
讓我們一起攻破世界上最流行的WordPress的驗證碼外掛
每個人都討厭驗證碼——在你被允許訪問一個網站之前,你總被要求輸入那些煩人的影象中所包含的文字。
驗證碼被設計成,以驗證你是一個真正的人的方式,來防止電腦自動填寫表單。但是隨著深度學習和計算機視覺的興起,它們現在往往很容易被攻破。
我在讀Adrian Rosebrock的優秀的著作《Python計算機視覺深度學習》。在書中,Adrian簡單地描述了他如何用機器學習繞過E-ZPass New York網站的驗證碼:
Adrian沒有訪問生成驗證碼圖片的應用的原始碼的許可權。為了破解這個系統,他不得不下載成百上千個示例影象並手動解答它們,用以訓練他的深度學習系統。
但是如果我們想打破一個開放原始碼的驗證碼系統,將會怎麼樣?
我去wordpress.org外掛登錄檔搜尋“驗證碼”。最靠前的結果是一個叫“真正簡單的驗證碼”的外掛,有超過100萬個活躍安裝:

並且最好的一點是,它開源!因為我們有生成驗證碼的原始碼,那麼這應該是很容易破解的。為了讓事情更有挑戰性,讓我們給自己一個時間限制。我們是否能夠在15分鐘內破解這個驗證碼系統?讓我們試試看!
重要提示:這絕不是針對“真正簡單的驗證碼”這個外掛或它的作者的批評。外掛作者本人也說,這個外掛不再安全,建議您使用其他東西。這隻是一個快速而有趣的技術挑戰。但是如果你是剩下的100萬個使用者中的一個,也許你應該切換到其他外掛:)
挑戰開始
為了打造一個進攻計劃,讓我們先來看看這個外掛會生成哪種型別的圖片。在演示站點上,我們看到這個:

好的,所以驗證碼影象似乎是四個字母。讓我們在PHP原始碼中驗證這一點:

是的,它會產生一個四字母的驗證碼,並採用隨機組合的四種不同的字型。我們可以看到,它從不在程式碼中使用“O”或“I”,以避免使用者混淆。這給了我們總共32個可能需要識別的字母和數字。沒問題!
到目前為止時間過去:2分鐘。
我們的工具集
在我們進一步討論之前,讓我們說一下為瞭解決這個問題我們將會用到的工具:
Python3
Python是一種非常有趣的程式語言,它有很好的機器學習和計算機視覺庫。
OpenCV
OpenCV是一種流行的計算機視覺和影象處理框架。我們將使用OpenCV來處理驗證碼影象。
它有一個Python應用介面,因此我們可以直接從Python中使用它。
Keras
Keras是一個由Python寫的深度學習的框架。它可以使我們用最少的程式碼,方便地定義、訓練和使用深層神經網路。
TensorFlow
TensorFlow是谷歌的機器學習庫。我們會在Keras中寫程式碼,但Keras並沒有真正實現神經網路的邏輯本身,它其實是在後臺呼叫谷歌的TensorFlow進行計算。
好,現在讓我們回到挑戰!
創造我們的資料集
訓練任何機器學習系統,我們都需要訓練資料集。破解一個驗證碼系統,我們則需要訓練資料看起來像這樣:
 由於我們有這個WordPress的驗證碼外掛的原始碼,我們可以對它做一些更改,讓它儲存出10000張驗證碼影象以及每個影象的正確答案。
由於我們有這個WordPress的驗證碼外掛的原始碼,我們可以對它做一些更改,讓它儲存出10000張驗證碼影象以及每個影象的正確答案。
花了幾分鐘時間,在適當地修改原始碼並新增一個簡單的for後,我得到了一個包含訓練資料的檔案夾 —— 10000個PNG檔案,每個檔案都以正確答案作為檔案名:

這是唯一我不會給你示例程式碼的部分。我們這樣做是為了教育,我不想讓你真的去黑WordPress網站。不過,我會給你我最後生成的這10000張影象,以便你可以重覆我的結果。
到目前為止時間過去:5分鐘。
簡化問題
現在我們有了訓練資料,我們可以直接用它來訓練神經網路:

