編譯:劉佳瑋、Stats熊、蔡婕、張弛、Aileen
來源:大資料文摘
原文:veekaybee
資料科學剛剛度過了它的黃金五年。
自2012年以來,這個行業發展迅速。它幾乎完整經歷了Gartner技術成熟度曲線的每個階段。

度過了初期使用階段、有關AI和偏見的負面新聞、Facebook等公司的第二三輪風投。現在的資料科學正處於高增長使用階段:即使是銀行、醫療保健公司和落後市場五年的其他100強企業,也在招聘機器學習中的資料科學崗位。
但現實正在發生巨大的變化。
來自captech基金的資深資料科學家Vicki Boykis釋出了一篇《資料科學不一樣了》的文章,引起了廣泛討論。五年前被譽為“最性感“職業的資料科學家,正在進入一個新的階段。
我們該如何應對?一起看看。
大資料(還記得Hadoop和Pig嗎?)已經出局,R語言的採用率急劇上升,Python在《經濟學人》雜誌中被表揚多次,“雲”已經再次改變了一切。
不幸的是,大眾媒體在資料科學領域的炒作始終沒有改變。
直到今天,在各類不負責任的媒體口中,資料科學家依然是“21世紀最性感最容易找工作的職業”。而事實上,希望進入這個行業的初級資料科學家已經供過於求,他們一旦獲得夢寐的“資料科學家”稱號後,實際展現出來的能力並不能達到預期的那樣。
01 新資料科學家的供過於求
首先,我們來談談初級資料科學家的供過於求。
圍繞資料科學的持續媒體炒作極大地提高了過去五年市場上的初級人才數量。
這純粹是傳聞,你大可不必相信。但是,基於我參與篩選簡歷、做剛入門的資料科學家的導師、做採訪者和受訪者以及與處於類似職位的朋友和同事們的對話的經歷,可以初步感受到,每個資料科學職位而言,特別是入門級的職位,候選人都已經從20個增加到100個或更多。
我最近和一個朋友談話,他的一個開放職位收到了500份簡歷。
這並不奇怪。更多的傳聞是來自像機器學習教父吳恩達的職位空缺,他的AI創業公司每週要求70-80小時的工作時間。
即便如此,他依然收到了很多人試圖免費為他志願工作。截止到目前,據他所說,他的辦公室已經全部坐滿。
正確估計市場供需當然不容易,但Wired的一篇文章可以提供一些線索:
對2018年4月份招聘廣告的研究發現,美國有超過10000個職位空缺,面向有人工智慧或機器學習技能的人。
文章繼續表明:
超過10萬人開始學習Fast.ai提供的深度學習課程,Fast.ai是一家專註於擴大人工智慧應用的創業公司。
讓我們做一道簡單的數學題。
假設MOOC(慕課)的平均完成率約為7%,那意味著,這一年會有7000人可以填補這10000個工作崗位。這一年如此,但明年又如何呢?我們是否假設資料科學的就業率穩定?如果是這樣,資料科學的就業市場看起來就會縮小很多。
我們再來看一項更廣泛的研究,LinkedIn表示市場上缺少151717個具有資料科學技能的人才。雖然目前還不清楚這是指資料科學家還是僅具有部分技能的人,但我們假設是前者。那樣的話,該國資料科學家有150000個職位空缺。
鑒於有100000人已經開始了資料科學課程,我們假設其中有7000人能完成課程。
但是,這些數字還都沒有考慮到所有創造新的資料科學候選人的計劃和途徑:有像Coursera這樣的Fast.ai之外的MOOC,有超過10個像Metis和GA(General Assembly)這樣的每季度25人參加的全國性訓練營,還有像加州大學洛杉磯分校等地的遠端學位——分析和資料科學的學士學位,YouTube等,還有大量無法在極其緊張的就業市場找到工作、正從學術界轉向資料科學的博士們。
