivek php-cgi
顯示指定 PID(如 55977)的行程名稱
# ps -p 55977 -o comm=
找出佔用記憶體資源最多的前 10 個行程
# ps -auxf | sort -nr -k 4 | head -10
找出佔用 CPU 資源最多的前 10 個行程
# ps -auxf | sort -nr -k 3 | head -10
相關連結:顯示 Linux 上所有執行的行程[4]
6. free – 記憶體使用情況
free 命令顯示了系統的可用和已用的物理記憶體及交換記憶體的總量,以及核心用到的快取空間。
# free
輸出示例:
total used free shared buffers cached
Mem: 12302896 9739664 2563232 0 523124 5154740
-/+ buffers/cache: 4061800 8241096
Swap: 1052248 0 1052248
相關連結: 1. 獲取 Linux 的虛擬記憶體的記憶體頁大小(PAGESIZE)[5] 2. 限制 Linux 每個行程的 CPU 使用率[6] 3. 我的 Ubuntu 或 Fedora Linux 系統有多少記憶體?[7]
7. iostat – CPU 平均負載和磁碟活動
iostat 命令用於彙報 CPU 的使用情況,以及裝置、分割槽和網路檔案系統(NFS)的 IO 統計資訊。
# iostat
輸出示例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
avg-cpu: %user %nice %system %iowait %steal %idle
3.50 0.09 0.51 0.03 0.00 95.86
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 22.04 31.88 512.03 16193351 260102868
sda1 0.00 0.00 0.00 2166 180
sda2 22.04 31.87 512.03 16189010 260102688
sda3 0.00 0.00 0.00 1615 0
相關連結:如何跟蹤 Linux 系統的 NFS 目錄或磁碟的 IO 負載情況[8]
8. sar - 監控、收集和彙報系統活動
sar 命令用於收集、彙報和儲存系統活動資訊。要檢視網路統計,請輸入:
# sar -n DEV | more
顯示 24 日的網路統計:
# sar -n DEV -f /var/log/sa/sa24 | more
您還可以使用 sar 顯示實時使用情況:
# sar 4 5
輸出示例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:45:12 PM CPU %user %nice %system %iowait %steal %idle
06:45:16 PM all 2.00 0.00 0.22 0.00 0.00 97.78
06:45:20 PM all 2.07 0.00 0.38 0.03 0.00 97.52
06:45:24 PM all 0.94 0.00 0.28 0.00 0.00 98.78
06:45:28 PM all 1.56 0.00 0.22 0.00 0.00 98.22
06:45:32 PM all 3.53 0.00 0.25 0.03 0.00 96.19
Average: all 2.02 0.00 0.27 0.01 0.00 97.70
相關連結:
9. mpstat - 監控多處理器的使用情況
mpstat 命令顯示每個可用處理器的使用情況,編號從 0 開始。命令 mpstat -P ALL顯示了每個處理器的平均使用率:
# mpstat -P ALL
輸出示例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04
06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31
06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93
06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00
06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80
06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91
06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98
06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75
06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69 76.89
相關連結:多處理器的 Linux 上單獨顯示每個 CPU 的使用率[11].
10. pmap - 監控行程的記憶體使用情況
pmap 命令用以顯示行程的記憶體對映,使用此命令可以查詢記憶體瓶頸。
# pmap -d PID
顯示 PID 為 47394 的行程的記憶體資訊,請輸入:
# pmap -d 47394
輸出示例:
47394: /usr/bin/php-cgi
Address Kbytes Mode Offset Device Mapping
0000000000400000 2584 r-x-- 0000000000000000 008:00002 php-cgi
0000000000886000 140 rw--- 0000000000286000 008:00002 php-cgi
00000000008a9000 52 rw--- 00000000008a9000 000:00000 [ anon ]
0000000000aa8000 76 rw--- 00000000002a8000 008:00002 php-cgi
000000000f678000 1980 rw--- 000000000f678000 000:00000 [ anon ]
000000314a600000 112 r-x-- 0000000000000000 008:00002 ld-2.5.so
000000314a81b000 4 r---- 000000000001b000 008:00002 ld-2.5.so
000000314a81c000 4 rw--- 000000000001c000 008:00002 ld-2.5.so
000000314aa00000 1328 r-x-- 0000000000000000 008:00002 libc-2.5.so
000000314ab4c000 2048 ----- 000000000014c000 008:00002 libc-2.5.so
.....
......
..
00002af8d48fd000 4 rw--- 0000000000006000 008:00002 xsl.so
00002af8d490c000 40 r-x-- 0000000000000000 008:00002 libnss_files-2.5.so
00002af8d4916000 2044 ----- 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b15000 4 r---- 0000000000009000 008:00002 libnss_files-2.5.so
00002af8d4b16000 4 rw--- 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b17000 768000 rw-s- 0000000000000000 000:00009 zero (deleted)
00007fffc95fe000 84 rw--- 00007ffffffea000 000:00000 [ stack ]
ffffffffff600000 8192 ----- 0000000000000000 000:00000 [ anon ]
mapped: 933712K writeable/private: 4304K shared: 768000K
最後一行非常重要:
mapped: 933712K 對映到檔案的記憶體量writeable/private: 4304K 私有地址空間shared: 768000K 此行程與其他行程共享的地址空間相關連結:使用 pmap 命令檢視 Linux 上單個程式或行程使用的記憶體[12]
11. netstat - Linux 網路統計監控工具
netstat 命令顯示網路連線、路由表、介面統計、偽裝連線和多播連線等資訊。
# netstat -tulpn
# netstat -nat
12. ss - 網路統計
ss 命令用於獲取套接字統計資訊。它可以顯示類似於 netstat 的資訊。不過 netstat 幾乎要過時了,ss 命令更具優勢。要顯示所有 TCP 或 UDP 套接字:
# ss -t -a
或
# ss -u -a
顯示所有帶有 SELinux 安全背景關係的 TCP 套接字:
# ss -t -a -Z
請參閱以下關於 ss 和 netstat 命令的資料:
13. iptraf - 獲取實時網路統計資訊
iptraf 命令是一個基於 ncurses 的互動式 IP 網路監控工具。它可以生成多種網路統計資訊,包括 TCP 資訊、UDP 計數、ICMP 和 OSPF 資訊、乙太網負載資訊、節點統計資訊、IP 校驗錯誤等。它以簡單的格式提供了以下資訊:

圖 02:常規介面統計:基於網路介面的 IP 流量統計

圖 03:基於 TCP 連線的網路流量統計
相關連結:在 Centos / RHEL / Fedora Linux 上安裝 IPTraf 以獲取網路統計資訊[15]
14. tcpdump - 詳細的網路流量分析
tcpdump 命令是簡單的分析網路通訊的命令。您需要充分瞭解 TCP/IP 協議才便於使用此工具。例如,要顯示有關 DNS 的流量資訊,請輸入:
# tcpdump -i eth1 'udp port 53'
檢視所有去往和來自埠 80 的 IPv4 HTTP 資料包,僅列印真正包含資料的包,而不是像 SYN、FIN 和僅含 ACK 這類的資料包,請輸入:
# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
顯示所有標的地址為 202.54.1.5 的 FTP 會話,請輸入:
# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'
列印所有標的地址為 192.168.1.5 的 HTTP 會話:
# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'
使用 wireshark[16] 檢視檔案的詳細內容,請輸入:
# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80
15. iotop - I/O 監控
iotop 命令利用 Linux 核心監控 I/O 使用情況,它按行程或執行緒的順序顯示 I/O 使用情況。
$ sudo iotop
輸出示例:

iotop monitoring linux disk read write IO
相關連結:Linux iotop:什麼行程在增加硬碟負載[17]
16. htop - 互動式的行程檢視器
htop 是一款免費並開源的基於 ncurses 的 Linux 行程檢視器。它比 top 命令更簡單易用。您無需使用 PID、無需離開 htop 介面,便可以殺掉行程或調整其排程優先順序。
$ htop
輸出示例:

htop process viewer for Linux
相關連結:CentOS / RHEL:安裝 htop——互動式文字樣式行程檢視器[18]
17. atop - 高階版系統與行程監控工具
atop 是一個非常強大的互動式 Linux 系統負載監控器,它從效能的角度顯示最關鍵的硬體資源資訊。您可以快速檢視 CPU、記憶體、磁碟和網路效能。它還可以從行程的級別顯示哪些行程造成了相關 CPU 和記憶體的負載。
$ atop
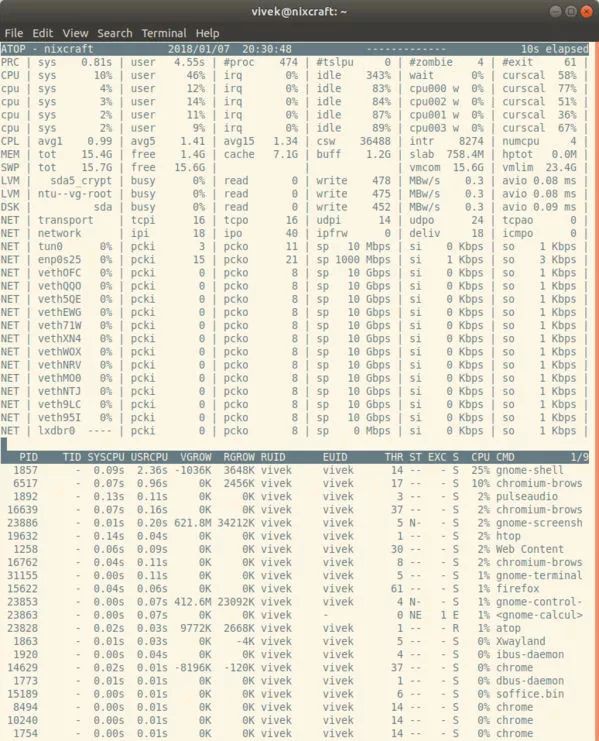
atop Command Line Tools to Monitor Linux Performance
相關連結:CentOS / RHEL:安裝 atop 工具——高階系統和行程監控器[19]
18. ac 和 lastcomm
您一定需要監控 Linux 伺服器上的行程和登入活動吧。psacct 或 acct 軟體包中包含了多個用於監控行程活動的工具,包括:
ac 命令:顯示有關使用者連線時間的統計資訊accton 命令:開啟或關閉行程賬號記錄功能sa 命令:行程賬號記錄資訊的摘要相關連結:如何對 Linux 系統的活動做詳細的跟蹤記錄[21]
19. monit - 行程監控器
monit 是一個免費且開源的行程監控軟體,它可以自動重啟停掉的服務。您也可以使用 Systemd、daemontools 或其他類似工具來達到同樣的目的。本教程演示如何在 Debian 或 Ubuntu Linux 上安裝和配置 monit 作為行程監控器[22]。
20. NetHogs - 找出佔用頻寬的行程
NetHogs 是一個輕便的網路監控工具,它按照行程名稱(如 Firefox、wget 等)對頻寬進行分組。如果網路流量突然爆發,啟動 NetHogs,您將看到哪個行程(PID)導致了頻寬激增。
$ sudo nethogs

nethogs linux monitoring tools open source
相關連結:Linux:使用 Nethogs 工具檢視每個行程的頻寬使用情況[23]
21. iftop - 顯示主機上網路介面的頻寬使用情況
iftop 命令監聽指定介面(如 eth0)上的網路通訊情況。它顯示了一對主機的頻寬使用情況[24]。
$ sudo iftop

iftop in action
22. vnstat - 基於控制檯的網路流量監控工具
vnstat 是一個簡單易用的基於控制檯的網路流量監視器,它為指定網路介面保留每小時、每天和每月網路流量日誌。
$ vnstat
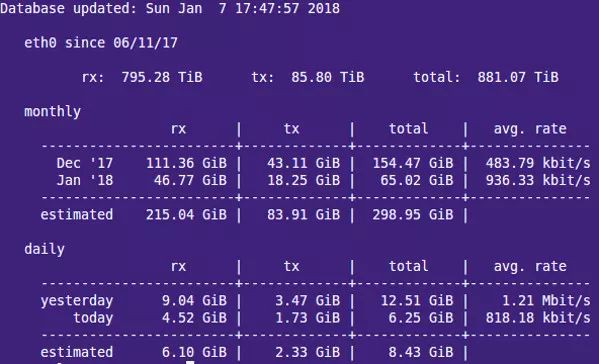
vnstat linux network traffic monitor
相關連結:
23. nmon - Linux 系統管理員的調優和基準測量工具
nmon 是 Linux 系統管理員用於效能調優的利器,它在命令列顯示 CPU、記憶體、網路、磁碟、檔案系統、NFS、消耗資源最多的行程和分割槽資訊。
$ nmon

nmon command
相關連結:安裝並使用 nmon 工具來監控 Linux 系統的效能[27]
24. glances - 密切關註 Linux 系統
glances 是一款開源的跨平臺監控工具。它在小小的螢幕上提供了大量的資訊,還可以工作於客戶端-伺服器樣式下。
$ glances