有足夠的訓練資料,這種粗暴的方法甚至也行得通 - 但我們可以使問題更容易解決。問題越簡單,訓練資料越少,計算資源消耗就越少。畢竟我們只有15分鐘!
幸運的是,驗證碼影象總是由四個字母組成。如果我們能用某種方式把影象分割開來,這樣每一個字母都是一個獨立的影象,那麼我們只需要訓練神經網路一次識別一個字母:

我沒有時間瀏覽10000個訓練影象,併在Photoshop中手動將它們分割成單獨的影象。這將需要幾天,而我只剩下10分鐘了。
而且我們不能將影象分成四個相同大小的塊,因為驗證碼會將這些字母隨機放置在不同的水平位置:

每個影象中的字母隨機放置,使分割影象更難一些。
幸運的是,我們仍然可以自動執行此操作。在影象處理中,我們經常需要檢測具有相同顏色的畫素團。這些連續畫素團周圍的邊界被稱為輪廓。OpenCV有一個內建的findContours()函式,可以用來檢測這些連續的區域。
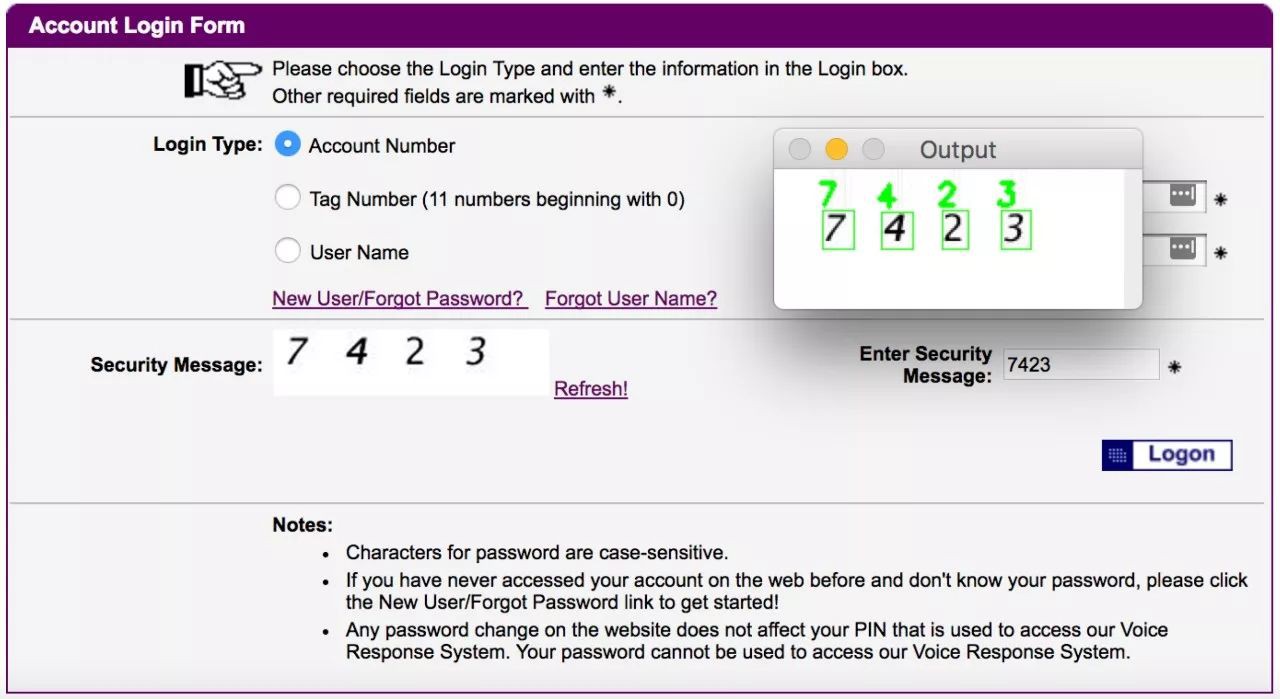
那麼我們將從一個原始的驗證碼影象開始:
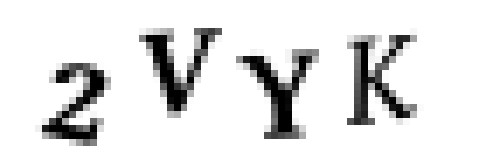
然後,我們將影象轉換為純黑白(這稱為閾值設定),這樣就很容易找到連續的區域:
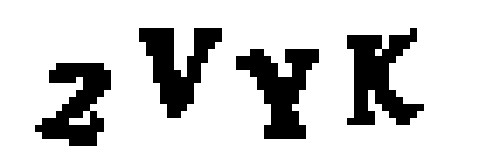
接下來,我們將使用OpenCV的findContours()函式來檢測影象中各個包含相同顏色畫素的連續團:

