來自:孤獨煙(微訊號:zrj_guduyan)
摘要
企業千萬家,靠譜沒幾家。
社招選錯家,親人兩行淚。
祝大家金三銀四跳槽順利!
引言
開始我們的內容,相信大家一定遇到過下麵的一個面試場景
面試官:“講講mysql有幾個事務隔離級別?”
你:“讀未提交,讀已提交,可重覆讀,序列化四個!預設是可重覆讀”
面試官:“為什麼mysql選可重覆讀作為預設的隔離級別?”
(你面露苦色,不知如何回答!)
面試官:”你們專案中選了哪個隔離級別?為什麼?”
你:“當然是預設的可重覆讀,至於原因。。呃。。。”
(然後你就可以回去等通知了!)
為了避免上述尷尬的場景,請繼續往下閱讀!
Mysql預設的事務隔離級別是可重覆讀(Repeatable Read),那網際網路專案中Mysql也是用預設隔離級別,不做修改麼?
OK,不是的,我們在專案中一般用讀已提交(Read Commited)這個隔離級別!
what!居然是讀已提交,網上不是說這個隔離級別存在不可重覆讀和幻讀問題麼?不用管麼?好,帶著我們的疑問開始本文!
正文
我們先來思考一個問題,在Oracle,SqlServer中都是選擇讀已提交(Read Commited)作為預設的隔離級別,為什麼Mysql不選擇讀已提交(Read Commited)作為預設隔離級別,而選擇可重覆讀(Repeatable Read)作為預設的隔離級別呢?

Why?Why?Why?
這個是有歷史原因的,當然要從我們的主從複製開始講起了!
主從複製,是基於什麼複製的?
是基於binlog複製的!這裡不想去搬binlog的概念了,就簡單理解為binlog是一個記錄資料庫更改的檔案吧~
binlog有幾種格式?
OK,三種,分別是
-
statement:記錄的是修改SQL陳述句
-
row:記錄的是每行實際資料的變更
-
mixed:statement和row樣式的混合
那Mysql在5.0這個版本以前,binlog只支援STATEMENT這種格式!而這種格式在讀已提交(Read Commited)這個隔離級別下主從複製是有bug的,因此Mysql將可重覆讀(Repeatable Read)作為預設的隔離級別!
接下來,就要說說當binlog為STATEMENT格式,且隔離級別為讀已提交(Read Commited)時,有什麼bug呢?如下圖所示,在主(master)上執行如下事務
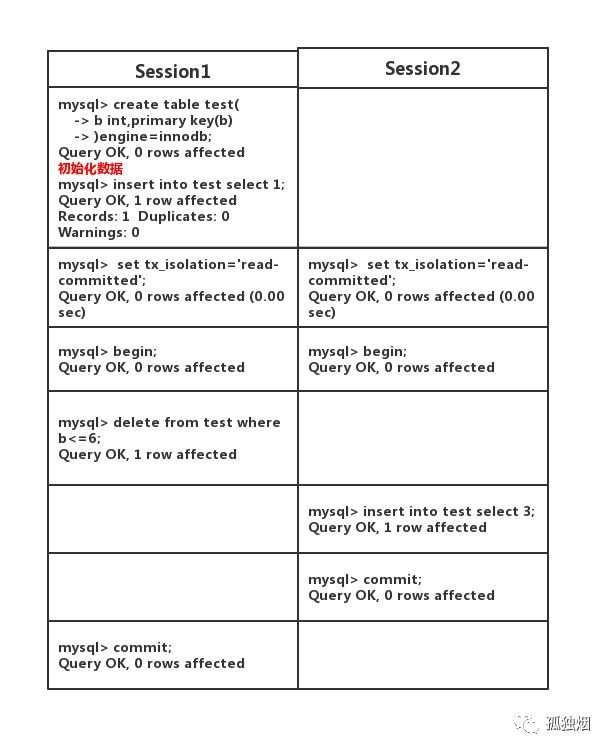
此時在主(master)上執行下列陳述句
select * from test;
輸出如下
+---+
| b |
+---+
| 3 |
+---+
1 row in set
但是,你在此時在從(slave)上執行該陳述句,得出輸出如下
Empty set
這樣,你就出現了主從不一致性的問題!原因其實很簡單,就是在master上執行的順序為先刪後插!而此時binlog為STATEMENT格式,它記錄的順序為先插後刪!從(slave)同步的是binglog,因此從機執行的順序和主機不一致!就會出現主從不一致!
如何解決?
解決方案有兩種!
(1)隔離級別設為可重覆讀(Repeatable Read),在該隔離級別下引入間隙鎖。當Session 1執行delete陳述句時,會鎖住間隙。那麼,Ssession 2執行插入陳述句就會阻塞住!
(2)將binglog的格式修改為row格式,此時是基於行的複製,自然就不會出現sql執行順序不一樣的問題!奈何這個格式在mysql5.1版本開始才引入。因此由於歷史原因,mysql將預設的隔離級別設為可重覆讀(Repeatable Read),保證主從複製不出問題!
那麼,當我們瞭解完mysql選可重覆讀(Repeatable Read)作為預設隔離級別的原因後,接下來我們將其和讀已提交(Read Commited)進行對比,來說明為什麼在網際網路專案為什麼將隔離級別設為讀已提交(Read Com
對比
ok,我們先明白一點!專案中是不用讀未提交(Read UnCommitted)和序列化(Serializable)兩個隔離級別,原因有二
- 採用讀未提交(Read UnCommitted),一個事務讀到另一個事務未提交讀資料,這個不用多說吧,從邏輯上都說不過去!
- 採用序列化(Serializable),每個次讀操作都會加鎖,快照讀失效,一般是使用mysql自帶分散式事務功能時才使用該隔離級別!(筆者從未用過mysql自帶的這個功能,因為這是XA事務,是強一致性事務,效能不佳!網際網路的分散式方案,多採用最終一致性的事務解決方案!)
也就是說,我們該糾結都只有一個問題,究竟隔離級別是用讀已經提交呢還是可重覆讀?
接下來對這兩種級別進行對比,講講我們為什麼選讀已提交(Read Commited)作為事務隔離級別!
假設表結構如下
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`color` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
資料如下
+----+-------+
| id | color |
+----+-------+
| 1 | red |
| 2 | white |
| 5 | red |
| 7 | white |
+----+-------+
為了便於描述,下麵將
- 可重覆讀(Repeatable Read),簡稱為RR;
- 讀已提交(Read Commited),簡稱為RC;
緣由一:在RR隔離級別下,存在間隙鎖,導致出現死鎖的機率比RC大的多!
此時執行陳述句
select * from test where id <3 for update;
在RR隔離級別下,存在間隙鎖,可以鎖住(2,5)這個間隙,防止其他事務插入資料!
而在RC隔離級別下,不存在間隙鎖,其他事務是可以插入資料!
ps:在RC隔離級別下並不是不會出現死鎖,只是出現機率比RR低而已!
緣由二:在RR隔離級別下,條件列未命中索引會鎖表!而在RC隔離級別下,只鎖行
此時執行陳述句
update test set color = 'blue' where color = 'red';
在RC隔離級別下,其先走聚簇索引,進行全部掃描。加鎖如下:

