(點選上方公眾號,可快速關註)
來源:袁鳴凱,
blog.csdn.net/lifetragedy/article/details/7707455
一、總結前一天的學習
在前兩天的學習中我們知道、瞭解並掌握了Web Server結合App Server實現單向Https的這樣的一個架構。這個架構是一個非常基礎的J2ee工程上線佈署時的一種架構。在前兩天的教程中,還講述了Http伺服器、App Server的最基本安全配置(包括單向https的實現), 它只是避免了使用者可以透過瀏覽器侵入我們的Web訪問器或者能夠透過Web瀏覽器來查詢我們的Web目錄結構及其目錄內的檔案與相關內容,這種入侵我們把它稱為:
Directory traversal,當然我們只是實現了最基本的防範Directory traversal的手段,在日後的Security課程中將會詳細地去擅述完整的Web Security的相關理論。
從今天起我們將繼續在原有的這種Apache+Tomat的架構上,去論述如何在效能及Performance上最佳化這個架構,因此這兩天的課程在有些人看來,可能會有些“枯燥”,所以我在此給大家打個招呼:
這兩天的課程論述的是如何在不改動程式碼與SQL陳述句的前提下,如何去改善和提高web server與app server的效能,千萬不要小覷這一內容,它可以讓你在不改動程式碼的情況下得到10-20倍以上的效能提高,網上有其它的大牛們寫過一篇文章叫“Tomcat如何支援到1000個使用者”,經本人經過幾個重大工程的實踐,Opensource的Tomcat如果調優的好不只可以支持者1000個使用者,尤其當你的佈署環境是64位作業系統的情況下,可能能夠支援更大更高的併發效能,最後本節內容將會以Tomcat叢集來做收場,在將來的課程中還會進一步詳細講述Weblogic的叢集配置與IBM WASND的叢集配置。
二、從效能測試談起
2.1 效能測試簡介
即壓力測試,就是根據一定數量的VU(Virtual Users)我稱為併發使用者操作核心交易後,系統所能達到的最大瓶勁,以便於發現系統的極限、有沒有Outof memory這樣的問題存在以及相關的系統設定、配置是否搭擋的合理的一種測試。
一般商業的比較好的用LoaderRunner,如果沒錢的就用Opensource的Jmeter來模擬這個VU的操作。
壓力測試,存在幾個誤區,需要小心。
1) 無限大的拼命增加VU的數量
系統再完美,硬體配置再高,也經不住沒有經過合理運算的VU的壓力呀。
2) 偏執的用一定的資料量的VU,跑7*24小時
不是說這個沒必要,很有必要,小日本的電視為什麼壽命敢說比中國人生產的電視機壽命長?因為它用一個機械臂就對著電視機的按鈕不斷的點點點。
我們說的壓力測試要測試多長時間,關鍵是要看經過科學計算的VU的數量以及核心交易數有多少,不是說我拿250個VU跑24*7如果沒有問題我這個系統就沒有問題了,這樣的說法是不對的,錯誤的。隨便舉個例子就能把你推倒。
假設我有250個VU,同時跑上萬筆交易,每個VU都有上萬筆交易,250個VU一次跑下來可能就要數個小時,你又怎麼能斷定250個VU對於這樣的系統我跑24*7小時就能真的達到上萬筆交易在250個VU的併發操作下能夠真的跑完7天的全部交易?可能需要一週半或者兩周呢?對吧?
我還看到過有人拿500個VU對著一條交易反覆跑24*7小時。。。這樣的測試有意義嗎?你係統就僅僅只有一條交易?你怎麼能夠判斷這條交易涉及到的資料量最大?更不用說交易是彼此間有依賴的,可能a+b+c+d的交易的一個混合組織就能夠超出你單筆交易所涉及到的資料量了呢!