那麼只需將每個區域儲存為一個單獨的影象檔案即可。而且由於我們知道每個影象應該包含從左到右的四個字母,所以我們可以使用這些知識來標記字母。只要我們按順序儲存它們,我們能夠用適當的字母名稱儲存每個字母影象。
但是等等 —— 我看到一個問題! 有時候驗證碼有這樣的重疊字母:
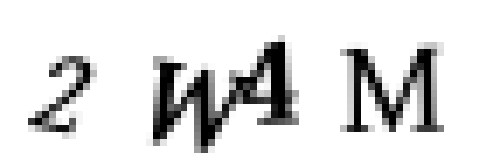
這意味著我們最終將提取將兩個字母拼湊在一起的區域:

如果我們不處理這個問題,我們最終會建立糟糕的訓練資料。我們需要解決這個問題,以免我們不小心讓機器把這兩個相連的字母識別為一個字母。

我們將把任何寬度比高度還長的區域對半分開,並把它當作兩個字母。這是很粗暴,但這麼處理對識別這些驗證碼依然行得通。
現在我們有了一種提取單個字母的方法,讓我們在所有的CAPTCHA影象上執行它。標的是收集每個字母的不同變化。我們可以將每個字母儲存在自己的檔案夾中。
下麵是我提取所有字母后,我的“W”檔案夾的樣子:

從我們的10000個驗證碼影象中提取的一些“W”字母。我一共得到了1147個不同的“W”影象。
到目前為止時間過去:10分鐘。
建立和訓練神經網路
由於我們只需要識別單個字母和數字的影象,我們不需要一個非常複雜的神經網路架構。識別字母比識別諸如貓和狗的圖片這樣的複雜影象要容易得多。
我們將使用具有兩個摺積層和兩個完全連線層的簡單摺積神經網路結構:

如果你想知道更多關於摺積神經網路是如何工作的,為什麼他們被用作影象識別非常理想,請檢視Adrian的書或我以前的文章。
用Keras定義這個神經網路體系結構只需要使用幾行程式碼:
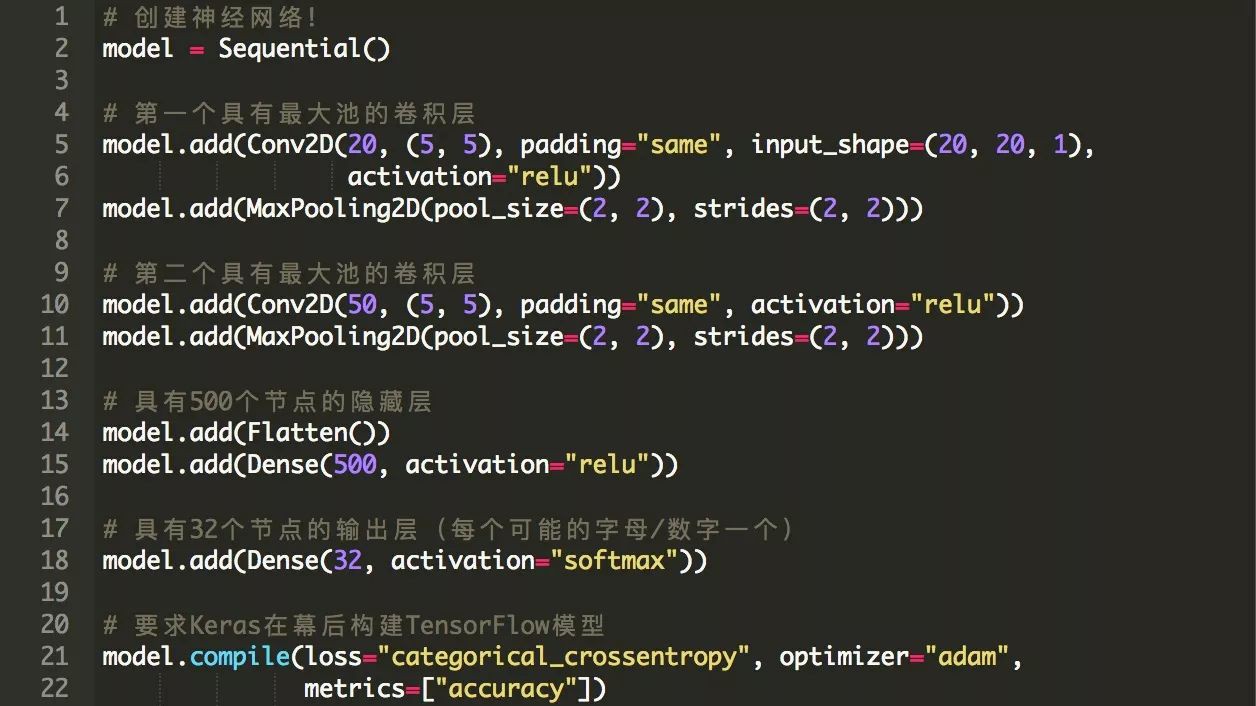
現在,我們可以開始訓練它了!

