背景
在MQ裡,順序訊息的意思是消費訊息的順序和訊息傳送時(單機傳送)的順序保持一致。比如ProducerA按照順序傳送msga, msgb, msgc三條訊息,那麼consumer消費的時候也應該按照msga, msgb, msgc來消費。
對於順序訊息,在我們實際使用中發現,大部分業務系統並不需要或者並不依賴MQ提供的順序機制,這些業務本身往往就能處理無序的訊息,比如很多系統中都有狀態機,是否消費訊息必鬚根據狀態機當前的狀態。
但是在一些場景中順序訊息也有其必要性:比如日誌收集和依賴binlog同步驅動業務等。就這兩個場景而言,同樣是順序訊息但對順序的需求卻不一定一樣:比如日誌收集中我們一般認為對順序的要求比較弱,即絕大多數時是有序即可,遇到一些極端情況,比如Server宕機,容量調整的時候我們可以暫時容忍一些無序。但是對於一個依賴MySQL binlog同步來驅動的業務,短暫的無序都將會導致整個業務的錯亂。
分析現有的一些MQ後發現,它們並不能在所有情況下提供可靠的順序支援。現在市面上的MQ基本上都是以partition – based模型來提供順序支援。我們以Kafka為例:topic分為一個或多個partition,partition可以理解為一個順序檔案,producer傳送訊息的時候,按照一定的策略選擇partition,比如partition = hash(key) % partition num來選擇該訊息傳送給哪個partition,那麼具有相同key的訊息就會落到相同的partition上,而consumer消費的時候一個consumer獨佔地系結在一個partition上。這樣一來,訊息就是順序消費的了:

但是這種模型存在一些問題:
-
partition的個數就是消費的並行度,那麼如果現在consumer處理不過來需要增加consumer則需要對應地增加partition。而根據上面的描述partition的個數一旦改變,則順序將無法保證(partition = hash(key) % partition num 公式裡partition num發生了改變,則選擇的partition也會發生變化)。
所以我們一般在業務上線之前,就要做出合理的容量規劃,預先創建出足夠的partition,但有的時候容量規劃是困難的,實踐中往往是預先分配大量的partition,比如幾百甚至幾千,然而大量的partition對效能以及運維都帶來麻煩。
-
擴容partition後,如果高峰期已過,想進行縮容則基本上不可行(比如Kafka就不允許減少partition),除了縮容帶來順序變化外,還有一點是怎麼保證被縮容的partition上的訊息已經完全消費完成了呢?
-
partition的移動問題,partition如果分配在某臺broker上之後再移動就很麻煩,一旦這臺broker容量不足,需要進行負載均衡就很困難了,這可能需要在不同的機器上傳輸大量的資料。
-
對可用性的挑戰,順序傳送的時候某個key的訊息必須總是傳送給指定的partition的,如果一旦某臺server掛掉,或者正常的停機維護,那麼位於這臺server的partition就不能收訊息了,但是也不能傳送給其他partition,否則順序就會錯亂。
雖然我們可以透過多副本機制(Replication)來確保即使該partition所在機器出現故障時候仍然有其他副本提供服務,但是一般選舉出一個新的副本通常需要花費幾秒到幾分鐘不等(比如早期的Kafka版本Leader遷移是序列執行的,在分割槽特別多的時候,選舉出新的leader可能需要分鐘級時間),在此期間傳送到該partition的所有訊息都無法傳送。
-
堆積問題,如果預分配時候的partition過少,這個時候堆積了大量的訊息,那麼即使擴容也沒有辦法了:

所以我們認為現有的一些所謂順序訊息機制並不是簡單可依賴的。你以為MQ給你提供了順序保障,但實際上在一些時候並不是這樣,那麼這個時候使用方為了應對這種異常情況就需要做出各種應對措施,增加了使用的複雜度。而我們希望提供一種簡單可依賴的順序訊息,也就是使用方可以放心的將順序保證交給MQ。
方案設計
首先我們來分析無法保證順序的根源是什麼。我們選擇partition所使用的公式是 partition = hash(key) % partition num。正是因為partition num發生了變化導致公式的結果發生了變化,進而打破了順序保證。
其實對於這個公式我們可能並不陌生,除了在MQ中使用,我們在資料庫分庫分表中往往也有這種套路。
在資料庫分庫分表中我們會透過一個分割槽鍵計算其分割槽,然後得到表名或庫名(如下偽程式碼所示,user_id是分表鍵,總共分為100張表):

