作者丨張浩宇
學校丨國防科技大學計算機學院
研究方向丨自然語言生成、知識圖譜問答
本文解讀的是一篇由國防科技大學與微軟亞洲研究院共同完成的工作,文中提出一種基於預訓練模型的自然語言生成方法。


摘要
在本文中,我們基於編碼器-解碼器框架提出了一種新穎的基於預訓練的方法,該方法可以由給定輸入序列以兩階段的方式生成輸出序列。
對於編碼器,我們使用 BERT 將輸入序列編碼為背景關係語意表示。對於解碼器,在我們的模型中有兩個階段,在第一階段,我們使用基於 Transformer 的解碼器來生成輸出序列的草稿;在第二階段,我們分別 mask 草稿中的每個單詞並將其提供給 BERT,然後基於 BERT 生成的輸入序列和草稿的背景關係語意表示,由一個基於 Transformer 的解碼器來預測精化每個被 mask 位置的單詞。
據我們所瞭解,我們的方法首次將 BERT 應用於文字生成任務。作為在這方面的首次嘗試,我們在文字摘要任務上驗證我們方法的效果。試驗結果表明,我們的模型在 CNN/Daily Mail 和 New York Times 資料集上的效能超過了當前最好的方法。
研究動機
文字摘要是一種從給定文字中生成精煉資訊的任務,近年來很多生成式摘要方法在基於神經網路的序列到序列模型上進行了改進。但是這些方法有一些不足:首先在解碼器端,這些方法大都是從左向右的解碼,因此在解碼每個單詞的時候只能看到上文,而無法看到下文;其次由於背景關係不完整,這些方法無法在解碼器端很好的利用預訓練的背景關係語言模型的能力。
同時,預訓練的背景關係語言模型(如 BERT)在很多自然語言處理任務上取得了很好的效果。本文工作希望探討如何更好的利用此類預訓練語言模型提高文字生成方法的效果。
研究方法

上圖是作者提出的方法的結構圖,它包含了一個編碼器和兩個解碼器。方法包含以下部分:草稿生成過程以及精煉過程。
草稿生成過程中,編碼器由預訓練的 BERT 從輸入檔案中提取背景關係表示,而後利用一個帶有 Copy 機制的 N 層 Transformer 解碼器,以從左向右的方式解碼生成草稿。Copy 利用最後一層解碼器的輸出![]() 和編碼器的輸出
和編碼器的輸出![]() 計算註意力權重 α 和 Copy 機率
計算註意力權重 α 和 Copy 機率![]() ,並和生成機率進行加權求和得到最終預測的機率:
,並和生成機率進行加權求和得到最終預測的機率:
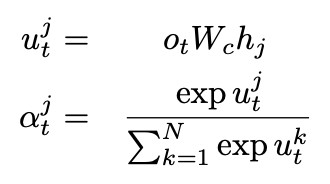

這一階段解碼器端並沒有使用 BERT 產生背景關係表示。該過程的損失函式定義為:
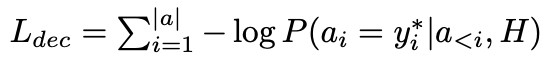
摘要精煉過程的主要目的是利用 BERT 的背景關係表示提高解碼器的學習能力,因此該過程使用和草稿生成階段相同的檔案編碼。在解碼器端,我們提出了一個單次級別的精煉解碼器,該解碼器接受草稿作為輸入,輸出精煉後的摘要。
如模型圖中所示,首先依次將摘要草稿中的每個單詞掩蓋住,而後將掩蓋後的序列輸入 BERT 並得到序列的背景關係表示。而後這個背景關係表示被輸入 N 層 Transformer 的解碼器並與原始檔表示進行互動預測摘要的每個單詞。
儘管該解碼器也是自左向右的解碼順序,但是在每個時刻解碼器都能夠獲得完整的背景關係。從 BERT 的角度來看,輸入的是完整序列而不僅僅是上文,輸入的分佈與 BERT 的預訓練過程更加一致,這能夠盡可能地讓 BERT 輸入更好的背景關係語意表示,從而幫助解碼器生成更佳的摘要。
直觀上看,在我們第二次解碼時,每個時刻解碼器能夠利用到的資訊更多,降低了學習的難度。
在實驗中,基於實驗結果我們共享了兩個解碼器的引數,精煉過程的損失函式定義如下。

最後,由於最大化極大似然估計的標的對摘要等文字生成任務來說太過嚴格,可能會過度擬合,因此借鑒之前工作,我們將 ROUGE-L 作為另一個最佳化標的並利用強化學習對該標的進行最佳化,最終的學習標的是 MLE 和 ROUGE-L 的混合。

實驗結果
為了驗證模型的效果,作者在 CNN/DailyMail 和 NYT-50 兩個摘要資料集上進行了實驗,並與當前一些主要方法進行了對比。其中 NYT-50 資料集是 NYT 資料集中刪選所有摘要長度大於 50 的樣本得到。在 CNN/DailyMail 資料集上作者進行了消融實驗,以此來驗證每個模組的作用。


同時,為了驗證摘要長度對模型效能的影響,作者對不同長度樣本下模型效能相對於抽取式和生成式基準模型的平均提高進行了計算並分析。
同生成式模型相比,相比於長度更短的樣本,在摘要長度為 40-80 區間內的樣本中作者提出的模型達到了更高的效能提升;而同抽取式基準模型相比,在長度超過 80 的樣本上,效能提升不大,這可能是由於實驗設定截斷的原因,也可能是因為這個區間訓練樣本太少,因此抽取式模型效能不會落後太多。
下麵是兩個模型預測(Pred.)和正確摘要(Ref.)的例子。

總結
本文主要的創新點在於設計了一個兩階段解碼器的模型,從而更好地在解碼器端利用預訓練語言模型的能力輔助文字生成。與目前 SOTA 的方法相比,在兩個摘要資料集上都有一定的效能提升。
