來自:Python那些事(微訊號:PythonSomething)
喜歡看小說的騷年們都知道,總是有一些小說讓人耳目一新,不管是仙俠還是玄幻,前面更了幾十章就成功圈了一大波粉絲,成功攀上飆升榜,熱門榜等各種榜,扔幾個慄子出來:

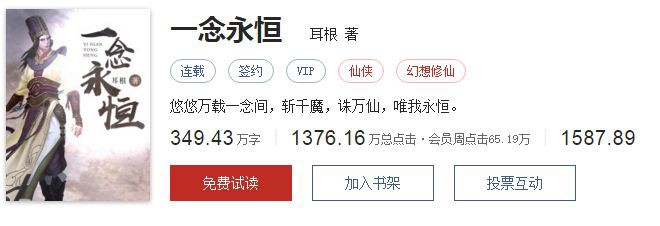
新筆趣閣是廣大書友最值得收藏的網路小說閱讀網,網站收錄了當前……我就不打廣告了(其他滿足下文條件的網站也行,之前已經有做過簡單爬取章節的先例了,但效果不太理想,有很多不需要的成分被留下了,來連結:http://www.bxquge.com/。我們本文就爬取這個網站的上千本小說。重點在和大家一起分享一些爬蟲的思路和一些很常遇到的坑。
本文的行文脈絡:
1、先構造一個單本的小爬蟲練練手;
2、簡要分享一下安裝MongoBD資料庫時的幾個易錯問題;
3、運用Scrapy框架爬取新筆趣閣全站排行榜。
全部程式碼可以在公眾號後臺回覆“0016”獲取。
一、爬取單本小說
爬取該網站相對來講還是很容易的,開啟編輯器(推薦使用PyCharm,功能強大),首先引入模組urllib.request(Python2.x的引入urllib和urllib2即可,待會我把2.x的也寫出來給大家看看),給出網站URL,寫下請求,再新增請求頭(雖然這個網站不封號,但作者建議還是要養成每次都寫請求頭的習慣,萬一那天碰到像豆瓣似的網站,一不留神就把你封了)話不多說,直接上程式碼:
#coding:utf-8
import urllib.request
url = "http://www.bxquge.com/3_3619/10826.html"
essay-headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
request = urllib.request.Request(url,essay-headers=essay-headers)然後再將請求發送出去,定義變數response,用read()方法觀察,註意將符號解碼成utf-8的形式,省的亂碼:
#coding:utf-8
import urllib.request
url = "http://www.bxquge.com/3_3619/10826.html"
essay-headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
request = urllib.request.Request(url,essay-headers=essay-headers)
response = urllib.request.urlopen(request)
html = response.read()
html = html.decode("utf-8")
print(html)列印一下看結果:

看到這麼一大條就對嘍,對比一下網頁原始碼,發現是一致的。

這步觀察很重要,因為這就說明該網站沒有使用AJAX非同步載入,否則就要開始抓包的工作了,這個我們留著分析動態網站時候再說。建議大家在沒有更好的方法時使用。之前記得確實有直接判斷的方法,然而一不小心忘記了,有知道的讀者還請發給我哦。
我們現在得到了網站的response,接下來就是對我們想要獲取的資料進行解析、提取,但等等,考慮到我們要爬取大量小說,不搞一個資料庫儲存真是太失敗了,作者推薦MongoDB資料庫,屬於NOSQL型別資料庫,以檔案儲存為主,這裡用來爬小說真是太適合不過了。但安裝起來需要一定的程式,想要試著做做的騷年可以參考一下下載和安裝教程,參考連結:http://blog.csdn.net/u011262253/article/details/74858211,在安裝好後為方便啟動,可以新增環境變數,但這裡有個坑,你要先開啟mongod(註意是mongodb,別一上來就開啟mongo),然後需要準確新增dbpath路徑,不然開啟很容易就會失敗,上圖上圖:

失敗狀態

成功狀態
新增路徑後成功連線,出現waiting for connections on port 27017,則表示資料庫連線成功,而後就不要關掉這個終端了,只有保持資料庫是連線的,才可執行MongoDB資料庫(不然報錯你都不知道自己是怎麼死的)
好了,連線好資料庫後,我們將資料庫與編輯器進行互動連結,位置很隱秘,在File>>Settings>>Plugins下新增元件Mongo Plugin,沒有就下載一個:


盜個圖
我們在編輯器內編寫程式碼,引入Python專門用來與MongoDB互動的模組pymongo,然後在最上面連結MongoDB資料庫的埠,預設是27017,我們先建立一個叫做reading的資料庫,然後在reading內新建一個叫做sheet_words的資料表,程式碼如下:
#coding:utf-8
import pymongo
import urllib.request
client = pymongo.MongoClient('localhost',27017)
reading = client['reading']
sheet_words = reading['sheet_words']
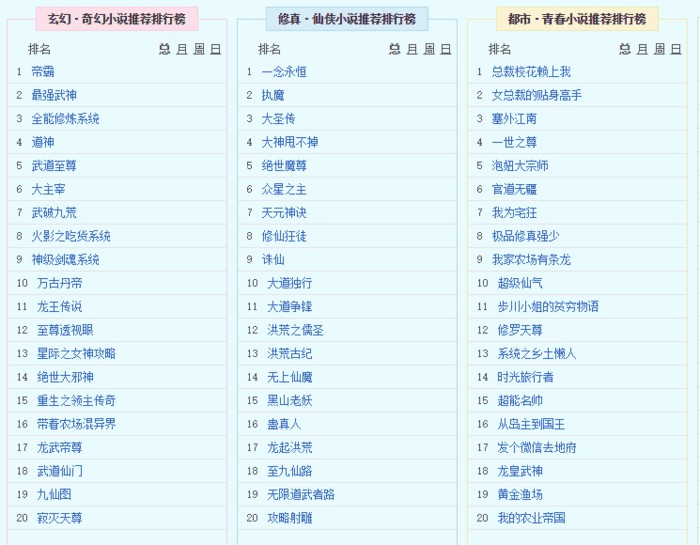
我們先找一個叫做《修羅武神》的小說來練練手,個人來講,我很討厭看小說時來回的翻頁,有時候還跳出廣告,這時候我還得傳回去重新翻頁,作為一名懶得不行的懶人,我想到要是把整部小說放進一個檔案裡再看不就好了麼,但要是一章一章的複製貼上我想還是算了吧,這時候你就知道爬蟲是有多麼便捷了。好,現在我們要做的是把《修羅武神》這部小說完整的爬取下來,併在資料庫中備份。我們回到剛才停留的地方,在得到response後,我們應該選用一種方法來解析網頁,一般的方法有re,xpath,selector(css),建議新手使用xpath而不是re,一是因為re用不好很容易導致錯誤,“當你決定用正則運算式解決問題時,你有了兩個問題。”,相比較xpath才是步驟明確,十分穩妥;二是在Firefox,Chrome等瀏覽器中可以直接複製xpath路徑,大大的減少了我們的工作量,上圖:

如果你決定使用xpath之後,我們需要從lxml中引入etree模組,然後就可以用etree中的HTML()方法來解析網頁了,從網頁>檢察元素(F12)中複製下來我們所需資料的路徑,我選擇的是小說每章的標題和內容,上圖,上圖:
路徑//div[@class=”readAreaBox content”]/h1/text()