而且在分庫分表中前期因為業務量不大,我們往往不會分很多庫(或者我們也分了多個庫,但是這些庫都落在相同的機器上),但是為了後期新增分庫方便(擴容)我們會預先分出很多表。比如我們前期分成100張表,但是這100張表都在相同的庫裡,待到業務增長之後,單庫無法支撐,我們會將100張表劃分到不同的DB裡。
比如我們將表0 – 50落在DB1, 50 – 100落到DB2,這樣我們的處理能力就翻倍了,但是因為程式裡還是按照100進行分表的,所以對應用沒有感知。
這種機制相當於引入了一個中間層,程式面對的是的分表,最後這個表是落在什麼DB上透過中間層進行對映過去就可以了。
那麼其實我們是可以借鑒這種思路應用在MQ的擴容縮容中的。為此我們引入了logic partition的概念。也就是Producer傳送訊息的時候,我們並不決定它傳送到哪個具體的Server上的具體的partition裡(後文將其稱之為物理partition, physical partition)。我們只是先得到logic partition,使用這個計算公式: logic partition = hash(key) % logic partition num。而logic partition num我們會固定住,永不改變。比如我們將logic partition num固定為1000。但是這裡跟分庫分表中的分1000張表不同,logic partition僅僅是邏輯上的,不存在任何儲存物體,所以即使分配的再大也沒有效能上的開銷。計算得到logic partition後,我們根據logic partition的對映再來決定該訊息應該落到具體哪個physical partition上。我們會根據logic partition的範圍進行對映,比如logic partition 0 – 500 對映到 physcial partition 1上,500 – 1000 對映到physcial partition 2上。
接下來我們來看看這種措施如何應對本文開頭所提出的一序列問題呢:
-
擴容 在這裡擴容其實就是對physical partition的分裂過程。比如開始時我們建立了兩個分割槽: physical partition 1, physical partition 2,因為消費不過來,我們要將physcial partiton 1擴容,那麼我們將會得到 logic partiton 0 – 250 對映到physical partition 3,logic partition 250 – 500 對映到physical partition 4(註:範圍的分裂不一定是平均的,比如我們也可以按照[0 – 200)和[200 – 500)進行劃分 )。
-
縮容 縮容其實就是對physical partition的合併過程,我們將physical partiton 3和physical partition 4合併得到physical partition 5。那麼現在logic partiton 0 – 500就對映到physical partition 5。
-
負載均衡 負載均衡其實就是logic partition到physical partiton的重新對映過程。也就是原來0 – 500 對映到 physical partition 5,現在我們將其對映到physical partition 6,而physical partition 6可以分配在一臺空閑的Server上。不僅如此,重新對映也可以解決可用性問題:一臺server停機維護時將落在上面的logic partition進行重新對映,分配到另外一臺Server上即可,這樣我們就可以打造Always writtable ordered message queue。
這裡借鑒分庫分表中的預先分表的方法,提出logic partition的抽象層解決物理partition擴容縮容時無法保證順序的問題。但是實際實現時候我們會發現MQ的這種logic partition分法要比資料庫中分表複雜得多。因為MQ是的消費是持續性的,也就是我可以讀取歷史資料。資料庫中分庫分表一旦調整之後,那麼它呈現的就是最終檢視,而MQ裡昨天我們可能還只有一個physical partition,今天我們劃分為兩個,那麼我們消費昨天的資料和今天的資料的時候如何進行無縫的切換呢?
我們先簡單總結一下上面對擴容縮容移動的描述:
-
擴容即對physical partition按照logic partition的範圍進行分裂的過程
-
縮容即按照logic partition的範圍對physical partition進行合併的過程
-
移動即改變logic partition與physical partition的對映的過程
雖然我們從Database的分庫分表思想中學習到了logic partition,但是Message Queue和Database究竟是兩種不同的模型。在DB裡,reader是無狀態的,也就是每次讀取傳入的查詢條件都是獨立的。而MQ的reader(consumer)當前的讀取位置(offset)是依賴上次的讀取位置,一旦partition發生改變,則這個offset將無法繼續保持,那消費就會錯亂了,順序也無從談起。另外因為資料量太大,我們在執行擴容縮容移動的時候並不想對資料進行移動。
接下來以實際的例子來進行說明,下麵是一個擴容的實體。order.changed這個主題,原來分配了P1, P2兩個分割槽,現在因為容量不夠,需要對P2進行擴容(分裂)。也就是將physical partition P2進行分裂,分裂成P3, P4兩個分割槽。分裂的原則是按照logic partition的範圍進行,logic partition [500, 1000)原來對映到P1,現在logic partition [500, 750)對映到P3, [750, 1000)對映到P4。也就是分裂以後producer傳送新的訊息就會按照新的對映關係將訊息append到P1, P3或P4,P2不再接收新的訊息了。