這裡有第三個確鑿證據,來自PWC,它指出2015年資料科學家有4萬個職位空缺。它還從總體上估計,認為分析技能的市場供應(再次說明,它比資料科學範圍更大,但也是一個比較點)到2018年將會使市場過度擁擠。

將此與數百個資料科學課程的訓練營相結合,如果有人要進入某個行業,你將看到一場大風暴。
根據我在業內工作並與100多名同事交談的直覺,這兩條推特最終使我確信資料科學行業存在供應泡沫。
首先,是這個有關入門資料科學課程的推特:

Cal的入門資料科學課程是Data 8,這門課很受歡迎,位於澤勒巴赫教室。開課時間是2018年秋季學期第一天。
和UVA開設資料科學學院的訊息:

▲UVA很自豪地宣佈計劃中的資料科學學院成立,它將滿足社會增長最快的需求之一
由於在適應工業界的新趨勢上,學術界通常是滯後的,因此這個趨勢真的該引起初級資料科學家們的重視,所有人都希望找一個資料科學的職位。考慮到他們在市場上的競爭者數量,剛獲得資料科學學位的人很難找到真的入行。
在三、四年前情況還並非如此,然而現在資料科學已經從一個流行詞彙轉變為矽谷泡沫外更大的公司招聘的職位,相關的職位不僅更加正式化,而且有著更嚴格的準入要求(即傾向於曾經具備資料科學工作經驗的人)。資料科學職位的面試仍然難以把握,並且與工作完全不匹配。
正如許多部落格文章指出的那樣,你未必在第一次嘗試時就能找到理想工作。因此,就業市場相當艱難,對於大量入門者來說更加困難重重。
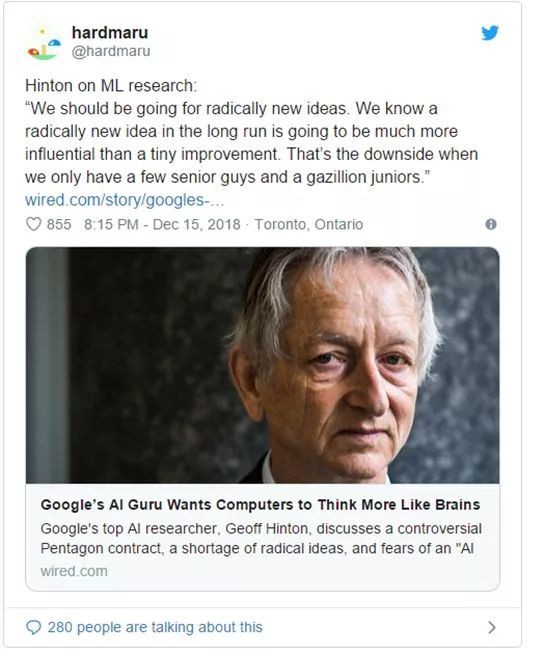
Hinton對於機器學習領域現狀的想法:
我們應該採取全新的想法。我們都知道從長遠來看,一個全新的想法將比一個個微小的改進更有效。當我們這個群體只有一些資深人士和一大批青少年時,這就是缺點。
02 資料科學存在有誤導性的工作需求
第二個問題是,一旦這些初學者進入市場,他們會對資料科學的工作樣式產生不切實際的期望。每個人都認為他們將進行機器學習、深度學習和貝葉斯模擬。
這並不是他們的錯,這正是一些資料科學課程和技術媒體們一直以來強調的內容。自從很久之前我第一次過分樂觀地瀏覽Hacker News 上邏輯回歸的帖子以來,情況並沒有發生多大變化。
現實情況是,“資料科學”從未像機器學習那樣關註資料清洗、資料轉換以及將資料從一個地方移動到另一個地方。
我最近進行的極其非科學的調查問卷證實了這一點:

作者2019年1月在推特上做的調查問卷:
近一段時間以來對此非常好奇,所以我決定建立一個調查問卷:
“作為2019年被稱為’資料科學家’的人,我花了大部分時間在(60%以上):”
選擇了(“其他”)也歡迎在回覆中新增。
調查結果:
6% 選擇特性/模型
67% 清理資料/行動資料
4% 在產品中部署模型
23% 分析/呈現資料
許多行業專家傳送的推文也是如此:
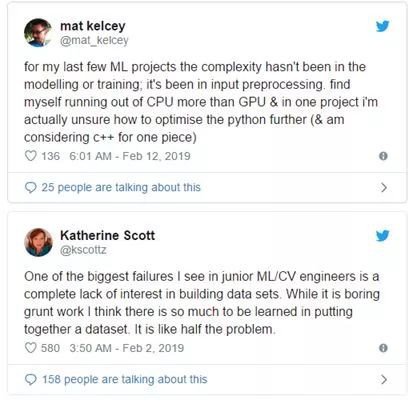
在我最近的幾個機器學習專案中,複雜的地方不再是建模或培訓裡;二是在在輸入預處理中。我發現自己耗盡的是CPU而不是GPU,並且在一個專案中我真的不確定如何進一步最佳化python(我也正在考慮c ++)。
——mat kelcey