2.2 合理的制定系統最大使用者、併發使用者
提供下麵這個公式,以供大家在平時或者日常需要進行的效能測試中作為一個參考。
(1) 計算平均的併發使用者數:C = nL/T
公式(1)中,C是平均的併發使用者數;n是login session的數量;L是login session的平均長度;T指考察的時間段長度。
(2) 併發使用者數峰值:C’ ≈ C+3根號C
公式(2)則給出了併發使用者數峰值的計算方式中,其中,C’指併發使用者數的峰值,C就是公式(1)中得到的平均的併發使用者數。該公式的得出是假設使用者的loginsession產生符合泊松分佈而估算得到的。
實體:
假設有一個OA系統,該系統有3000個使用者,平均每天大約有400個使用者要訪問該系統,對一個典型使用者來說,一天之內使用者從登入到退出該系統的平均時間為4小時,在一天的時間內,使用者只在8小時內使用該系統。
則根據公式(1)和公式(2),可以得到:
C = 400*4/8 = 200
C’≈200+3*根號200 = 242
F=VU * R / T
其中F為吞吐量,VU表示虛擬使用者個數,R表示每個虛擬使用者發出的請求數,T表示效能測試所用的時間
R = T / TS。
2.3 影響和評估效能的幾個關鍵指標
從上面的公式一節中我們還得到了一個名詞“吐吞量”。和吞吐量相關的有下麵這些概念,記錄下來以供參考。

吞吐量
指在一次效能測試過程中網路上傳輸的資料量的總和。
對於互動式應用來說,吞吐量指標反映的是伺服器承受的壓力,在容量規劃的測試中,吞吐量是一個重點關註的指標,因為它能夠說明系統級別的負載能力,另外,在效能調優過程中,吞吐量指標也有重要的價值。
吞吐率
單位時間內網路上傳輸的資料量,也可以指單位時間內處理客戶請求數量。它是衡量網路效能的重要指標,通常情況下,吞吐率用“位元組數/秒”來衡量,當然,你可以用“請求數/秒”和“頁面數/秒”來衡量。其實,不管是一個請求還是一個頁面,它的本質都是在網路上傳輸的資料,那麼來表示資料的單位就是位元組數。
事務
就是使用者某一步或幾步操作的集合。不過,我們要保證它有一個完整意義。比如使用者對某一個頁面的一次請求,使用者對某系統的一次登入,淘寶使用者對商品的一次確認支付過程。這些我們都可以看作一個事務。那麼如何衡量伺服器對事務的處理能力。又引出一個概念—-TPS
TPS (Transaction Per second)
每秒鐘系統能夠處理事務或交易的數量,它是衡量系統處理能力的重要指標。
點選率(Hit Per Second)
點選率可以看做是TPS的一種特定情況。點選率更能體現使用者端對伺服器的壓力。TPS更能體現伺服器對客戶請求的處理能力。
每秒鐘使用者向web伺服器提交的HTTP請求數。這個指標是web 應用特有的一個指標;web應用是“請求-響應”樣式,使用者發一個申請,伺服器就要處理一次,所以點選是web應用能夠處理的交易的最小單位。如果把每次點選定義為一個交易,點選率和TPS就是一個概念。容易看出,點選率越大。對伺服器的壓力也越大,點選率只是一個效能參考指標,重要的是分析點選時產生的影響。
需要註意的是,這裡的點選不是指滑鼠的一次“單擊”操作,因為一次“單擊”操作中,客戶端可能向伺服器發現多個HTTP請求。
吞吐量指標的作用:
-
使用者協助設計效能測試場景,以及衡量效能測試場景是否達到了預期的設計標的:在設計效能測試場景時,吞吐量可被使用者協助設計效能測試場景,根據估算的吞吐量資料,可以對應到測試場景的事務發生頻率,事務發生次數等;另外,在測試完成後,根據實際的吞吐量可以衡量測試是否達到了預期的標的。
-
用於協助分析效能瓶頸:吞吐量的限制是效能瓶頸的一種重要表現形式,因此,有針對性地對吞吐量設計測試,可以協助儘快定位到效能冰晶所在位置。
平均相應時間
也稱為系統響應時間,它一般指在指定數量的VU情況下,每筆交易從mouse 的click到IE的資料掃清與展示之間的間隔,比如說:250個VU下每筆交易的響應時間不超過2秒。
當然,響應時間也不能一概而論,對於實時交易如果銀行櫃臺操作、超市收銀員(邪惡的笑。。。)的操作、證交所交易員的操作來說這些操作的響應時間當然是越快越好,而對於一些企業級的如:
與銀行T+1交易間的資料跑批、延時交易、T+1報表等,你要求它在2秒內響應,它也做不到啊。就好比你有個1MB的頻寬,你傳的東西是超過4MB,你要它在2秒內跑完理論速度也做不到啊,對吧,所以有些報表或者資料,光前面傳輸時間就不止兩秒了。。。一口咬死說我所有的交易平均相應時間要2秒,真的是不科學的!
