最近看到一篇叫「2019 年學習資料科學是什麼感受」的文章,深有感觸。作者是 Thomas Nield,美國西南航空公司的商務顧問,著有《Getting Started with SQL (O’Reilly) 》等書,經驗豐富的 IT 大牛。
文章中他以一問一答的形式,給那些想要踏上資料科學之路的人,提了一些中肯的建議。裡面有些觀點很有價值,特節選翻譯成文,這裡分享給你。
作者:Thomas Nield
譯者:蘇克1900
來源:高階農民工(ID:Mocun6)
背景:假設你是一名「表哥」,平常工作主要使用 Excel,資料透視表、製圖表這些。最近瞭解到未來很多工作崗位會被人工智慧會取代,甚至包括你現在的工作。
你決定開始學習資料科學、人工智慧和機器學習,Google 搜尋「如何成為資料科學家」找到了下麵這樣一份學習路線圖,然後你就開始向作者大牛請教。
Q:我是否真的必須掌握這個圖表中的所有內容,才能成為資料科學家?
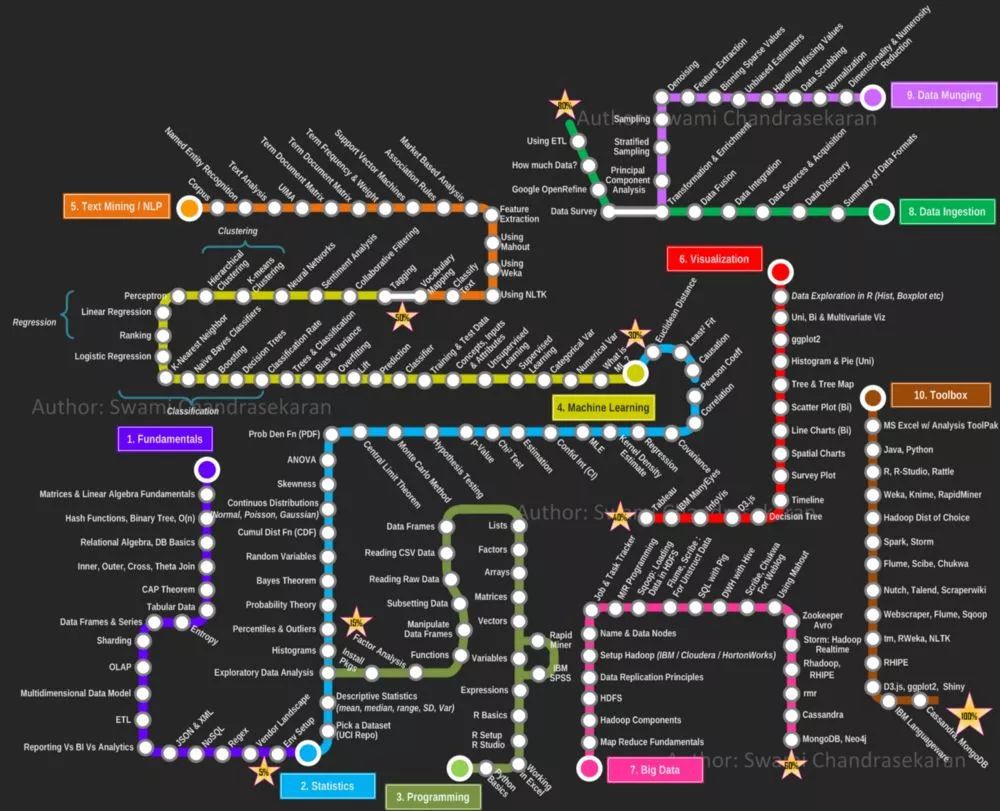
▲成為一名資料科學家的必須技能(截至2013年)
A:簡單說,不需要全部。這是 2013 年的路線圖,有點過時了,裡面連 TensorFlow 都沒有,基本沒有人再參考。完全可以劃掉這個圖中的一些路徑,前幾年「資料科學」劃分地過於分散,採用其他方法會更好。
Q:聽你這樣說就不那麼緊張了,那麼我應該回到學校繼續深造,然後獲得一個資料科學碩士學位嗎? 我看很多資料科學家至少都是碩士。
A:天哪,你為什麼這樣做?不要被「資料科學」這些高大上的術語給唬住了,這些術語主要是用來重新定義一些業務分類。事實上,學校教授的東西基本都是過時的技術,不如選擇 Coursera 或 Khan Academy 這些線上自學網站。
Q:那麼我該如何開始自學呢?LinkedIn上的人說應該先學習 Linux ,Twitter 的人建議先學習 Scala,而不是 Python 或 R
A:不要信那些人的話。
Q:好的,R怎麼樣?不少人喜歡它。
A:R 擅長數學建模,但 Python 能做的更多,比如資料處理和搭建 Web 服務,總之 Python 比 R 的學習投資回報率高。
Q:R 在 Tiobe上的排名仍然很高,而且擁有大量的社群和資源,學它有什麼不好?