我在初級ML/ CV工程師身上看到的最失敗的一面是對構建資料集完全缺乏興趣。雖然這是一項無聊的工作,但我認為在整理資料集時能夠學習到很多東西。這就像是問題的一半。
——Katherine Scott
伴隨著資料清洗,當炒作週期繼續發揮著它的效應時,更加清晰的是,資料工具和將模型投入生產變得比在一臺機器上從頭開始構建ML演演算法更加重要,特別是隨著雲資源可用性的爆炸式增長。
顯而易見的是,在炒作週期的後期階段,資料科學將逐漸接近工程學,而資料科學家需要的技能不再主要基於視覺化和統計學,而是更符合傳統的電腦科學課程:像單元測試和持續整合這樣的概念,很快就成了術語,並被用作資料科學家和從事ML工程的數值科學家常用的工具集。
這也導致了幾件事的發生:首先是“機器學習工程師”這個頭銜的崛起,在過去的3-4年裡,它帶來了更多的聲望和更高的收入潛力。
其次,它導致了資料科學家職稱的嚴重縮水。由於資料科學家職稱的聲望,像Lyft這樣的公司會招聘這類職位,但要求擁有資料分析師的技能,這就造成了彆扭的情況——資料科學的職位究竟需要做什麼,又有多少職位提供給新入職的工作者。
我們作為資深從業者、記者、經理、行業會議發言人、撰寫工作要求的人力資源經理,仍然不能很好地解決這個重要的難題。
03 給新資料科學家的建議
因此,本著繼續為初學者提供建議的精神,我將給任何在2019年向我諮詢如何進入資料科學領域的人傳送這封郵件。
這是一個兩步計劃:
-
不要一味追求資料科學的工作
-
為成為資料科學家做好準備,而不是單單為了資料科學。調整你的技能組合。
這些聽起來真是令人沮喪!但是,讓我來詳細說明這兩個問題,希望它們看起來不那麼黯淡。
1. 謹慎選擇資料科學
鑒於每個初級崗位有50或100或200個人投簡歷,因此不要與那些人競爭。不必攻讀資料科學學位,不必參加訓練營(邊註:我見過的大多數訓練營都是效率低下的,他們在很短的時間內讓求職者處理太多的資訊,使得求職者無法有效地對資料科學有所瞭解,在這裡我就不細說了)。
不要做別人正在做的事情,因為這樣不能使你脫穎而出。你是在和一個堆積如山、過度飽和的行業競爭,這隻會讓事情變得更困難。在我之前提到的那份PWC報告中,資料科學職位的數量估計為5萬。資料工程職位的數量為50萬。而資料分析師的數量是12.5萬。
透過“後門”進入資料科學和技術的職位要容易得多,比如從做初級開發人員開始,或者從DevOps、專案管理開始,以及從事最相關的資料分析師、資訊管理員等類似職位,而不是直接申請其他人也同時競爭的5個崗位。這將花費更長的時間,但是在你從事資料科學工作的同時,也在學習對你的整個職業生涯至關重要的IT技能。
2. 瞭解當今資料科學所需的技能
下麵是一些你在資料空間中實際需要處理的問題:
-
建立Python包
-
將R陳述句投入實際生產
-
最佳化Spark工作,使其更有效地執行
-
版本控制資料
-
使模型和資料可複製
-
版本控制SQL
-
在資料湖中建立和維護乾凈的資料
-
大規模時間序列預測工具
-
擴充套件Jupyter筆記本的共享
-
考慮清洗資料的系統
-
大量的JSON
雖然在資料科學中有許多有趣的統計問題需要考慮,但這些部落格連結都沒有解決它們。儘管調整模型、視覺化和分析佔據了你作為資料科學家的部分時間,但資料科學一直主要的工作是如何得到可以直接使用的乾凈資料。
所有這些部落格文章有什麼共同之處?那就是良好的資料背景下的各個工程技能。