路徑/html/body/div[4]/div[2]/div[2]/div[1]/div[2]/text()
註意註意,又來一個坑,當你複製xpath時得到的是這個東東:
//div[@class=”readAreaBox content”]/h1
和這個東東;
/html/body/div[4]/div[2]/div[2]/div[1]/div[2]
但你需要的是這個路徑裡的文字text,故我們需要另外新增具體文字:/text(),然後就像上面那樣啦。上程式碼,查資料:
url = 'http://www.17k.com/list/493239.html'
response = urllib.request.urlopen(url)
html = response.read().decode("utf-8")
tree = etree.HTML(html)
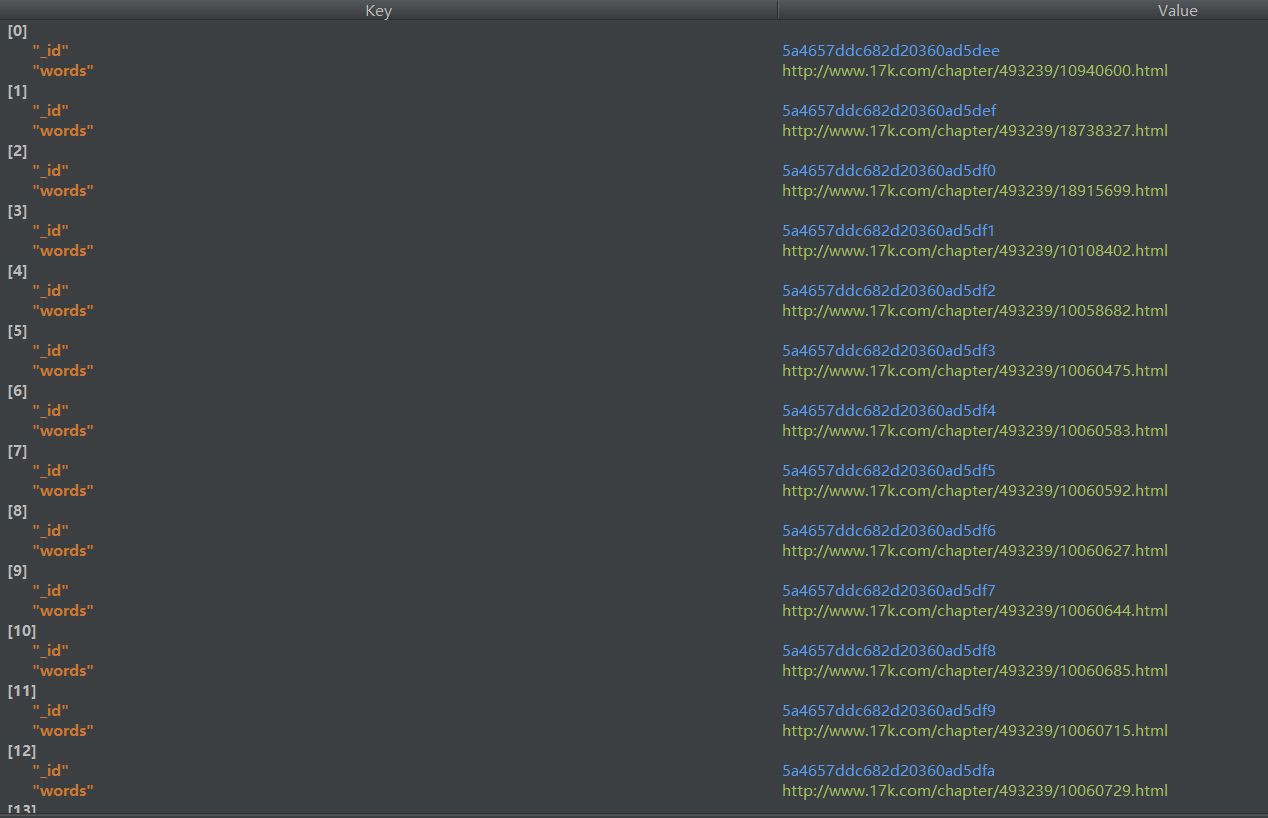
dom = tree.xpath('//a[@target="_blank"][@title]/@href')
for i in dom:
data = {
'words':"http://www.17k.com" + i
}
sheet_words.insert_one(data)
# $lt/$lte/$gt/$gte/$ne,依次等價於/>=/!=。(l表示less g表示greater e表示equal n表示not )
try:
os.mkdir("修羅武神小說")
except FileExistsError:
pass
os.chdir("修羅武神小說")
for item in sheet_words.find():
filename = "修羅武神"
with open( filename,"a+") as f:
contents = urllib.request.urlopen(item["words"])
responses = contents.read().decode("utf-8")
trees = etree.HTML(responses)
title = trees.xpath('//div[@class="readAreaBox content"]/h1/text()')
word = trees.xpath("/html/body/div[4]/div[2]/div[2]/div[1]/div[2]/text()")
a = ''.join(title)
b = ''.join(word)
f.write(a)
f.write(b)
#print(''.join(title))小說有點大,一共是三千五百章,等個大約4-7分鐘吧,開啟檔案夾《修羅武神小說》,就可以看到我們下載好的無需翻頁的一整部小說,資料庫內頁備份好了每章的連結,它自動從零開始排的,就是說你要看第30章就得開啟序號為29的連結,這個調一下下載時的順序就好了,作者很懶,想要嘗試下的讀者可以自行更改。

小說文字
資料庫連線
看看,感覺還不錯吧,好的小例子講完了,接下來我們準備進入正題。
我們要像上面的例子那樣爬取整個網站,當然這裡就不再建議使用普通的編輯器來來執行了,聰明的讀者已經發現,一部小說爬了4分鐘,那麼上千本不說,單單是一組排行榜裡的100本就夠爬好一會了,這就顯示出Scripy框架的作用,用專門的Scripy框架寫工程類爬蟲絕對快速省力,是居家寫蟲的必備良藥哇。
二、爬取小說榜所有小說
首先安裝Scrapy的所有元件,建議除pywin32以外都用pip安裝,不會的話度娘吧,很簡單的,pywin32需要下載與你所用Python版本相同的安裝檔案。
來連線:https://sourceforge.net/projects/pywin32/