2.4 合理的效能測試
VU數量的增加
一個合理的效能測試除了需要合理的計算VU的數量、合理的設定系統平均響應時間外還需要合理的在測試時去規劃發起VU的時間,比如說,我看到有人喜歡這樣做壓力測試。
第一秒時間,500個併發使用者全部發起了。。。結果導致系統沒多久就崩了,然後說系統沒有滿足設計要求。
為什麼說上述這樣的做法是不對的?我們說不是完全不對,只能說這樣的測試已經超過了500個VU的併發的設計指標了。
合理的併發應該是如下這樣的:
有25-50個VU開始起交易了,然後過一段時間又有25-50個使用者,過一段時間又增加一些VU,當所有的設計VU都發起交易了,此時,再讓壓力測試跑一段時間比如說:24*7是比較合理的。所以VU數量不是一上手就500個在一秒內發起的,VU數量的增加應該如下麵這張趨勢圖:

這是一個階梯狀的梯型圖,可以看到VU的發起是逐漸逐漸增多的,以下兩種情況如果發生需要檢查你的系統是否在原有設定上存在問題:
-
VU數量上升階段時崩潰
有時僅僅在VU數量上升階段,系統就會了現各種各樣的錯誤,甚至有崩潰者,這時就有重新考慮你的系統是否有設定不合理的地方了。
-
VU全部發起後沒多久系統崩潰
VU在達到最高值時即所有的VU都已經發起了,此時它是以一條直的水平線隨著系統執行而向前延伸著的,但過不了多久,比如說:執行24*7小時,運行了沒一、兩天,系統崩潰了,也需要做檢查。
所以,理想的效能測試應該是VU數量上升到最終VU從發起開始到最後所有VU把交易做完後,VU數量落回零為止。
吐吞量的變化
從2.3節我們可以知道,吞吐量是隨著壓力/效能測試的時間而逐漸增大的,因此你的吞吐量指示應該如下圖所示:
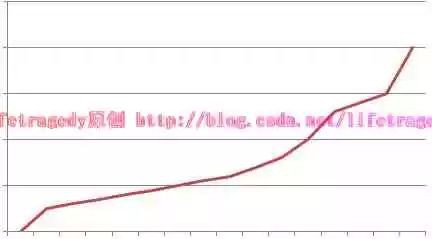
肯定是這樣,你的吞吐量因該是積累的,如果你的吞吐量在上升了一段時間後突然下落,而此時你的效能測試還在跑著,如下圖所示:
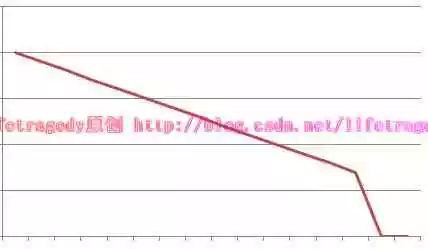
那麼,此時代表什麼事情發生了?你可以查一下你的loaderrunner或者jmeter裡對於這段吞吐量回落期間的交易的response的狀態進行檢視,你將會發現大量的error已經產生,因為產生了error,所以你的交易其實已經出錯了,因此每次執行的資料量越來越小,這也就意味著你的壓力測試沒有過關,系統被你壓崩了!
平均響應時間
平均響應時間如VU的數量增加趨勢圖一樣,一定是一開始響應時間最短,然後一點點增高,當增高到一定的程度後,即所有的VU都發起交易時,你的響應時間應該維持在一個水平值,然後隨著VU將交易都一筆筆做完後,這個響應時間就會落下來,這段時間內的平均值就是你的系統平均響應時間。看看它,有沒有符合設計標準?
記憶體監控
我們就來說AppServer,我們這邊用的是Tomcat即SUN的JVM的記憶體變化,我們就用兩張圖例來講解吧:
理想狀態情況下的JVM記憶體使用趨勢:

這是一個波浪型的(或者也可以說是鋸齒型的)趨勢圖,隨著VU數量的一點點增加,我們的記憶體使用數會不斷的增加,但是JVM的垃圾回收是自動回收機制的,因此如果你的JVM如上述樣的趨勢,記憶體上漲一段時間,隨即會一點點下落,然後再上漲一點,漲到快到頭了又開始下落,直到最後你的VU數量全部下降下來時,你的JVM的記憶體使用也會一點點的下降。
非理想狀態情況下的JVM記憶體使用趨勢:
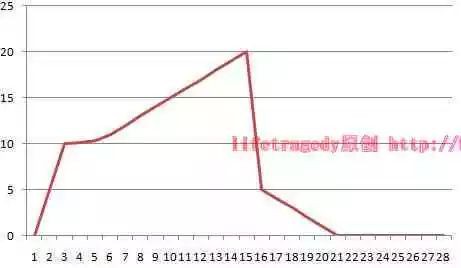
嘿嘿嘿,看到了嗎?你的JVM隨著VU 數量的上升,而直線上升,然後到了一定的點後,即到了java –Xmx後的那個值後,突然直線回落,而此時你的交易還在進行,壓力測試也還在進行,可是記憶體突然回落了。。。因為你的JVM已經crash了,即OUT OF MEMORY鳥。
CPU Load
我們來看一份測試人員提交上來CPU得用率的報告:
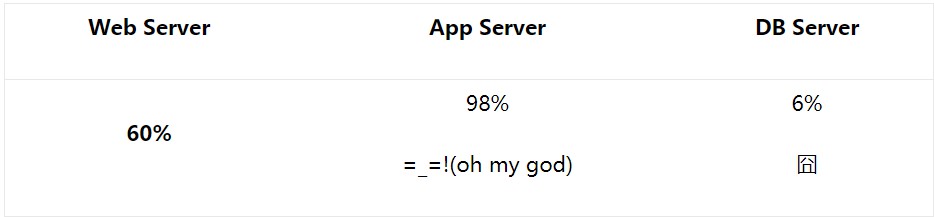
同時平均響應時間好慢啊。
拿過來看了一下程式碼與設計。。。Struts+Spring+JDBC的一個框架,沒啥花頭的,再仔細一看Service層。
大量的複雜業務邏輯甚至報表的產生全部用的是javaobject如:List, Hashmap等操作,甚至還有在Service層進行排序、複雜查詢等操作。
一看DB層的CPU利用率才6%,將一部分最複雜的業務拿出去做成Store Procedure(儲存過程後),再重新執行壓力測試。

同時平均響應時間比原來快了15-16倍。
為什麼??