你該如何準備解決這些問題,併為工作做好準備?學習以下三種技能,它們都是基礎技能,並且相互之間有關聯,從入門到精通。
所有這些技能的真正關鍵之處在於,它們對於資料科學之外的軟體開發也是基礎和重要的,這意味著如果你找不到資料科學相關的工作,也可以快速地過渡到軟體開發或devops。我認為這種靈活性與針對特定資料相關任務的培訓同樣重要。
(1)學習SQL
首先,我建議無論標的是成為資料工程師、ML專家還是AI 專家,每個人都需要學習SQL。
SQL並不吸引人,它也不是我剛才列出的問題的解決方案。但實際上,為了理解如何訪問資料,你極有可能在某個地方遇到需要編寫一些SQL查詢並獲得答案的資料庫。
SQL非常強大且受歡迎,以至於NoSQL和鍵值儲存解決方案也在復現它。只需檢視Presto、Athena,它們由Presto、BigQuery、KSQL、Pandas和Spark等等提供支援。如果你發現自己被大量的資料工具所淹沒,那麼很可能有SQL是適合你的。而且,一旦你理解了SQL正規化,就能更容易理解其他查詢語言,從而開闢一個全新的領域。
在學好SQL之後,下一步是瞭解資料庫如何工作以及為什這樣就可以學習最佳化查詢。你不會成為資料庫開發人員,但是許多概念將延續到你的其他程式設計生活中。
(2)學好程式語言、學習程式設計概念
前文我們談論過如何學習SQL的問題,當你使用SQL的時候,你會有這樣一個疑問,這樣的資料庫處理軟體,它是不是一個程式語言呢?答案是肯定的,不過它屬於宣告式程式設計。你可以指定所需要的輸出(就是你想從資料表中把哪幾列提取出來),但沒法控制它用什麼方式把結果反饋。SQL抽象出大量發生在資料庫內的資訊。
與之相對的,如果你需要一種可以指定資料從哪裡、用什麼方式被選取出來。像Java、Python、Scala、R、Go等等這些都是現在流行的面向物件的過程化語言。
大家現在對用哪種語言去做資料科學依舊有很多爭論,當然也不會在這裡指定一種語言是最合適的。但我想說的是,在我的日常工作中,Python對我的幫助真的很大。作為一個初學者來說,Python很容易上手,而且也是資料領域裡最流行的程式語言。
為什麼這麼說呢,因為它可以處理很多資料問題,如構建一個模型放入到scikitlearn裡、訪問AWS API雲平臺服務介面、製作網頁服務應用、清洗資料、建立深度學習模型等等。而在統計領域裡,R還是更為廣泛使用。
但同樣的,我還是建議不用去深究統計領域,Python基本可以滿足程式設計需求了。
當然Python在大規模應用、打包依賴關係、一些特定數字處理、特別是時間序列和R那樣開包即用(Python不像R有很多成型的功能包、更細緻的統計功能模型) 等等問題上也不是很適用。
如果你不選擇Python,那也沒什麼問題。但你應該選擇一門語言讓你在資料科學之外的領域,一樣可以大展拳腳。舉個例子來說,如果你的第一份工作是資料分析師、質量保障員、初級的軟體開發人員或者其他崗位,這都將是作為你進入這個行業的敲門磚。
如果說一旦你選擇掌握某種程式語言,就會開始學習它的正規化,研究它與整個計算機生態系統的關係。
在開始研究之後,你就會面對這樣一系列問題。如何用你掌握的程式語言進行面向物件程式設計(OOP)?什麼是面向物件程式設計?如何讓你的程式碼更簡化?你使用的語言是透過什麼樣依賴關係工作的?對你寫好的程式碼如何打包,怎樣進行版本控制、持續整合、模型部署?到哪裡去找這種語言社群去交流學習,他們什麼時候進行交流研討會?