但在實際中,MySQL做了最佳化,在MySQL Server過濾條件,發現不滿足後,會呼叫unlock_row方法,把不滿足條件的記錄放鎖。

然而,在RR隔離級別下,走聚簇索引,進行全部掃描,最後會將整個表鎖上,如下所示

緣由三:在RC隔離級別下,半一致性讀(semi-consistent)特性增加了update操作的併發性!
在5.1.15的時候,innodb引入了一個概念叫做“semi-consistent”,減少了更新同一行記錄時的衝突,減少鎖等待。
所謂半一致性讀就是,一個update陳述句,如果讀到一行已經加鎖的記錄,此時InnoDB傳回記錄最近提交的版本,由MySQL上層判斷此版本是否滿足update的where條件。若滿足(需要更新),則MySQL會重新發起一次讀操作,此時會讀取行的最新版本(並加鎖)!
具體表現如下:
此時有兩個Session,Session1和Session2!
Session1執行
update test set color = 'blue' where color = 'red';
先不Commit事務!
與此同時Ssession2執行
update test set color = 'blue' where color = 'white';
session 2嘗試加鎖的時候,發現行上已經存在鎖,InnoDB會開啟semi-consistent read,傳回最新的committed版本(1,red),(2,white),(5,red),(7,white)。MySQL會重新發起一次讀操作,此時會讀取行的最新版本(並加鎖)!
而在RR隔離級別下,Session2只能等待!
兩個疑問
在RC級別下,不可重覆讀問題需要解決麼?
不用解決,這個問題是可以接受的!畢竟你資料都已經提交了,讀出來本身就沒有太大問題!Oracle的預設隔離級別就是RC,你們改過Oracle的預設隔離級別麼?
在RC級別下,主從複製用什麼binlog格式?
OK,在該隔離級別下,用的binlog為row格式,是基於行的複製!Innodb的創始人也是建議binlog使用該格式!
總結
本文囉裡八嗦了一篇文章只是為了說明一件事,網際網路專案請用:讀已提交(Read Commited)這個隔離級別!
