來自:talkwithtrend(微訊號:talkwithtrend)
社群有很多兄弟分享慘痛宕機案例,提醒大家需警惕,以下介紹幾起,滿滿都是血的教訓……
(以下案例來自社群多位會員分享,主要由社群專家孫偉光、崔增順編輯整理)
01
AIX 下 NTP 設定不當導致的多個叢集宕機
事情發生在一段時間之前,接到朋友電話,使用者有三套 oracle rac 叢集執行在 aix 小機上,本地兩套,同城機房兩套,做完裝置搬遷後的一天晚上,其中本地和同城的兩套 rac 突然就整個重啟了,而且發生在同一時間點。
網路、小機、儲存、資料庫分屬不同的維保廠商,這就開始了扯皮。各家就開始從自己的方向自證無過錯。我去之前內心也比較傾向於 oracle 的網路心跳出了問題,crs 搶 vote disk 的時候觸發了重啟。但由於是小機方的代表,僅從 aix 層面做了排查,未發現明顯原因。對各主機宕機的時間做了一個梳理,去和 oracle 的事件日誌去比對。暫時沒查到什麼東西。
宕機產生的 dump 發到了 IBM 原廠,IBM 後來出了個報告,根據 dump 內容定位觸發宕機的行程為 cssd。oracle dba 重點看了那個行程的日誌,發現宕機時間前後,時間突然變更,提前了40多秒。dba 確認,時間變更過多,cssd 行程會導致系統重啟,懷疑和時間同步有關。
經檢查,3套 aix 的 rac 叢集使用了同一個 ntp server,但有一套沒發生問題。對比檢查差異,發現沒問題的那套主機叢集使用 xntpd 方式配置了時間同步。出問題的主機則直接使用了 ntpdate 命令做時間更新,並寫入了 crontab 定期執行。檢查 /var/adm/cron/log 日誌,發現定時任務的執行時間和 cssd 故障時間一致。檢查時間伺服器,發現搬遷後,時間伺服器的時間產生了較大偏差,xntpd 方式的時間同步在時間偏差大時不會去強制同步,ntpdate 命令的方式沒有這個限制,會直接進行同步。最終導致了 cssd 行程檢測到過大時間偏差後觸發了宕機。
經驗分享:配置時間同步時,建議使用 xntpd 服務的方式,不用直接在定時任務裡寫 ntpdate,因為 ntpdate 比較粗暴,發生故障時較大的時間偏差會導致應用出現問題,觸發無法預知的後果。
由社群會員王巧雷分享
02
採用愛數備份一體機導致宕機
去年我們剛剛入手了一臺愛數備份一體機,在測試階段遇到了一個小例子和大家分享一下:
當時測試各種資料的備份和功能,就在一臺系統上安裝了愛數備份的代理客戶端,客戶端安裝選項中有一項安裝 CDP 驅動。 當時並沒有留意,後來升級客戶端版本,另外做了一些其他測試,就把代理客戶端解除安裝了,但是並沒有先去解除安裝 CDP 驅動,重啟後系統就直接起不來了,和愛數的技術支援溝通後瞭解,需要先解除安裝CDP驅動,再解除安裝客戶端,否則 CDP 驅動存在的時候,就會導致系統啟動失敗。
由社群會員“pysx0503”分享
03
經典雙機雙儲存,某晚主儲存異常故障,業務立刻中斷
使用者經典的雙機雙儲存高可用應用方案。IBM 2*P570 PowerHA6.1 兩臺中端儲存透過 lvm mirror 實現的資料映象,上面跑著使用者信貸系統,報表系統,儲存壓力較為繁忙。使用者每年都會完成一次 HA 切換演練保證業務高可用。某晚一次儲存電源故障,電源還沒來得急更換,另外一個電源也壞了。這樣主儲存宕機了。恰巧這個時候業務也立刻停止了,使用者電話裡說剛做完的 Powerha 的演練,很順利。可今天發生的這事卻百思不得其解。
後來經過大量的日誌和與使用者交流得知,使用者之前的一個操作給這次的業務中斷埋下了一個大大的”地雷”。
究竟使用者自己做的什麼操作導致的此次事件呢?
使用者業務系統有一個檔案系統儲存空間不夠了,需要擴容,但是目前共享 vg 裡的空間無法滿了,需要重新加新的磁碟到 vg 裡,儲存管理員分配新的磁碟給兩臺主機,然後使用者透過 Powerha cspoc 去加盤,擴容 FS。就是這麼一個操作導致的問題發生。
經驗分享:lvm mirror 雙儲存的情況下,我們擴 fs 需要註意先擴 LV,再擴 fs,這樣能保證資料正確分佈在2個儲存上,如果在使用者這種場景新加磁碟後直接擴fs,那就會造成資料複製是2份,但是不能準確地保證分佈在兩個儲存上,有可能儲存A分佈90% 儲存B分佈110%。這樣一臺儲存故障,就會直接導致資料的不完整。
由社群會員孫偉光分享
04
HACMP NODE ID 一致導致故障宕機
故障描述:
前些天在論壇閑逛,發現一兄弟的帖子“Power HA 其中一臺異常宕機”(釋出者:yangming27),點進去一看,發現故障描述和報錯資訊和我之前遇到的完全一樣,基於提醒和血的教訓,特將該問題編寫成案例,希望大家引以為戒!
我們生產環境有 PowerVM 虛擬化後的 AIX 虛擬機器2臺,災備環境有 PowerVM 虛擬化後 AIX 虛擬機器1臺,三臺虛擬機器透過 PowerHA XD(基於 SVC PPRC 遠端複製)搭建了跨中心高可用環境,作業系統版本為7.1.2.3,HA 版本為7.1.2.6,搭建該環境之前,生產環境的兩臺 AIX 是透過 HAMCP 搭建了本地的高可用環境,為了災備建設需求,將本地的1臺主機透過 alt_disk_copy 的方式複製了一份 rootvg 至外接儲存,並將該外接儲存透過 SVC PPRC 複製至災備儲存捲當中,災備的虛擬機器再掛載該捲,並透過該捲啟動作業系統。這樣三臺 AIX 虛擬機器再重新搭建了PowerHA XD,實現跨中心 HA 熱備。
透過這種方式,我們搭建了三套系統,均透過了 HA 切換測試,但是運行了一段時間後,其中一套系統的主機故障宕機(關機),資源組切向了備機,發現問題後,第一時間檢視 errpt 日誌,如下(這裡借用 yangming27帖子中的日誌截圖)