然後你需要做的就是不斷地瞭解這門語言,知道它的優缺點,然後用這門語言做些有趣的程式設計,找到其中的樂趣。
然後就像武俠小說裡練就奇功一樣,當你打通任通二脈,這種程式語言能力成為你身體的一部分,然後你就去學習第二種程式語言,它將會教給你更多關於語言設計、演演算法和樣式的內容,瞭解這個更豐富有趣的語言世界。
(3)學會如何在雲平臺進行操作
現在你知道如何進行程式設計,那下一步要做的就是把這些能力和理論推廣到雲平臺上,跟其他程式設計者進行共享。
現在雲服務無處不在,很有可能你的下一份工作就是需要在雲平臺上完成的。有了雲技術,如果能夠搶先一步,就越容易走到前列,就比如現在有越來越多的機器學習範例轉移到了雲服務供應商(如亞馬遜的SageMaker、谷歌的Cloud AI、微軟的Azure Machine Learning),那上面會有更多現成的模板來實現你想要的演演算法、也有更多的公司資料會儲存在雲上。
當然你也有機會跟AWS行業領導者合作,但越來越多的地方開始使用Google Cloud雲服務,還有一些較為保守的傳統企業也開始用Microsoft Azure雲服務。我的建議是對這上文提到的三家雲服務公司做一個使用者調查,然後選擇一個更適合你們的。
雲設計正規化是通用的,所以你應該更關心如何將服務連線在一起、如何將你使用的部分與雲上其他應用做邏輯隔離,以及如何解析處理大量的JSON。
一個很酷的事情是,現在三家雲服務供應商都開始提供他們的產品認證。我通常不太相信認證是知識獲取的標誌,但是你可以透過認證學到雲平臺很重要的工作原理,這也是工程裡另一個組成部分——網路。
所以在你找到下一份工作之前,可以有時間充分學習一下這三家的證書,並且在雲平臺上自由發揮一下,也是不錯的選擇。
還有一大部分我們沒有講到,就是“軟技能”(知道如何構建、知道如何在工作環境下交流、知道其他人的需求)。這種能力與技術能力同樣重要,也有很多部落格專門提到這種能力。
(4)最後一步
現在深呼吸,我知道你已經做好準備了。
如果說上面說的內容已經足夠打動你,說明在2019年,你已經做好成為一名資料科學家、或機器學習工程師、或雲專家、AI法師的準備了。
請記住,遵循這些建議的最終標的是打敗那些具有資料科學學位、透過訓練營和透過教程的工作人員。
你想進入這個行業,得到一個資料相關職位,朝你期待的工作而努力,並且盡可能多的瞭解整個科技行業的發展。
我的最後一點誠懇建議和鼓勵是:這些東西對任何一個人來說都相當困難,而且看起來你需要瞭解成百上千的事情,永遠不要失去信心。(不忘初心)
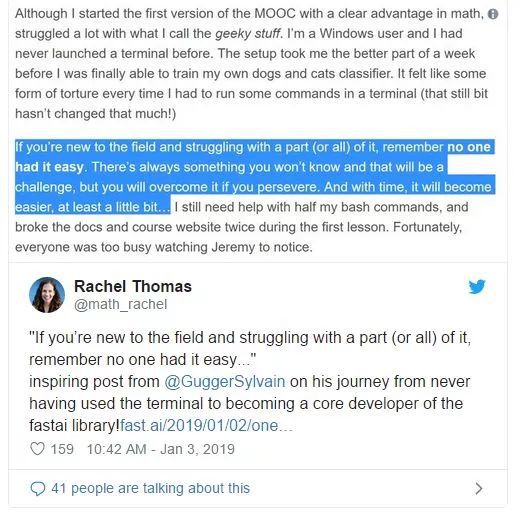
就像上面這個部落格裡,這個作者學習MOOC一開始都是么蛾子,每個都是新東西,而且並沒有接觸過除了Windows以外其他作業系統,也沒有接觸過終端,但是經過努力終於做出了自己想要的分類器。
所以她也說到,在這個領域對於每個人來說都不容易,任何事情都是挑戰,但是最終你都會剋服並且一點點解決掉,你會發現車到山前必有路,柳暗花明又一村。
不要被分析問題的困難所擊倒。從一個小問題入手,積跬步以至千里,最終問題會迎刃而解。告訴大家請記住,你的第一份在資料科學領域的工作不一定就是資料科學家。
我最喜歡的其中一本書是安妮·拉莫特的《Bird By Bird》,是一本關於寫作的書。很有趣的是,這本書的書名是作者的哥哥當年不得不寫的一份讀書報告。
三十年前,我十歲的哥哥正在努力寫一份關於鳥類的研究報告。他本來有三個月的時間進行寫作,但是明天就要交了。我們在柏林阿斯的家裡小屋裡,哥哥他絞盡腦汁地寫那份報告,幾乎要留下眼淚,而他被這艱巨的任務禁錮在廚房餐桌旁,周圍散落著活頁紙、鉛筆和一些沒有開封過的鳥類書籍。這時候父親來到旁邊坐下,抱住哥哥的肩膀說道,“Bird by bird,孩子。就是把鳥一個個列出來”。
後來他就完成了。
不要讓天花亂墜宣傳資訊壓倒你。不要因為那些時髦的詞或者帶著MacBook那種時尚人士形象所矇蔽。集中在一隻鳥的身上,從那裡開始。
相關報道:
https://veekaybee.github.io/2019/02/13/data-science-is-different/