看看第一份報告,我們當時還查看了資料庫伺服器的配置,和APPServer的配置是一個級別的,而利用率才6%。。。
資料庫,至所以是大型的商用的關係型資料庫,你只拿它做一個儲存介質,你這不是浪費嗎?人家裡面設定的這個StoreProcedure的處理能力,索引效率,資料分塊等功能都沒有去利用,而用你的程式碼去實現那麼多複雜業務比如說多表關聯、巢狀等操作,用必要嗎?那要資料庫乾什麼用呢?
是啊,我承認,原有這樣的程式碼,跨平臺能力強一點,可付出的代價是什麼呢?
使用者在乎你所謂的跨平臺的理論還是在乎的是你係統的效率?一個系統定好了用DB2或者是SQL SERVER,你覺得過一年它會換成ORACLE或者MYSQL嗎?如果1年一換,那你做的系統也只能讓使用者勉強使用一年,我勸你還是不要去做了。在中國,有人統計過5年左右會有一次系統的更換,而一些銀行、保險、金融行業的系統一旦採用了哪個資料庫,除非這個系統徹底出了問題,負責是不會輕意換資料庫的,因此不要拿所謂的純JAVA程式碼或者說我用的是Hibernate,ejb實現可以跨資料庫這套來說事,效率低下的系統可以否定你所做的一切,一切!
三、Apache伺服器的最佳化
上面兩節,講了大量的理論與實際工作中碰到的相關案例,現在就來講一下在我們第一天和第二天中的ApacheHttp Server + Tomcat這樣的架構,怎麼來做最佳化吧。
3.1 Linux/UnixLinux系統下Apache 併發數的最佳化
Apache Http Server在剛安裝完後是沒有併發數的控制的,它採用一個預設的值,那麼我們的Web Server硬體很好,允許我們撐到1000個併發即VU,而因為我們沒有去配置導致我們的WebServer連300個併發都撐不到,你們認為,這是誰的責任?
Apache Http伺服器採用prefork或者是worker兩種併發控制樣式。
-
preforkMPM使用多個子行程,每個子行程只有一個執行緒。每個行程在某個確定的時間只能維持一個連線。在大多數平臺上,PreforkMPM在效率上要比Worker MPM要高,但是記憶體使用大得多。prefork的無執行緒設計在某些情況下將比worker更有優勢:它可以使用那些沒有處理好執行緒安全的第三方模組,並且對於那些執行緒除錯困難的平臺而言,它也更容易除錯一些。
-
workerMPM 使用多個子行程,每個子行程有多個執行緒。每個執行緒在某個確定的時間只能維持一個連線。通常來說,在一個高流量的HTTP伺服器上,Worker MPM是個比較好的選擇,因為Worker MPM的記憶體使用比PreforkMPM要低得多。但worker MPM也由不完善的地方,如果一個執行緒崩潰,整個行程就會連同其所有執行緒一起”死掉”.由於執行緒共享記憶體空間,所以一個程式在執行時必須被系統識別為”每個執行緒都是安全的”。
一般來說我們的ApacheHttp Server都是裝在Unix/Linux下的,而且是採用原始碼編譯的方式來安裝的,我們能夠指定在編譯時Apache就採用哪種樣式,為了明確我們目前的Apache採用的是哪種樣式在工作,我們還可以使用httpd –l命令即在Apache的bin目錄下執行httpd –l,來確認我們使用的是哪種樣式。
這邊,我們使用Apache配置語言中的” IfModule”來自動選擇樣式的配置。
我們的ApacheHttp Server在配完後一般是沒有這樣的配置的,是需要你手動的新增如下這樣的一塊內容的,我們來看,在httpd.conf檔案中定位到最後一行LoadModule,敲入回車,加入如下內容:
ServerLimit 20000
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxClients 1000
MaxRequestsPerChild 0
上述引數解釋:
-
ServerLimit 20000
生效前提:必須放在其他指令的前面
-
StartServers 5
指定伺服器啟動時建立的子行程數量,prefork預設為5。
-
MinSpareServers 5
指定空閑子行程的最小數量,預設為5。如果當前空閑子行程數少於MinSpareServers ,那麼Apache將以最大每秒一個的速度產生新的子行程。此引數不要設的太大。
-
MaxSpareServers 10
設定空閑子行程的最大數量,預設為10。如果當前有超過MaxSpareServers數量的空閑子行程,那麼父行程將殺死多餘的子行程。此引數不要設的太大。如果你將該指令的值設定為比MinSpareServers小,Apache將會自動將其修改成”MinSpareServers+1″。
-
MaxClients 256
限定同一時間客戶端最大接入請求的數量(單個行程併發執行緒數),預設為256。任何超過MaxClients限制的請求都將進入等候佇列,一旦一個連結被釋放,佇列中的請求將得到服務。要增大這個值,你必須同時增大ServerLimit。
-
MaxRequestsPerChild10000
每個子行程在其生存期內允許伺服的最大請求數量,預設為10000.到達MaxRequestsPerChild的限制後,子行程將會結束。如果MaxRequestsPerChild為”0″,子行程將永遠不會結束。
將MaxRequestsPerChild設定成非零值有兩個好處:
-
可以防止(偶然的)記憶體洩漏無限進行,從而耗盡記憶體。
-
給行程一個有限壽命,從而有助於當伺服器負載減輕的時候減少活動行程的數量。
Prefork.c的工作方式:
一個單獨的控制行程(父行程)負責產生子行程,這些子行程用於監聽請求並作出應答。Apache總是試圖保持一些備用的(spare)或者是空閑的子行程用於迎接即將到來的請求。這樣客戶端就不需要在得到服務前等候子行程的產生。在Unix系統中,父行程通常以root身份執行以便邦定80埠,而Apache產生的子行程通常以一個低特權的使用者執行。User和Group指令用於設定子行程的低特權使用者。執行子行程的使用者必須要對它所服務的內容有讀取的許可權,但是對服務內容之外的其他資源必須擁有盡可能少的許可權。