如果你只是對數學感興趣,使用 R 完全沒問題,配合 Tidyverse 包更是如虎添翼。但資料科學的應用範圍遠超數學和統計學。所以相信我,Python 在 2019 年更值得學,學它不會讓你後悔。
Q:Python 難學麼?
A:Python 是一種簡單的語言,可以幫你可以自動完成許多工,做一些很酷的事情。不過資料科學不僅僅是指令碼和機器學習,甚至不需要依賴 Python 。
Q:什麼意思?
A:Python 這些只是工具,使用這些工具可以從資料中獲取洞察力,這個過程有時會涉及到機器學習,但大部分時間沒有。簡單地來說,建立圖表也可以算是資料科學,所以你甚至不必學習 Python,使用 Tableau 都行,他們宣稱使用他們的產品就可以「成為資料科學家」。
Q:好吧,但資料科學應該不僅僅是製作出漂亮的視覺化圖表,Excel 中都可以做到,另外學習程式設計應該很有用,告訴我一些 Python 方面的知識吧
A:學習 Python,你需要學習一些庫,比如用於操作 DataFrame 的 Pandas 、製作圖表的 Matplotlib,實際上更好的選擇是 Plotly,它用了 d3.js。
Q:我能懂一些,但什麼是 DataFrame?
A:它是一種有行和列的資料結構,類似 Excel 表,使用它可以實現很酷的轉換、透視和聚合等功能。
Q:那 Python 與 Excel 有什麼不同?
A:大不相同,你可以在 Jupyter Notebook 中完成所有操作,逐步完成每個資料分析階段並視覺化,就像你正在建立一個可以與他人分享的故事。畢竟,溝通和講故事是資料科學的重要組成部分。
Q:這聽起來和 PowerPoint 沒什麼區別啊?
A:當然有區別,Jupyter Notebook 更自動簡潔,可以輕鬆追溯每個分析步驟。有些人不太喜歡它,因為程式碼不是很實用。如果你想做一款軟體產品,更好的方法是使用其他工具模組化封裝程式碼。
Q:那麼資料科學跟軟體工程也有關係麼?
A:也可以這麼說,但不要走偏,學習資料科學最需要的是資料。初學的最佳方式是網路爬蟲,抓取一些網頁,使用 Beautiful Soup 解析它生成大量非結構化文字資料下載到電腦上。
Q:我以為學習資料科學是做表格查詢而不是網頁抓取的工作,所以我剛學完一本 SQL 的書,SQL 不是訪問資料的典型方式嗎?
A:好吧,我們可以使用非結構化文字資料做很多很酷的事情。比如對社交媒體帖子上的情緒進行分類或進行自然語言處理。NoSQL 非常擅長儲存這種型別的資料。
Q:我聽說過 NoSQL 這個詞,跟 SQL 、大資料有什麼關係?
A:大資料是 2016 年的概念,已經有點過時了,現在大多數人不再使用這個術語。NoSQL 是大資料的產物,今天發展成為了像 MongoDB 一樣的平臺。
Q:好的,但為什麼稱它為 NoSQL?
