小編現在每天思考最多的問題就是
到底什麼時候能發財啊!!!
再看看每個月工資卡裡的錢
真的是隻能以45度角仰望天空

一直以來,年底都是離職的高峰期
嗑著瓜子,刷著51job
學習Python也有幾個月了,
該考慮換工作啦,
看了眼招聘網站,就像這樣~

資訊玲琅滿目不知該怎麼辦了,這時候,我想到了Python爬蟲,如果能把資訊都下載下來,可以隨時隨地的分析,這樣一定可以找到稱心如意的工作
一、準備工作
語言:Python3
工具:Pycharm,firefox
技術:requests,BeautifulSoup,re,csv
二、流程概述
爬取51JOB相關工作第一頁,獲得頁數
然後開始爬蟲
獲得每一頁詳細資訊連結
透過連結獲取詳細資訊
存入CSV檔案
三、具體實現
a)使用瀏覽器前往51JOB開啟開發者工具,進行搜尋,我們選擇http://m.51job.com/,一般來說大型網站的PC端會有反爬蟲措施,相對起來移動端會容易點,不過51的PC端也很容易爬,只是不喜歡那個頁面風格而已。


這樣資訊就一覽無遺了,從右邊的視窗我們能看到url,引數,以及響應頁面


所以我們只要填寫引數所有的資料要求,我們便能等到一串HTML程式碼,這就是我們要爬取的內容了。
b)我們需要先直接請求第一頁,獲取總數,使用requests獲取資料,然後使用bs解析,這兩個python庫,API都很簡單並且都比較輕量,很適合初學者學習使用,利用正則運算式獲取總工作數量
數了下大約一頁可以顯示30條記錄,那我們就能得出需要爬的頁數

c)從密密麻麻的HTML中我們點開形如“http://m.51job.com/search”這樣的連結,工作的詳細資訊映入我們眼簾,這就是我們資料的來源,我們把獲得的連結存入一個串列中,便於我們接下來的呼叫。HTML我們使用BS4解析,BS4有四種解析器,lxml是需要安裝C語言庫的,我們可以使用html.parser庫,lxml速度快但是在這個專案裡並沒有多明顯。

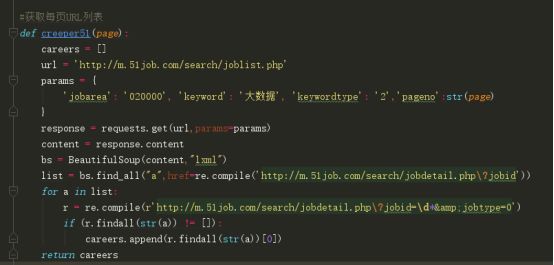
d)點開連結,我們需要的資訊一目瞭然,從中我們選取我們需要的資訊,可以直接使用bs的方法獲取,也可以使用正則運算式提取相關段落。特別註意的是有些欄位在某些頁面是不存在的,比如工作經驗,需要判斷。


e)最後便是把資訊插入到csv檔案中,大家也可以使用mysql,mongoDB等工具存放資料。
這裡特別註意的是,使用”w”樣式寫,會有空行,但是使用二進位制”wb”樣式會報二進位制與字串不匹配,所以在開啟時候加入引數newline=’’,會避免空行。


最後完成如上圖,可以使用熟悉的Excel軟體進行排序操作,隨時隨地可以查看了。
Python作為現在最流行的一種語言之一,以其編寫簡單不羅嗦,類庫數量龐大而著稱。自從學習了python,厚重的JAVA早被我拋到九霄雲外了,日常編寫點應用類工具什麼的真的特別方便。
編寫應用並不困難,只要思路理清了,對流程進行分解,按塊來程式設計,最後組裝起來,如果錯了,直接修改出錯的塊,並不需要動整個程式碼。
看了上文介紹的如何用 找工作
找工作
是不是看文字還不夠具體?
小編下週還為你精心準備了三個 的影片直播課。
的影片直播課。
手把手的教你如何用Python抓取資料。

趙瑾
資料分析講師,多年開發經驗,擅長JavaScript,Python, MATLAB,SASS等語言,對於資料視覺化有獨特見解,曾參與工商銀行網站建設,某電商平臺的設計,開發,及最後測試上線全部流程。
主題:人工智慧的時代已來,不要讓自己輸在起跑線上
課程收益
1、分塊解析:“人工智慧”是什麼
2、行業內情:人工智慧就業前景如何,真的有那麼好嗎?
3、實戰教學:python語言環境
直播時間:1月29日週一19:30-21:30
主題:2小時破冰爬蟲技術 – 抓取51job職位資訊
課程收益
1、直白解答:海量資料從哪來?
2、乾貨分享:爬蟲抓取資料的有哪些流程?
3、實戰教學:python實現(BeautifulSoup)
直播時間:1月31日週三19:30-21:30
主題:人工智慧應用:垃圾郵件分類技巧解析
課程收益
1、掌握貝葉斯公式
2、掌握垃圾郵件過濾原理
3、郵箱過濾技術實操演示
直播時間:2月2日週五19:30-21:30
掃碼關註公眾號

回覆“直播”即可獲得免費看課的資格~

更多驚喜請閱讀原文