在上述的
後再加入一個”
ServerLimit 20000
StartServers 5
MinSpareServers 5
MaxSpareServers 10
MaxClients 1000
MaxRequestsPerChild 0
ServerLimit 50
ThreadLimit 200
StartServers 5
MaxClients 5000
MinSpareThreads 25
MaxSpareThreads 500
ThreadsPerChild 100
MaxRequestsPerChild 0
ServerLimit16上述引數解釋:
-
伺服器允許配置的行程數上限。這個指令和ThreadLimit結合使用設定了MaxClients最大允許配置的數值。任何在重啟期間對這個指令的改變都將被忽略,但對MaxClients的修改卻會生效。
-
ThreadLimit64
每個子行程可配置的執行緒數上限。這個指令設定了每個子行程可配置的執行緒數ThreadsPerChild上限。任何在重啟期間對這個指令的改變都將被忽略,但對ThreadsPerChild的修改卻會生效。預設值是”64″.
-
StartServers3
伺服器啟動時建立的子行程數,預設值是”3″。
-
MinSpareThreads75
最小空閑執行緒數,預設值是”75″。這個MPM將基於整個伺服器監視空閑執行緒數。如果伺服器中總的空閑執行緒數太少,子行程將產生新的空閑執行緒。
-
MaxSpareThreads250
設定最大空閑執行緒數。預設值是”250″。這個MPM將基於整個伺服器監視空閑執行緒數。如果伺服器中總的空閑執行緒數太多,子行程將殺死多餘的空閑執行緒。MaxSpareThreads的取值範圍是有限制的。Apache將按照如下限制自動修正你設定的值:worker要求其大於等於MinSpareThreads加上ThreadsPerChild的和
-
MaxClients400
允許同時伺服的最大接入請求數量(最大執行緒數量)。任何超過MaxClients限制的請求都將進入等候佇列。預設值是”400″,16(ServerLimit)乘以25(ThreadsPerChild)的結果。因此要增加MaxClients的時候,你必須同時增加ServerLimit的值。
-
ThreadsPerChild25
每個子行程建立的常駐的執行執行緒數。預設值是25。子行程在啟動時建立這些執行緒後就不再建立新的執行緒了。
-
MaxRequestsPerChild 0
設定每個子行程在其生存期內允許伺服的最大請求數量。到達MaxRequestsPerChild的限制後,子行程將會結束。如果MaxRequestsPerChild為”0″,子行程將永遠不會結束。
將MaxRequestsPerChild設定成非零值有兩個好處:
-
可以防止(偶然的)記憶體洩漏無限進行,從而耗盡記憶體。
-
給行程一個有限壽命,從而有助於當伺服器負載減輕的時候減少活動行程的數量。
註意
對於KeepAlive連結,只有第一個請求會被計數。事實上,它改變了每個子行程限制最大連結數量的行為。
Worker.c的工作方式:
每個行程可以擁有的執行緒數量是固定的。伺服器會根據負載情況增加或減少行程數量。一個單獨的控制行程(父行程)負責子行程的建立。每個子行程可以建立ThreadsPerChild數量的服務執行緒和一個監聽執行緒,該監聽執行緒監聽接入請求並將其傳遞給服務執行緒處理和應答。Apache總是試圖維持一個備用(spare)或是空閑的服務執行緒池。這樣,客戶端無須等待新執行緒或新行程的建立即可得到處理。在Unix中,為了能夠系結80埠,父行程一般都是以root身份啟動,隨後,Apache以較低許可權的使用者建立子行程和執行緒。User和Group指令用於設定Apache子行程的許可權。雖然子行程必須對其提供的內容擁有讀許可權,但應該盡可能給予它較少的特權。另外,除非使用了suexec,否則,這些指令設定的許可權將被CGI指令碼所繼承。
公式:
ThreadLimit>= ThreadsPerChild
MaxClients <= ServerLimit * ThreadsPerChild 必須是ThreadsPerChild的倍數
MaxSpareThreads>= MinSpareThreads+ThreadsPerChild
硬限制:
ServerLimi和ThreadLimit這兩個指令決定了活動子行程數量和每個子行程中執行緒數量的硬限制。要想改變這個硬限制必須完全停止伺服器然後再啟動伺服器(直接重啟是不行的)。
Apache在編譯ServerLimit時內部有一個硬性的限制,你不能超越這個限制。
preforkMPM最大為”ServerLimit200000″
其它MPM(包括work MPM)最大為”ServerLimit 20000
Apache在編譯ThreadLimit時內部有一個硬性的限制,你不能超越這個限制。
mpm_winnt是”ThreadLimit 15000″
其它MPM(包括work prefork)為”ThreadLimit 20000
註意
使用ServerLimit和ThreadLimit時要特別當心。如果將ServerLimit和ThreadLimit設定成一個高出實際需要許多的值,將會有過多的共享記憶體被分配。當設定成超過系統的處理能力,Apache可能無法啟動,或者系統將變得不穩定。
3.2 WindowsWindows系統下Apache 併發數的最佳化
以上是Linux/Unix下的Apache的併發數最佳化配置,如果我們打入了httpd –l如下顯示:

怎麼辦?