A:NoSQL 代表不僅是 SQL,它支援關係表之外的資料結構,不過 NoSQL 資料庫通常不使用 SQL,有專門的查詢語言,簡單對比一下 MongoDB 和 SQL 查詢語言:

Q:這太可怕了,你意思是每個 NoSQL 平臺都有自己的查詢語言?SQL 有什麼問題?
A:SQL 沒有任何問題,它很有價值。不過這幾年非結構化資料是熱潮,用它來做分析更容易。需強調的是,儘管 SQL 難學,但它是一種非常通用的語言。
Q:好的,我可以這樣理解麼: NoSQL 對資料科學家來說不像 SQL 那麼重要,除非工作中需要它?
A:差不多,除非你想成為一名資料工程師。
Q:資料工程師?
A:資料科學家分為兩個職業。資料工程師為模型提供可用的資料,機器學習和數學建模涉及比較少,這些工作主要由資料科學家來做。如果你想成為一名資料工程師,建議優先考慮學習 Apache Kafka 而不是 NoSQL,Apache Kafka 現在非常熱門。
如果想成為「資料科學家」,可以看看這張資料科學維恩圖。簡單來說,資料工程師是一個多領域交叉的崗位,你需要懂數學/統計學、程式設計以及你專業方面的知識。

Q:好吧,我不知道我現在是想成為資料科學家還是資料工程師。回過頭來,為什麼要抓維基百科頁面呢?
A:抓取下來的頁面資料,可以作為自然語言處理的輸入資料,之後就可以做一些事情,如建立聊天機器人。
Q:我暫時應該不用接觸自然語言處理、聊天機器人、非結構化文字資料這些吧?
A:不用但值得關註,像 Google 和 Facebook 這些大公司,目前在處理大量非結構化資料(如社交媒體帖子和新聞文章)。除了這些科技巨頭,大部分人仍然在使用關係資料庫形式的業務運營資料,使用著不是那麼前沿的技術,比如 SQL。
Q:是的,我猜他們還在做挖掘使用者帖子、電子郵件以及廣告之類的事情。
A:是的,你會發現 Naive Bayes 有趣也很有用。獲取文字正文並預測它所屬的類別。先跳過這塊,你目前的工作是處理大量表格資料,是想做一些預測或統計分析麼?
Q:對的,我們終於回到正題上了,就是解決實際問題,這是神經網路和深度學習的用武之地嗎?
A:不要著急,如果想學這些,建議從基礎開始,比如正態分佈、線性回歸等。
Q:明白,但這些我仍然可以在 Excel 中完成,有什麼區別?
A:你可以在 Excel 中做很多事情,但程式設計可以獲得更大的靈活性。
Q:你說的程式設計是像 VBA 這樣的麼?
A:看來我需要從頭說了。Excel 確實有很好的統計運運算元和不錯的線性回歸模型。但如果你需要對每個類別的專案進行單獨的正態分佈或回歸,那麼使用 Python 要容易得多,而不是建立一長串的公式,比如下麵這樣,這會讓看公式的人無比痛苦。除此之外,Python 還有功能強大的 scikit-learn 庫,可以處理更多的回歸和機器學習模型。

Q:這需要涉及到數學建模領域是吧,我需要學習哪些數學知識?
A:從線性代數開始吧,它是許多資料科學的基礎。你會處理各種矩陣運算、行列式、特徵向量這些概念。不得不說,線性代數很抽象,如果你想要得到線性代數的直觀解釋,3Blue1Brown 是最棒的。
Q:就是作大量的線性代數運算?這聽起來毫無意義和無聊,能舉個例子麼?
A:好吧,機器學習中會用到大量的線性代數知識,比如:線性回歸或構建自己的神經網路時,會使用隨機權重值進行大量矩陣乘法和縮放。
Q:好吧,矩陣與 DataFrame 有什麼關係?感覺很相似。
A:實際上,我需要收回剛才說的話,你可以不用線性代數。
Q:真的嗎?那我還要不要學習線性代數?