故障分析:
由於作業系統沒有開 always allow dump,所以並沒有產生 dump 檔案,當時分析了很久日誌,很是疑惑不解,最終只能提交給 IBM 後臺進行分析,後臺也是許多天都沒有答覆。過了一個星期後,第二套系統也出現了一樣的現象,一樣的故障,造成主備 HA 切換,我開始懷疑是 HACMP XD 實施問題,立馬翻閱了一下實施檔案,發現在做 alt_disk_copy 時只用了 alt_disk_copy -d hdiskx,後面並沒有用-O -B -C引數,這些引數主要是用來複制rootvg時,刪除原作業系統的配置資訊和 ODM 庫的一些資訊,這樣一來可能就會造成生產主機和災備備機的作業系統某些資訊一致。基於這種懷疑,我復看了 errpt 報錯記錄,宕機的主要原因應該是以下幾個點:
IBM.StorageRM daemon has been stopped
Group Services daemon stopped
Group Services detected a failure
QUORUM LOST,VOLUME GROUP GROUP CLOSING
猜想是否是 QUORUM 中保留的兩個主備節點資訊一致,導致 QUORUM 關閉。
接著在生產主機執行命令
odmget -q “attribute=’node_uuid'” CuAt
輸出:CuAt: name = “cluster0” attribute = “node_uuid” value = “673018b0-7a70-11e5-91fa-f9fe9b9bc3c6” type = “R” generic = “DU” rep = “s” nls_index = 3
在災備主機執行命令 odmget -q “attribute=’node_uuid'” CuAt
輸出:CuAt: name = “cluster0” attribute = “node_uuid” value = “67301842-7a70-11e5-91fa-f9fe9b9bc3c6” type = “R” generic = “DU” rep = “s” nls_index = 3
生產主機執行命令
/usr/sbin/rsct/bin/lsnodeid
災備主機執行命令
/usr/sbin/rsct/bin/lsnodeid
以上發現兩個節點的 RSCT NODE ID 完全一致
這就是造成資訊衝突的點,造成了主服務停止和 QUORUM 仲裁關閉的元兇。
故障解決:
1.將 PowerHA XD 的 HA 服務全部關閉,禁止 HA 組服務的保護,並執行命令
/usr/sbin/rsct/bin/hags_stopdms -s cthags
/usr/sbin/rsct/bin/hags_disable_client_kill -s cthags
2.停止 HA 的 ConfigRM 服務和 cthags 服務
stopsrc -s IBM.ConfigRM stopsrc -s cthags
3.重新配置 RSCT 節點
/usr/sbin/rsct/install/bin/recfgct
4.重啟所有3臺作業系統
shutdown -Fr
5.啟動 HACMP 服務和資源組,並檢查 RSCT NODE ID
經驗分享:透過以上方法,徹底解決了三套系統的 HACMP 主機宕機問題,建議以後做類似 alt_disk_copy 時,一定要帶上-B -C -O引數,保持新作業系統的潔凈,以防碰到類似的莫名其妙的問題。