Scrapy外掛安裝成功
然後還是老規矩,不想每次終端執行都一點一點找路徑的話,就將根目錄新增到環境變數,然後開啟終端,我們測試一下是否安裝成功:

Scrapy安裝成功
好,安裝完畢後,開啟終端,新建一個Scrapy工程,這裡你可以根據索引,選擇使用Scrapy的各種功能,這裡不一一詳解了,D盤內已經出現了我們建立好的Scrapy工程檔案夾:

開啟檔案夾,我們會看到Scrapy框架已經自動在reading檔案夾中放置了我們所需的一切原材料:

開啟內部reading檔案夾,就可以在spiders檔案夾中新增爬蟲py程式碼檔案了:
我們這裡定向爬小說排行榜,除了我們寫的spider檔案,還要在items.py中定義我們要爬取的內容集,有點像詞典一樣,名字可以隨便取,但已有的繼承類scrapy.Item可不能改,這是Scrapy內部自定義的類,改了它可找不到,spider就用我們上面抓取單本再加一個for迴圈就OK了,十分簡單,一言不合就上圖:
# -*- coding: utf-8 -*-
import scrapy
import urllib2
from lxml import etree
import os
from reading.items import ReadingSpiderItem
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class ReadingspiderSpider(scrapy.Spider):
name = 'bigreadingSpider'#爬蟲名
allowed_domains = ['http://www.xinbiquge.com/']#總域
start_urls = ['http://www.bxquge.com/paihangbang/']#起始頁
def parse(self, response):
sel = scrapy.selector.Selector(response)#解析域
for i in range(2,10):
path = '//*[@id="main"]/table[' +str(i)+ ']/tbody/tr[1]/td[2]/span'#排行榜路徑
sites = sel.xpath(path)
items = []
for site in sites:#按9個排行榜爬取
item = ReadingSpiderItem()
path_list_name = '//*[@id="main"]/table[' +str(i)+ ']/tbody/tr[1]/td[2]/span/text()'
item['list_name'] = site.xpath(path_list_name).extract()#排行榜名稱
try:
os.mkdir(item['list_name'][0])
except IOError:
pass
os.chdir(item['list_name'][0])
for li in range(1,21):
title = '//*[@id="tb' + str(i-1) + '-1"]/ul/li['+str(li)+']/a/text()'
item['name'] = site.xpath(title).extract()#書名
url = 'http://www.bxquge.com/'
path_link = '//*[@id="tb'+ str(i-1) +'-1"]/ul/li[' + str(li) + ']/a/@href'#書目連結
item['link'] = site.xpath(path_link).extract()
full_url = url + item['link'][0]
essay-headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
#request = urllib2.Request(''.join(item['link']),essay-headers=essay-headers)
request = urllib2.Request(full_url,essay-headers=essay-headers)
try:
os.mkdir(item['name'][0])
except IOError:
pass
os.chdir(item['name'][0])
response = urllib2.urlopen(request).read().decode('utf-8')
tree = etree.HTML(response)
for j in range(1,11):
path_title = '//*[@id="list"]/dl/dd['+ str(j) +']/a/text()'
item['title'] = tree.xpath(path_title)#章節名
path_words_page = '//*[@id="list"]/dl/dd['+ str(j) +']/a/@href'
word_page = tree.xpath(path_words_page)
try:
url_words = full_url + word_page[0]
request_words = urllib2.Request(url_words,essay-headers=essay-headers)
response_words = urllib2.urlopen(request_words).read().decode('utf-8')
tree_words = etree.HTML(response_words)
path_words = '//*[@id="content"]/text()'
item['words'] = tree_words.xpath(path_words)#前20章內容
except urllib2.HTTPError:
pass
items.append(item)
try:
filename = r''.join(item['title'][0]) + '.json'
with open(filename,"a+") as f:
a = ''.join(item['title'])
b = ''.join(item['words'])
f.write(a)
f.write(b)
except IOError:
pass
path_now = os.getcwd()
path_last = os.path.dirname(path_now)
os.chdir(path_last)
path_now = os.getcwd()
path_last = os.path.dirname(path_now)
os.chdir(path_last)
爬取的小說排行榜

每個排行榜上大約20本小說

每部小說的爬取情況(用的是.json格式)

小說顯示內容
至此,我們所需的資料就都爬取完了,它們都按照相應的檔案夾目錄放置好在相應位置,適合條理性的觀看。全部程式碼可以在公眾號後臺回覆“0016”獲取。對於本文內容若有更好的提議、手法,望各位讀者大大們留言。
(完)
●本文編號319,以後想閱讀這篇文章直接輸入319即可
●輸入m獲取到文章目錄

大資料與人工智慧
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