接下來具體描述一下實現步驟。在QMQ裡有個metaserver的元件,它管理所有元資料資訊,比如某topic分配到哪些partition上(我們將其稱之為路由):

metaserver還管理partition分配在哪些server上,以及logic partition與physical partition的對映關係。
在需要對P2進行分裂的時候,metaserver會傳送一條訊息給P2所在的server,這條訊息會被append到P2上,該訊息稱之為指令訊息(command message),對客戶端不可見,也就是業務程式碼不會消費到這條訊息。P2收到這條指令訊息後將不再接收新的訊息了,所有業務訊息均被拒絕,那麼這條指令訊息就是P2上的最後一條訊息,相當將P2關閉了。
metaserver傳送完指令訊息後會變更對應topic的路由資訊:
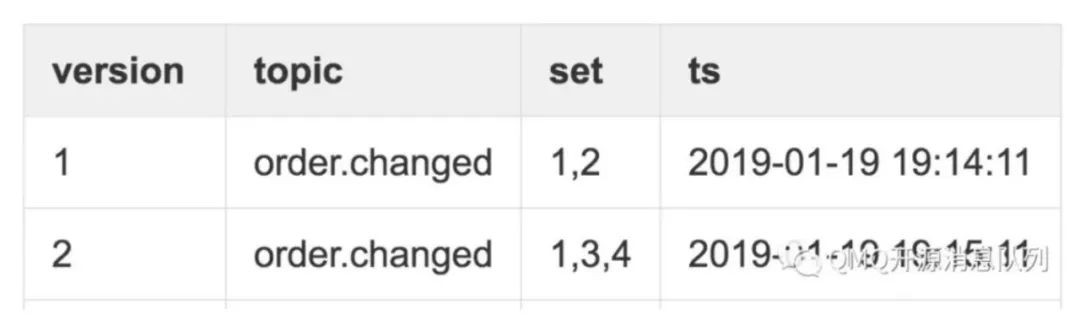
註意看上面的表格的特點,這個路由資訊表與眾不同的地方在於它有一個version欄位。對於producer而言它總是獲取最新版本的路由資訊,也就是路由發生變更後,producer就會獲得更高版本的路由資訊,然後向這些分割槽上傳送訊息。
但是對於consumer來講,它必須將前面的訊息消費完成才能消費後面的,否則順序就亂了。比如前面分裂的示例,P2分裂為P3, P4了,這個時候P3, P4並不是立即對consumer可見的(只要對consumer不可見,就沒有consumer來消費它)。只有當consumer消費到指令訊息時,才會觸發consumer的路由變更。並且指令訊息裡攜帶了路由的版本資訊,假設路由已經發生了多次變更,consumer消費到某個指令訊息的時候,只會將consumer的路由變更到該指令的下一個版本,而不會跳到其他版本,這裡觸發路由變更的時候會使用樂觀鎖去更新版本(偽程式碼):

總結起來就是producer總是使用最新版本的路由,而consumer使用指定版本的路由,路由的版本由指令訊息進行同步。
其實這個流程中最有趣的不是擴容(分裂)和縮容(合併),而是移動。比如我們現在發現P4分割槽所在機器負載比較高或磁碟就要滿了,現在給叢集加了幾臺機器,怎麼做能在繼續保持順序的基礎上又能將負載分散過去呢?那麼只需要傳送一個移動的指令訊息給P4,然後P4就會關閉,然後變更路由,order.changed的路由現在是P1, P3, P5,這次路由變更分割槽的個數沒有發生改變,改變的只是logic partition和physical partition的對映關係:

因為P5是新分割槽,所以他可以分配在新機器上了。而且這個特性可以用在提高順序訊息的可用性上,比如需要對某臺server停機,那麼我們只需要對其上面所有分割槽傳送移動指令即可。
另外,在實現的時候我們還增加瞭如下約束條件:
-
版本必須是連續遞增的
-
每次只能執行一項變更,比如只能對一個partition分裂,不能對多個partition進行分裂
-
對logic partition範圍的每次操作必須是連續的,比如合併的時候只能將[0, 100) 與[100, 200)合併,而不能將[0, 100)與[200, 300)合併
-
路由變更必須是本次變更分割槽所有的消費者都確認執行到指令訊息才能觸發。比如將多個分割槽合併的時候,必須是這幾個分割槽都消費到了指令訊息的時候觸發。
總結
上面以示例的方式描述了QMQ如何進行擴容(分裂),那麼只需要按照這個步驟進行,consumer在沒有將更早的訊息消費完成的情況下就不會拿到更新的路由。
至於如何確保順序的消費這些分割槽的訊息那就跟其他MQ一樣了,只需要將分割槽分配給指定的consumer實體,只允許指定的實體獨佔消費該分割槽即可。
QMQ是去哪兒網開源的分散式訊息中介軟體,在去哪兒網內部應用十分廣泛,提供了很獨特的儲存模型,延時訊息,事務訊息等。點選原文連結就會跳到github地址(https://github.com/qunarcorp/qmq),歡迎給我們提交PR, Star。