由社群會員“jxnxsdengyu”分享
05
Power 570/595 宕機
事情起因:
由於機器宕機是在週六,是客戶的核心應用,但週六客戶沒有人上班,當週一上班的時候發現所有的辦公,郵件系統等一半的核心應用不能訪問,經過現場機房管理人員的臨時排查,發現小機 Power595 後面所有的 I/O 櫃掉電,Power570 黃燈亮起,綠燈慢閃。
工程師到達現場,按照與客戶溝通好結果,我們開始幹活,大概折騰了6個小時,Power595 還是沒有啟動起來,但 power570 可以正常訪問了。為了趕緊讓客戶生產資料,我們臨時決定,用 power570 臨時做個 lpar 讓儲存連結過來,先拉起應用,再又折騰了3個多小時之後,所有應用都可以正常訪問。我們繼續排查Power595,我們更換了 CEC DCA 記憶體板,CPU 都沒有解決問題,最後更換了 pubook 問題解決了,花費時間3天。
問題原因:
電工改造線路,造成了機房斷電,UPS 臨時接管,由於電池放了太久,機器功率太大,造成低電壓執行,造成裝置不能正常工作,更為關鍵的是電工出現問題之後沒有及時檢查電路,根據師傅的陳述大概過了1分鐘又把交流電送出去,這個電壓衝擊是很厲害的,經排查此電工無證施工,客戶已經提起訴訟。
由社群會員“shizhe1030”分享
06
ERP 備份導致的一起宕機案例
現象回顧:
某日凌晨,其中一臺 ERP 資料庫主機宕機。AIX.5.3 HACMP RAC 資料庫環境。
故障分析:
宕機時間點是在備份期間。透過分析資料庫日誌、系統日誌、發現導致資料庫停庫的主要原因是由於 HACMP 的一個守護行程 haemd 發生自動重啟,由於 oracle 資料庫和 haemd 行程之間有關聯,因此資料庫在發現 haemd 重新啟動後也自動停止。
經 IBM 工程師及實驗室分析,Haemd 自動重新啟動的原因是由於在一定期間內(引數為2分鐘)沒有給 HACMP 系統響應,其原因之一是由於系統過於繁忙,沒有響應 Haemd。
隨後分析結果發現在備份期間,從儲存看系統不是很繁忙;但 ERP 資料庫伺服器主機效能異常:有時會出現階段性的不響應現象,同時系統 I/O 高。停止備份後,這種現象消失。
經 IBM 實驗室協助,初步經過分析:
1)AIX 系統記憶體分為計算類和非計算類記憶體。非計算類記憶體主要用於檔案操作CACHE,以便提高檔案再次讀寫的效能。目前 ERP 生產資料庫佔用了近20G記憶體作為檔案系統 CACHE。
2)當檔案系統 CACHE 有空間時,寫檔案操作將不會產生阻塞,當檔案系統 CACHE 無空間時,系統將會根據內部策略,擠出部分 CACHE。當無法找到空閑的 CACHE 時,會等待系統調整齣空閑的 CACHE。當出現大量等待時,系統可能出現無響應的狀態。
解決方案:
考慮到將來資料量的增加,如果無法解決較大 I/O 對系統的影響過大的問題,這個隱患將一直存在。
調整該備份檔案系統的屬性,在該檔案系統的 I/O 請求到達一定值的情況下,阻塞對該檔案系統的讀寫 I/O,從而保證預留足夠的資源給系統。具體引數為 Maxpout、Minpout。
經驗分享:Maxpout、Minpout 引數的選擇,是和具體環境相關的,沒有一個統一的建議值。若該引數設定不合理,可能會影響到檔案系統的讀寫操作。而合適的引數需要經過設定、觀察來確定。
由社群會員孫偉光分享
07
weblogic 宕機問題排查
問題現象:
系統持續執行2-3天,中介軟體出現宕機
系統執行期間只要訪問 weblogic 控制檯,操作幾次後中介軟體宕機
報錯日誌:

分析:
透過報錯日誌分析,為記憶體上限溢位,且為非堆記憶體上限溢位,這種情況一般需要調整:PermSize 的大小。
解決過程:
調整 weblogic 配置引數:setDomainEnv.sh 設定 setDomainEnv.sh 為512。
調整後重啟系統,發現問題依舊,並沒有解決宕機問題。
確認修改引數是否生效:生成 javacore 來分析(kill -3 行程ID)截圖如下:

我們發現引數並沒有生效。繼續分析引數為什麼沒有生效。
Weblogic 中的 commEnv.sh ,發現 JAVA_VENDOR 為 N/A

而 setDomainEnv.sh 中 PermSize 的設定為:

此處的引數並沒有 設定我們需要的 Open JDK的 JAVA_VENDOR 的 N/A 的賦值,所以非堆記憶體的設定並未生效。
註意:正常 open jdk 的 JAVA_VENDOR 為 Oracle 的,但是配置檔案卻為:N/A,可能是 weblogic 的相容性問題,或者人為改動導致,找到原因了,這個問題就沒有細究。
解決方案:
修改 commEnv.sh , JAVA_VENDOR 為 Oracle、HP、IBM、Apple 中的任何一個
在 startWeblogic 中,單獨定義:MEM_ARGS=”-Xms2048m -Xmx2048m -XX:PermSize=1024m”
驗證方案:
採取第二種方案:
1)在原始預設環境,進行12個小時的迴圈操作,並持續訪問 weblogic 控制檯。
2)在修改後的環境,持續訪問 weblogic 控制檯,生成 javacore 檔案看引數是否生效。併進行50人高強度的併發測試20個小時,看是否會重現宕機問題。
在方案的第一步,系統執行2小時,訪問控制檯,中介軟體宕機,系統無法訪問。
在方案的第二步,系統在50人高強度的併發測試20小時的情況下,響應正常。頻繁訪問控制檯並未發現任何異常。透過生成 javacore 發現非堆記憶體正常生效。