A:就目前而言,你可能不需要學習線性代數,直接使用機器學習庫就行,比如 TensorFlow 和 scikit-learn 這些庫,它們會幫助你自動完成線性代數部分的工作。不過你需要對這些庫的工作原理有所瞭解。
Q:說到機器學習,線性回歸真的算是機器學習嗎?
A:是的,線性回歸是機器學習的敲門磚。
Q:真棒,我一直在 Excel 中這樣做,那我是不是也可以自稱「機器學習從業者」?
A:技術上來說是的,不過你需要擴大知識面。機器學習通常有兩個任務:回歸或分類。從技術上講,分類是回歸。決策樹、神經網路、支援向量機、邏輯回歸以及線性回歸,這些演演算法都在做某種形式的曲線擬合,每種演演算法各有優缺點。
Q:所以機器學習只是回歸?它們都有效地擬合了曲線?
A:差不多,像線性回歸這樣的一些模型清晰可解釋,而像神經網路這樣更先進的模型定義是複雜的,並且難以解釋。神經網路實際上只是具有一些非線性函式的多層回歸。當你只有 2-3 個變數時,它可能看起來不那麼令人印象深刻,但是當你有數百或數千個變數時它就開始變得有趣了。
Q:那影象識別也只是回歸?
A:是的,每個影象畫素基本上變成具有數值的輸入變數。你必須警惕維度的詛咒,變數(維度)越多,需要的資料越多,以防變得稀疏。這是機器學習如此不可靠和混亂的眾多原因之一,並且需要大量你沒有的標記資料。
Q:機器學習能解決安排員工、交通工具、數獨所有這些問題嗎?
A:當你遇到這些型別的問題時,有些人會說這不是資料科學或機器學習而是運籌學。
Q:這對我來說似乎是實際問題。運營研究與資料科學無關?
A:實際上,存在相當多的重疊。運籌學已經提供了許多機器學習使用的最佳化演演算法。它還為常見的 AI 問題提供了許多解決方案。
Q:那麼我們用什麼演演算法來解決這些問題呢?
A:絕對不是機器學習演演算法,很少有人知道這一點。幾十年前就有更好的演演算法,樹搜尋、元啟髮式、線性規劃和其他運算研究方法已經使用了很長時間,並且比機器學習演演算法對這些類別的問題做得更好。
Q:那為什麼每個人都在談論機器學習而不是這些演演算法呢?
A:因為很長一段時間裡,這些最佳化演演算法問題已經有了令人滿意的解決方案,但自那時起就一直沒有成為頭條新聞。幾十年前就出現了這些演演算法的 AI 炒作週期。如今,AI 炒作重新點燃了機器學習及其解決的問題型別:影象識別、自然語言處理、影象生成等。
Q:所以使用機器學習來解決排程問題,或者像數獨一樣簡單的事情時,這樣做是錯誤的嗎?
A:差不多,機器學習,深度學習這些今天被炒作的任何東西通常都不能解決離散最佳化問題,至少不是很好,效果非常不理想。
Q:如果機器學習只是回歸,為什麼每個人都對機器人和人工智慧,這麼憂心忡忡,認為會危害我們的工作和社會?我的意思是擬合曲線真的那麼危險嗎?AI 在進行回歸時有多少自我意識?
A:人們已經找到了一些巧妙的回歸應用,例如在給定的轉彎上找到最佳的國際象棋移動(離散最佳化也可以做)或者計算自動駕駛汽車的轉向方向。但是大多都是炒作,回歸只能幹這些事。
Q:好吧,我要散個步慢慢消化下。我目前的 Excel 工作感覺也算「資料科學」,但資料科學家這個名頭有點虛幻。
A:也許你應該關註一下 IBM。
原文:How it feels to learn data science in 2019
https://towardsdatascience.com/how-it-feels-to-learn-data-science-in-2019-6ee688498029