Glances
相關連結:Linux:透過 Glances 監控器密切關註您的系統[28]
25. strace - 檢視系統呼叫
想要跟蹤 Linux 系統的呼叫和訊號嗎?試試 strace 命令吧。它對於除錯網頁伺服器和其他伺服器問題很有用。瞭解如何利用其 追蹤行程[29] 並檢視它在做什麼。
26. /proc 檔案系統 - 各種核心資訊
/proc 檔案系統提供了不同硬體裝置和 Linux 內核的詳細資訊。更多詳細資訊,請參閱 Linux 核心 /proc[30] 檔案。常見的 /proc 例子:
# cat /proc/cpuinfo
# cat /proc/meminfo
# cat /proc/zoneinfo
# cat /proc/mounts
27. Nagios - Linux 伺服器和網路監控
Nagios[31] 是一款普遍使用的開源系統和網路監控軟體。您可以輕鬆地監控所有主機、網路裝置和服務,當狀態異常和恢復正常時它都會發出警報通知。FAN[32] 是“全自動 Nagios”的縮寫。FAN 的標的是提供包含由 Nagios 社群提供的大多數工具包的 Nagios 安裝。FAN 提供了標準 ISO 格式的 CD-Rom 映象,使安裝變得更加容易。除此之外,為了改善 Nagios 的使用者體驗,發行版還包含了大量的工具。
28. Cacti - 基於 Web 的 Linux 監控工具
Cacti 是一個完整的網路圖形化解決方案,旨在充分利用 RRDTool 的資料儲存和圖形功能。Cacti 提供了快速輪詢器、高階圖形模板、多種資料採集方法和使用者管理功能。這些功能被包裝在一個直觀易用的介面中,確保可以實現從區域網到擁有數百臺裝置的複雜網路上的安裝。它可以提供有關網路、CPU、記憶體、登入使用者、Apache、DNS 伺服器等的資料。瞭解如何在 CentOS / RHEL 下 安裝和配置 Cacti 網路圖形化工具[33]。
29. KDE 系統監控器 - 實時系統報告和圖形化顯示
KSysguard 是 KDE 桌面的網路化系統監控程式。這個工具可以透過 ssh 會話執行。它提供了許多功能,比如可以監控本地和遠端主機的客戶端-伺服器樣式。前端圖形介面使用感測器來檢索資訊。感測器可以傳回簡單的值或更複雜的資訊,如表格。每種型別的資訊都有一個或多個顯示介面,並被組織成工作表的形式,這些工作表可以分別儲存和載入。所以,KSysguard 不僅是一個簡單的任務管理器,還是一個控制大型伺服器平臺的強大工具。

圖 05:KDE System Guard {圖片來源:維基百科}
詳細用法,請參閱 KSysguard 手冊[34]。
30. GNOME 系統監控器
系統監控程式能夠顯示系統基本資訊,並監控系統行程、系統資源使用情況和檔案系統。您還可以用其修改系統行為。雖然不如 KDE System Guard 強大,但它提供的基本資訊對新使用者還是有用的:

圖 06:Gnome 系統監控程式
福利:其他工具
更多工具:
ntop 是檢視網路使用情況的最佳工具,與 top 命令之於行程的方式類似,即網路流量監控工具。您可以檢視網路狀態和 UDP、TCP、DNS、HTTP 等協議的流量分發。mtr 將 traceroute 和 ping 程式的功能結合在一個網路診斷工具中。如果您有其他推薦的系統監控工具,歡迎在評論區分享。
關於作者
作者 Vivek Gite 是 nixCraft 的建立者,也是經驗豐富的系統管理員,以及 Linux 作業系統和 Unix shell 指令碼的培訓師。他的客戶遍佈全球,行業涉及 IT、教育、國防航天研究以及非營利部門等。您可以在 Twitter[42]、Facebook[43] 和 Google+[44] 上關註他。
via: https://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
作者:Vivek Gite[46] 譯者:jessie-pang 校對:wxy
本文由 LCTT 原創編譯,Linux中國 榮譽推出