由社群會員“gu y 011”分享
08
P550/P570 宕機案例
某週末,客戶致電,說核心業務無法訪問。工程師到達現場,發現客戶環境(P550/P570–HACMP)P550 兩臺小機均關機。發現客戶現場有部分伺服器也已處於關機掉電狀態。此時客戶才發現,市電週五晚上斷電過,但是客戶機房配備有2臺 UPS,機房裝置一半一半分別接到2臺 UPS上。排查發現其中一臺 UPS無法供電。而兩臺小機均有一路電源接到該 UPS,導致市電斷電後,直接宕機。
後將小機通電開機,發現P550無法開機,CPU VRM 穩壓模組報錯,由於客戶業務較為重要,將 P570 已經拉起來,準備將 HA 叢集在 IBM P570 單節點執行。卻發現 HA 無法將 Oracle 資料庫拉起。由於時間緊迫,手動在 P570 網絡卡上新增 IP 別名後,手動掛載 VG,恢復業務。
後續,將 P550 穩壓模組進行更換後,發現仍然無法開機,又出現新的報錯:11002630,再次更換 CPU 板後,P550 小機正常開機。安排停機視窗進行排查恢復。在處理過程中,叢集出現意外,在 HA 拉起來後,經業務測試,發現/orafile丟失一部分資料,此時備份資料最新的為前一天晚上23點,單天的資料未做備份,只能採取資料恢復,最後成功將資料恢復回來。重新配置 HA,模擬故障切換,測試業務,驗證資料完整性,業務恢復正常!
由社群會員“ACDante”分享
09
AIX6100-06-06系統 bug 引起 down 機
某機器作業系統版本6100-06-06,系統 down 機,生成 dump 檔案。
Problem:
System crash with following stack
CRASH INFORMATION:
CPU 3 CSA F00000002FF47600 at time of crash, error code
for
LEDs: 30000000
pvthread+02BD00 STACK:
[00009500].simple_lock+000000 ()
[00450E24]netinfo_unixdomnlist+000824 (??, ??, ??, ??,
??, ??)
[0451214C]netinfo+00006C (??, ??, ??, ??, ??, ??)
[004504DC]netinfo+0000FC (??, ??, ??, ??)
[00003850]ovlya_addr_sc_flih_main+000130 ()
[kdb_get_virtual_memory] no real storage @
FFFFFFFFFFFEF20
[100002640]0000000100002640 ()
[kdb_read_mem] no real storage @ FFFFFFFFFFF5E30
bug原因:
File lock is taken before checking whether the file type is socket.
該故障因 netstat -f unix 命令引起系統 crash, 是 IBM bug 引起
建議單獨提升 bos.mp64包補丁包或者整體升級到6100-06-12-1339(SP12)
官網解釋:
IV09793: SYSTEM CRASH IN NETINFO_UNIXDOMNLIST APPLIES TO AIX 6100-06
http://www-01.ibm.com/support/docview.wss?uid=isg1IV09793
File lock is taken before checking whether the file type is socket.
由社群會員“qb306”分享
10
P570 宕機案例
IBM 570 意外宕機,處理過程如下:
1、首先檢視 asmi 日誌,電源和風扇故障,更換了2個電源和1個風扇後,可以啟動到 standby 樣式。但是非常多的 firmware 報錯。
2、升級微碼到 sf240-417後,微碼報錯消失。
3、啟用分割槽失敗,hmc 終端會出現幾秒的”ide inited failed“提示,然後消失。接著卡死,報找不到硬碟。
4、觀察外觀,發現後端的光纖卡燈特別弱,有時會不亮。
5、查了下570的紅皮書結構圖,發現 ide controller(紅線圈住部分)同時處理 pci 裝置和硬碟背板裝置過來的 io,根據現有故障現象,判定 ide controller 有故障。