用訓練資料集訓練10次後,我們達到了近100%的準確度。現在,只要我們想,我們應該能夠自動繞過這個驗證碼了!我們做到了!
到目前為止時間過去:15分鐘。(~!)
使用訓練的模型破解驗證碼
現在,我們有一個訓練有素的神經網路,用它來破解真正的驗證碼非常簡單:
1.從使用該WordPress外掛的網站抓取真實的驗證碼影象。
2.使用我們用來建立訓練資料集的相同方法,將驗證碼影象分解為四個單獨的字母影象。
3.要求我們的神經網路對每個字母影象做一個單獨的預測。
4.使用四個預測字母作為驗證碼的答案。
5.愉快的玩耍吧
以下是我們的模型如何解碼真正的驗證碼

或者從命令列

試試看吧!
如果你想親自嘗試一下,你可以在這裡獲取程式碼。它包括10000個示例影象和本文中每個步驟的所有程式碼。檢視裡面的README.md檔案,瞭解如何執行它。
但是,如果你想瞭解每一行程式碼究竟做了什麼,我強烈建議你也弄一本《Python計算機視覺深度學習》。它有更多的細節,並有大量的詳細的例子。這是迄今為止我所見過的唯一的一本,既涵蓋了工作原理又涵蓋了在現實世界中如何解決難題的書。去看看吧!
英文原文:https://ogmcsrgk5.qnssl.com/vcdn/1/%E4%BC%98%E8%B4%A8%E6%96%87%E7%AB%A0%E9%95%BF%E5%9B%BE/how-to-break-a-captcha-system-in-15-minutes-with-machine-learning-dbebb035a710.png
譯者:浙南菌
來源:Python部落
————近期開班————
馬哥聯合BAT、豆瓣等一線網際網路Python開發達人,根據目前企業需求的Python開發人才進行了深度定製,加入了大量一線網際網路公司:大眾點評、餓了麼、騰訊等生產環境真是專案,課程由淺入深,從Python基礎到Python高階,讓你融匯貫通Python基礎理論,手把手教學讓你具備Python自動化開發需要的前端介面開發、Web框架、大監控系統、CMDB系統、認證堡壘機、自動化流程平臺六大實戰能力,讓你從0開始蛻變成Hold住年薪20萬的Python自動化開發人才。
10期面授班:2018年03月05號(北京)
11期網路班:2018年03月17號(網路)

 掃描二維碼領取學習資料
掃描二維碼領取學習資料

更多Python好文請點選【閱讀原文】哦
↓↓↓