步驟一
先修改/path/apache/conf/httpd.conf檔案。
httpd.conf
將“#Includeconf/extra/httpd-mpm.conf”前面的 “#” 去掉,儲存。
步驟二
再修改/apache安裝目錄/conf/extra/httpd-mpm.conf檔案。
在mpm_winnt樣式下,Apache不使用prefork也不使用work工作樣式,切記!
因此,我們只要找到原檔案中:
ThreadsPerChild 150
MaxRequestsPerChild 0
修改後
ThreadsPerChild 500
MaxRequestsPerChild 5000
上述引數解釋:
-
ThreadsPerChild
是指一個行程最多擁有的執行緒數(Windows版本,貌似不可以開啟多個行程),一般100-500就可以,根據伺服器的具體效能來決定。
-
MaxRequestsPerChild
是指一個執行緒最多可以接受的連線數,預設是0,就是不限制的意思,
0極有可能會導致記憶體洩露。所以,可以根據實際情況,配置一個比較大的值。Apache會在幾個執行緒之間進行輪詢,找到負載最輕的一個執行緒來接受新的連線。
註意:
修改後,一定不要apacherestart,而是先 apache stop 然後再 apache start才可以。
3.3 啟用服務端圖片壓縮
對於靜態的html 檔案,在apache 可載入mod_deflate.so 模組,把內容壓縮後輸出,可節約大量的傳輸頻寬。
開啟httpd.conf檔案,找到:
#LoadModule deflate_module modules/mod_deflate.so
將前面的“#”去掉,變成:
LoadModule deflate_module modules/mod_deflate.so
然後在最後一行的LoadModule處,加入如下的幾行:
DeflateCompressionLevel 7
AddOutputFilterByType DEFLATE text/html text/plain text/xml application/x-httpd-php
AddOutputFilter DEFLATE css js
註意:
預設等級是6,而且9級需要更多的CPU時間,用預設的6級就可以了。
要註意的是,在apache 2.2.15中,我用httpd -l看,居然發現mod_deflat已經內建了,所以其實就不用再在httpd.conf中增加loadmodule了,否則會說出錯的
3.4 Apache中將MS辦公檔案自動關聯客戶端的MS-Office
我們經常會在web頁的一個超連結上點一個指向物理檔案的檔案,我們一般會得到“儲存,另存為,開啟”,3個選項,當我們開啟的如果是一個MS檔案,在選“開啟”選項時IE會自動啟用客戶端上裝有的word或者是excel等相關MS辦公工具去開啟,這個怎麼做呢?很簡單。
開啟httpd.conf,找到:
AddType application/x-compress .Z
AddType application/x-gzip .gz .tgz
在其後敲入一個回車,加入:
AddType application/vnd.openxmlformats docx pptx xlsx doc xls ppt txt
重啟Apache服務即可。
3.5 防止DDOS攻擊
DDOS攻擊即採用自動點選機器人或者連續點選工具不斷的掃清某一個網址或者網頁上的按鈕,造成網站在一時間收到大量的HTTP請求,進而阻塞網站正常的HTTP通道甚至造成網站癱瘓。

為了防止這一形式的攻擊,我們一般把在一個按鈕或者是一個請求在一秒內連續執行如:100次,可以認為是一種攻擊(比如說你開啟一個網頁,點一下提交按鈕,然後按住F5鍵不鬆開)。
在Linux下的Apache HttpServer安裝後會提供一個mod_evasive20的模組,用於防止這一形式的攻擊,它的做法是:
如果認為是一個DDOS攻擊,它的防範手段採用如下兩種形勢:
-
把這個請求相關聯的IP,封鎖30分鐘
-
直接把相關的IP踢入黑名單,讓其永不翻身
設定:
在你的Apache的httpd.conf檔案中的最後一行“LoadModule”加入如下這句:
LoadModule evasive20_module /usr/lib/httpd/modules/mod_evasive20.so
然後加入下麵這幾行
DOSHashTableSize 3097
DOSPageCount 15
DOSSiteCount 100
DOSPageInterval 1
DOSSiteInterval 1
DOSBlockingPeriod 36000
DOSEmailNotify 網站超級管理員@xxx.com
DOSLogDir “logs/mod_evasive”
-
DOSSiteCount 每個站點被判斷為dos攻擊的讀取部件(object)的個數核心引數解釋:
-
DOSHashTableSize3097 記錄黑名單的尺寸