6、透過 ibm system information center,定位到 ide controller 的 location code 為p1-15,不是一個可替換的 FRU,必須隨同 IO backbone(就是主機板)一起更換。
7、更換 io backbone 後,系統正常啟動,進入系統微調後,一切正常。
由社群會員王巧雷分享
11
某企業 HACMP 軟體,在網路交換機變更時引起 down 機
某企業 HA cluster log, IP switch down 時引起雙節點 halt,系統版本7100-03-03,HA 版本6.1sp13
Error description
In HACMP 6 with rsct.core.utils 3.1.4.9 or higher, if all
IP networks are lost and at least one non-IP network is
functioning, the Group Services subsystem will core dump when
trying to send packets to be routed through Topology Services
(across the non-IP connection). This will cause a node halt.
Customers with PowerHA 7, or HACMP 6 customers with no non-IP
networks (such as rs232 or disk) are not in danger. Also this
will not happen if only one node is still running, since there
will be no other cluster members to send messages to.
日誌如下:
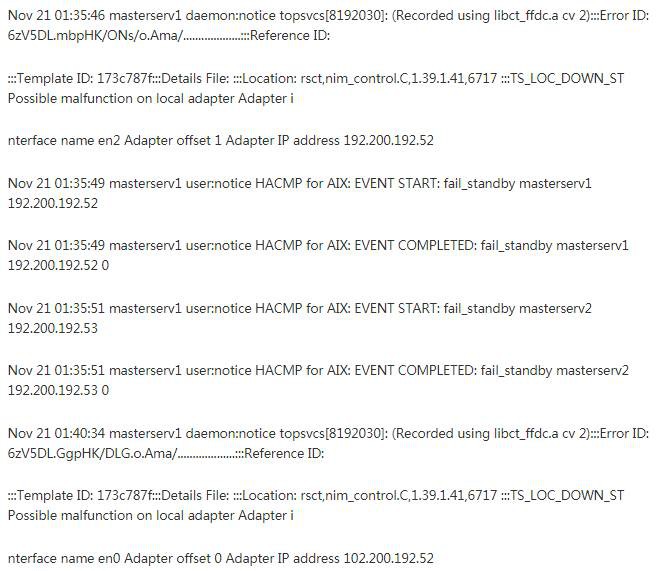

原因是補丁 IV55293: HAGSD CORE DUMP WHEN IP NETWORKS LOST, 需要升級 rsct 檔案集。
官網解釋:
http://www-01.ibm.com/support/docview.wss?uid=isg1IV55293
由社群會員“qb306”分享
12
巡檢不仔細 Power595 宕機
事件起因,本來巡檢已經發現其中的一個 I/O 櫃電源故障,線上更換走腳步的時候,腳步執行到一半引起該 I/O 櫃突然掉電,重啟了該 I/O 櫃。
原因:一線工程師巡檢時候不夠仔細,因為該同一個 I/O 其實壞了2個電源,只不過另外一個沒有報出來具體的位置,但已經報出來該 I/O 的部件號,但也說明瞭 IBM 小機沒有完全報錯具體槽位,只報錯了大概的位置。
解決方法:裝置下電,更換兩個 I/O DCA,然後裝置開機,問題解決。
由社群會員“shizhe1030”分享
13
X86 史上最離譜的宕機事件
硬體: IBM的X3650 作業系統: suse 9
linux 系統無法遠端登陸,用 KVM 登入上去看發現定在作業系統頁面不能動。
重啟作業系統後,在作業系統 message 日誌裡面檢視到如下錯誤:

經過諮詢 novell 和 IBM 工程師,結論是 IBM 這類伺服器在裝 linux 系統的時候,如果光碟機有問題確實是會導致宕機。
經硬體工程師檢查,是光碟機壞了……壞了……
編者按:宕機原因千萬種,這個宕機有點冤
由社群會員“hp_hp”分享
本文轉載自公眾號: talkwithtrend

●本文編號132,以後想閱讀這篇文章直接輸入132即可
●輸入m獲取文章目錄

Linux學習
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