-
DOSPageCount 每個頁面被判斷為dos攻擊的讀取次數
-
DOSPageInterval 讀取頁面間隔秒
-
DOSSiteInterval 讀取站點間隔秒
-
DOSBlockingPeriod 被封時間間隔秒
註意:
上述設定是針對Linux/Unix下的Apache Server,相關的Windows下的Apache見如下設定:
為Windows下的Apache載入mod_evasive模組
1. 下載附件中的壓縮包,解壓並複製mod_dosevasive22.dll到Apache安裝目錄下的modules目錄(當然也可以是其他目錄,需要自己修改路徑)。
2. 修改Apache的配置檔案http.conf。
新增以下內容
LoadModule dosevasive22_module modules/mod_dosevasive22.dll
DOSHashTableSize 3097
DOSPageCount 3
DOSSiteCount 50
DOSPageInterval 1
DOSSiteInterval 1
DOSBlockingPeriod 10
3.6 Apache中設定URL含中文附件的下載/開啟的方法(僅限Linux系統下)
這個話題很有趣,起因是我們在工程中碰到了客戶這樣的一個需求:
看看好像沒啥問題,一點這個超連結,因該是在IE中開啟一個叫” 輪胎損壞情況2007-05-05.jpg”,嘿嘿,大家自己動手放一個帶有中文名的這樣的一個圖片,看看能否被解析,解析不了。
所以我們就說,真奇怪,我們上傳圖片都是上傳時的圖片名經上傳元件解析過以後變成一個UUID或者是GUID一類的檔案名如:gb19070122abcxd.jpg這樣一種英文加數字組合的檔案名,這樣的檔案名,Apache當然是可以解析的,客戶堅持一定我上傳的圖片是中文名(連中文描述都不行),因為,客戶說:我們是中國人,當然用中文圖片名。。。
沒辦法,找了半天,找到一篇日文的教程,還好還好,N年前學過一點點日語,照著教程把它啃下來了。
這是一個日本人寫的關於在Apache中支援以亞州文字命名檔案名的一個“補丁”,叫“mod_encoding”。
相關配置:
1. 下載完後是一個這樣的壓縮包:mod_encoding-20021209.tar.gz
2. 解壓後使用:
configure
make
make install
原因很明顯,是regex.h未包含進來,解決辦法也很簡單:在make這一行時,編譯出錯,報“make: *** [mod_encoding.so] Error 1”這樣的錯
用vi開啟mod_encoding.c,
在#include
#include
重新make再make install 搞定,CALL!!!
3. 編譯後得到一個:mod_encoding.so的檔案,然後在httpd.conf檔案中加入下麵這幾行:
LoadModule encoding_module modules/mod_encoding.so
Header add MS-Author-Via “DAV”
EncodingEngine on
NormalizeUsername on
SetServerEncoding GBK
DefaultClientEncoding UTF-8 GBK GB2312
AddClientEncoding “(Microsoft .* DAV $)” UTF-8 GBK GB2312
AddClientEncoding “Microsoft .* DAV” UTF-8 GBK GB2312
AddClientEncoding “Microsoft-WebDAV*” UTF-8 GBK GB2312
4. 重啟Apache,搞定,在apache中我們的url可以是中文名的附件了。
3.7 不可忽視的keepalive選項
在Apache 伺服器中,KeepAlive是一個布林值,On 代表開啟,Off 代表關閉,這個指令在其他眾多的 HTTPD 伺服器中都是存在的。
KeepAlive 配置指令決定當處理完使用者發起的 HTTP 請求後是否立即關閉 TCP 連線,如果 KeepAlive 設定為On,那麼使用者完成一次訪問後,不會立即斷開連線,如果還有請求,那麼會繼續在這一次 TCP 連線中完成,而不用重覆建立新的 TCP 連線和關閉TCP 連線,可以提高使用者訪問速度。
那麼我們考慮3種情況:
1.使用者瀏覽一個網頁時,除了網頁本身外,還取用了多個javascript 檔案,多個css 檔案,多個圖片檔案,並且這些檔案都在同一個HTTP 伺服器上。
2.使用者瀏覽一個網頁時,除了網頁本身外,還取用一個javascript 檔案,一個圖片檔案。
3.使用者瀏覽的是一個動態網頁,由程式即時生成內容,並且不取用其他內容。
對於上面3中情況,我認為:1 最適合開啟 KeepAlive ,2 隨意,3 最適合關閉 KeepAlive
下麵我來分析一下原因。
在 Apache 中,開啟和關閉 KeepAlive 功能,伺服器端會有什麼異同呢?
先看看理論分析。
開啟KeepAlive 後,意味著每次使用者完成全部訪問後,都要保持一定時間後才關閉會關閉TCP 連線,那麼在關閉連線之前,必然會有一個Apache行程對應於該使用者而不能處理其他使用者,假設KeepAlive 的超時時間為10 秒種,伺服器每秒處理 50個獨立使用者訪問,那麼系統中 Apache 的總行程數就是 10 * 50 = 500 個,如果一個行程佔用 4M 記憶體,那麼總共會消耗 2G記憶體,所以可以看出,在這種配置中,相當消耗記憶體,但好處是系統只處理了 50次 TCP 的握手和關閉操作。
如果關閉KeepAlive,如果還是每秒50個使用者訪問,如果使用者每次連續的請求數為3個,那麼 Apache 的總行程數就是 50 * 3= 150 個,如果還是每個行程佔用 4M 記憶體,那麼總的記憶體消耗為 600M,這種配置能節省大量記憶體,但是,系統處理了 150 次 TCP的握手和關閉的操作,因此又會多消耗一些 CPU 資源。
再看看實踐的觀察。
我在一組大量處理動態網頁內容的伺服器中,起初開啟KeepAlive功能,經常觀察到使用者訪問量大時Apache行程數也非常多,系統頻繁使用交換記憶體,系統不穩定,有時負載會出現較大波動。關閉了KeepAlive功能後,看到明顯的變化是:Apache 的行程數減少了,空閑記憶體增加了,用於檔案系統Cache的記憶體也增加了,CPU的開銷增加了,但是服務更穩定了,系統負載也比較穩定,很少有負載大範圍波動的情況,負載有一定程度的降低;變化不明顯的是:訪問量較少的時候,系統平均負載沒有明顯變化。
總結一下:
在記憶體非常充足的伺服器上,不管是否關閉KeepAlive 功能,伺服器效能不會有明顯變化;
如果伺服器記憶體較少,或者伺服器有非常大量的檔案系統訪問時,或者主要處理動態網頁服務,關閉KeepAlive 後可以節省很多記憶體,而節省出來的記憶體用於檔案系統Cache,可以提高檔案系統訪問的效能,並且系統會更加穩定。
補充1
關於是否應該關閉 KeepAlive 選項,我覺得可以基於下麵的一個公式來判斷。
在理想的網路連線狀況下,系統的Apache 行程數和記憶體使用可以用如下公式表達:
HttpdProcessNumber= KeepAliveTimeout * TotalRequestPerSecond / Average(KeepAliveRequests)
HttpdUsedMemory= HttpdProcessNumber * MemoryPerHttpdProcess
換成中文意思:
總Apache行程數 = KeepAliveTimeout * 每秒種HTTP請求數 / 平均KeepAlive請求
Apache佔用記憶體 = 總Apache行程數 * 平均每行程佔用記憶體數
需要特別說明的是:
[平均KeepAlive請求] 數,是指每個使用者連線上伺服器後,持續發出的 HTTP 請求數。當 KeepAliveTimeout 等 0或者 KeepAlive 關閉時,KeepAliveTimeout 不參與乘的運算從上面的公式看,如果 [每秒使用者請求]多,[KeepAliveTimeout] 的值大,[平均KeepAlive請求] 的值小,都會造成 [Apache行程數] 多和 [記憶體]多,但是當 [平均KeepAlive請求] 的值越大時,[Apache行程數] 和 [記憶體] 都是趨向於減少的。
基於上面的公式,我們就可以推算出當 平均KeepAlive請求 <= KeepAliveTimeout 時,關閉 KeepAlive 選項是划算的,否則就可以考慮開啟。
補充2
KeepAlive 該引數控制Apache是否允許在一個連線中有多個請求,預設開啟。但對於大多數論壇型別站點來說,通常設定為off以關閉該支援。
補充3
如果伺服器前跑有應用squid服務,或者其它七層裝置,KeepAlive On 設定要開啟持續長連線
實際在 前端有squid 的情況下,KeepAlive 很關鍵。記得On。
Keeyalive不能隨心所欲設定,而是需要根據實際情況,我們來看一個真實的在我工作中發生的搞笑一次事件:
當時我已經離開該專案了,該專案的TeamLeader看到了keepalive的概念,他只看到了關閉keeyalive可以節省web伺服器的記憶體,當時我們的web伺服器只有4gb記憶體,而併發請求的量很大,因此他就把這個keepalive設成了off。
然後直接導致離線客戶端(離線客戶端用的是.net然後webservice連線)的“login”每次都顯示“出錯”。
一查程式碼才知道,由於這個離線客戶端使用的是webservice訪問,.net開發團隊在login功能中設了一個超時,30秒,30秒timeout後就認為伺服器沒有開啟,結果呢由於原來的apache設的是keeyalive和timeout 15秒,現在被改成了off,好傢伙,根本就沒有了這個timeout概念,因此每次.net登入直接被apache彈回來,因為沒有了這個timeout的介面了。
由此可見,學東西。。。不能一知半解,務必求全面瞭解哈。
3.8 HostnameLookups設定為off
儘量較少DNS查詢的次數。如果你使用了任何”Allow fromdomain”或”Denyfrom domain”指令(也就是domain使用的是主機名而不是IP地址),則代價是要進行兩次DNS查詢(一次正向和一次反向,以確認沒有作假)。所以,為了得到最高的效能,應該避免使用這些指令(不用域名而用IP地址也是可以的)。
系列
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能


{kind=link}